机器学习中模型融合的方法
1、基础方式
1.1 投票
对于分类问题,可以选择票数多的那个分类项作为最终的结果。
2.2 平均
对多个回归模型的结果进行加权平均。
2、具体方式
2.1 Bagging
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。
流程
(1)重复K次
有放回地重复抽样建模
训练子模型
(2)模型融合
分类问题:投票
回归问题:平均
实例
随机森林就是基于Bagging算法的一个典型例子,采用的基分类器是决策树。
2.2 Boosting
Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
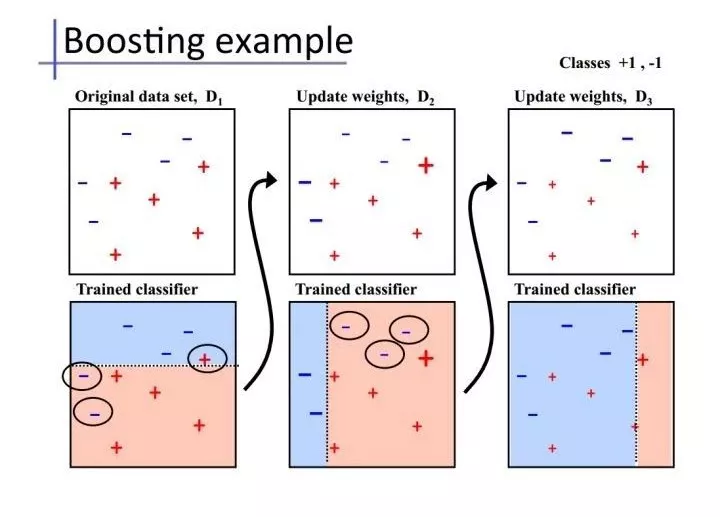
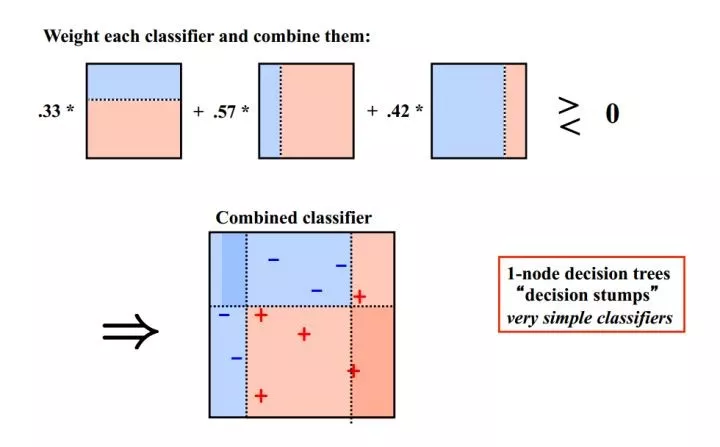
实例
AdaBoost、GBDT
2.3 Stacking
以2级Stacking为例,以下是一个二级Stacking过程。第一级是多个模型M1_n(交叉)训练并(交叉)预测,得到一组预测值(包括训练集和测试集)。这一组的训练集作为第二层的模型M2的输入,进行训练。M4再对M1_n新生成的测试集进行预测。
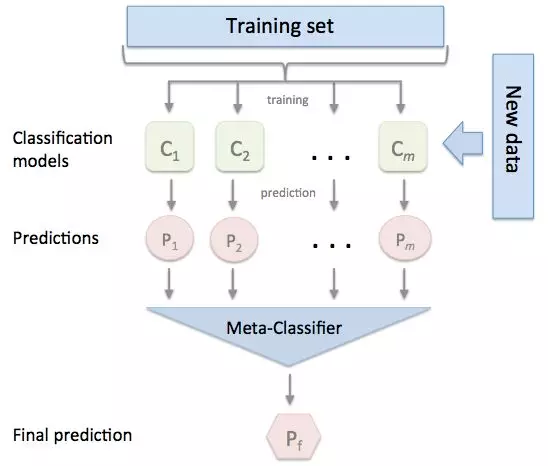
2.3.1 Stacking思想
1.基模型M1,对训练集train训练,然后用于预测train和test的标签列(预测结果),分别是P1,T1
![[P1,T1]](/images/posts/2019-2-19-Model-Fusion/P1T1.webp)
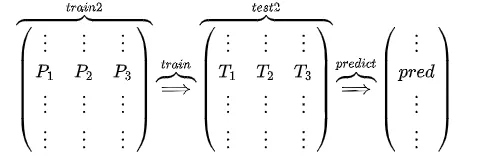
对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3。
2.分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2.
![[P1,P2,P3],[T1,T2,T3]](/images/posts/2019-2-19-Model-Fusion/catPT.webp)
3.再用第二层的模型M4训练train2,预测test2,得到最终的标签列。
2.3.2 Stacking改进
问题
P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,毫无疑问过拟合是非常非常严重的。
解决(K折交叉验证)
1.K折交叉验证即将训练集划分为K等分
2.循环K次(训练一个基模型,并预测)
2.1 基模型选择K-1份作为训练集,1份作为测试集
2.2 基模型对K-1份子训练集组成的训练集进行训练
2.3 基模型预测剩余的1份训练集
5折交叉验证实例
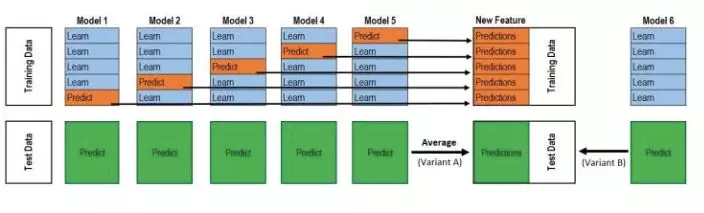
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次(得到五个参数不同的基模型M1-5),拼接得到P1,测试集分别用训练出来的模型M1-5预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。
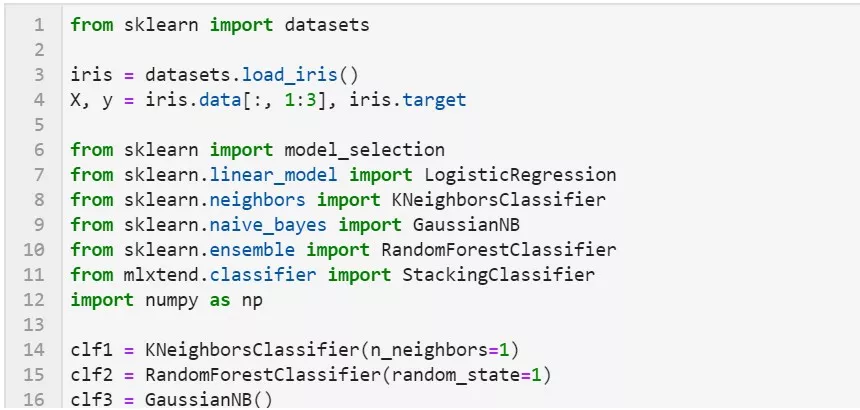
2.3.3 mlxtend库
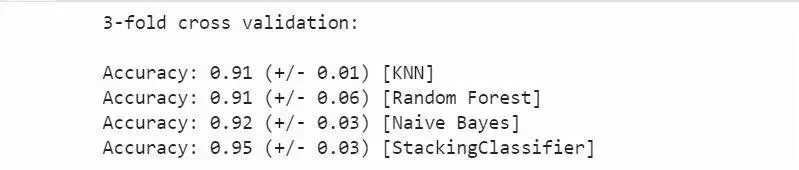
可以很快地完成对sklearn模型stacking。
基本使用
使用前面分类器产生的特征输出作为最后总的meta-classifier的输入数据

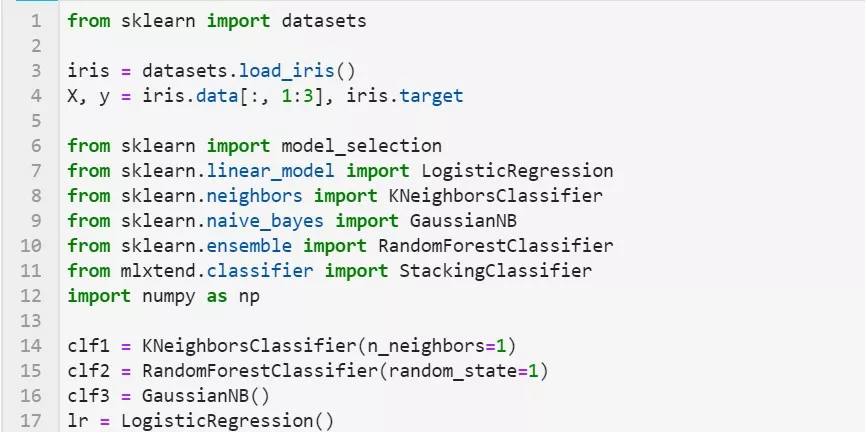
使用第一层基本分类器产生的类别概率值作为meta-classfier的输入
这种情况下需要将StackingClassifier的参数设置为 use_probas=True。如果将参数设置为 average_probas=True,那么这些基分类器对每一个类别产生的概率值会被平均,否则会拼接。
例如有两个基分类器产生的概率输出为:
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
产生的meta-feature 为:[0.25, 0.45, 0.35]
2) average = False:
产生的meta-feature为:[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]


特征维度
这次不是给每一个基分类器全部的特征,而是给不同的基分类器分不同的特征,即比如基分类器1训练前半部分特征,基分类器2训练后半部分特征(可以通过sklearn 的pipelines 实现)。最终通过StackingClassifier组合起来。
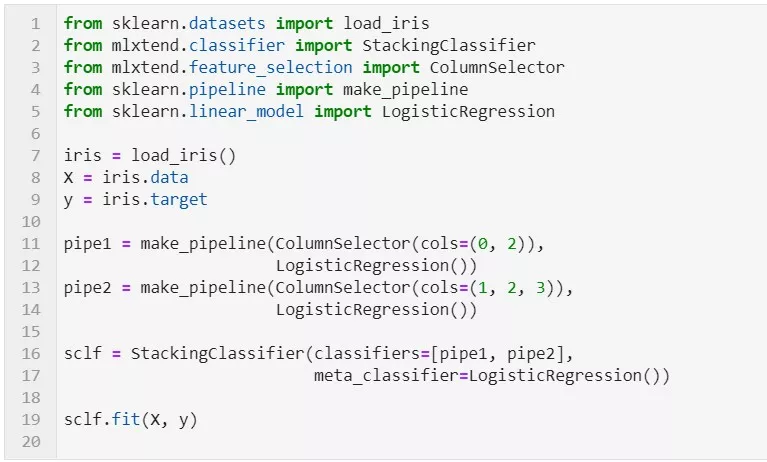

StackingClassifier类API解析
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
- 参数
lassifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
- 属性
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性。
- 方法
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的 GridSearch方法,那么返回分类器的各项参数。 predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样。
欢迎关注我的微信公众号
互联网矿工
