时间序列数据库介绍,包括HBase、Druid、InfluxDB、Beringei等
1.时间序列数据库介绍
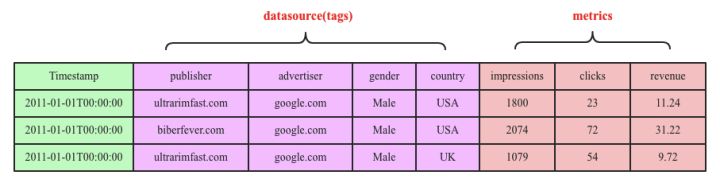
典型的时间序列数据库由两个维度坐标表示,横坐标表示时间,纵坐标由数据源(datasource)和metric组成。
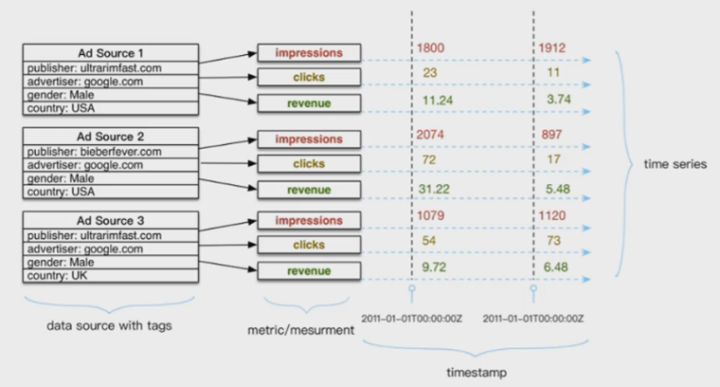
数据源由publisher、advertiser、gender和country四个维度(标签,tags)值唯一表示,metric表示收集的数据源指标(impressions、clicks以及revenue)。一个时间序列点point由datasource(tags)+metric+timestamp唯一确定。
以下几个典型的时间序列数据库介绍。
2.OpenTSDB(HBase)
2.1 介绍
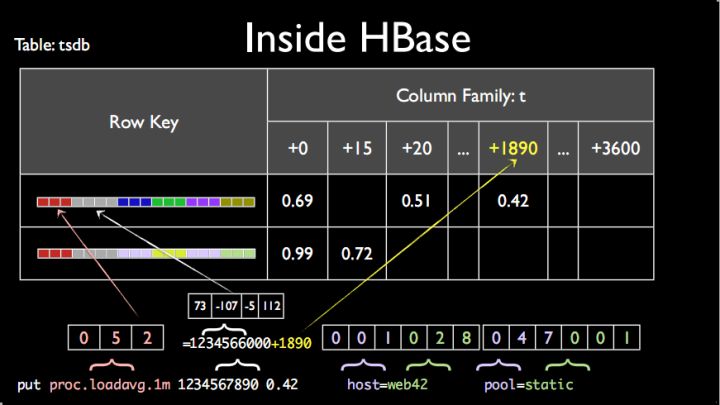
OpenTSDB基于HBase,RowKey规则为:metric+timestamp+datasource(tags)。HBase是一个KV数据库,其中键K为metric+timestamp+datasource(tags),而值V为时间序列点point数值。
2.2 确定rowkey的顺序
-
首位
metric,因为HBase中一张表的数据组织方式是按照rowkey的字典序顺序排列的,希望同一指标数据集中放在一起。
如果timestamp放在首位,同一时刻的不同数据写入同一个数据分片,无法起到散列的效果(难以通过哈希值搜索?)。
如果datasource放在首位,而本身包括多个标签,如果用户指定其中部分标签查找,而不是前缀标签的话,在HBase里面将会变成大范围过滤查询。
-
次位
timestamp
-
末位
datasource,放最后一位,防止出现大范围过滤查询。
2.3 HBase的问题
HBase通过包含多个坐标的K来唯一确定一个point,造成以下问题:
问题一:存在很多无用的字段。一个KeyValue中只有rowkey是有用的,其他字段诸如columnfamily、column、timestamp以及keytype从理论上来讲都没有任何实际意义,但在HBase的存储体系里都必须存在,因而耗费了很大的存储成本。
问题二:数据源和采集指标冗余。KeyValue中rowkey等于metric+timestamp+datasource,试想同一个数据源的同一个采集指标,随着时间的流逝不断吐出采集数据,这些数据理论上共用同一个数据源(datasource)和采集指标(metric),但在HBase的这套存储体系下,共用是无法体现的,因此存在大量的数据冗余,主要是数据源冗余以及采集指标冗余。
问题三:无法有效的压缩。HBase提供了块级别的压缩算法-snappy、gzip等,这些通用压缩算法并没有针对时序数据进行设置,压缩效率比较低。HBase同样提供了一些编码算法,比如FastDiff等等,可以起到一定的压缩效果,但是效果并不佳。效果不佳的主要原因是HBase没有数据类型的概念,没有schema的概念,不能针对特定数据类型进行特定编码,只能选择通用的编码,效果可想而知。
问题四:不能完全保证多维查询能力。HBase本身没有schema,目前没有实现倒排索引机制,所有查询必须指定metric、timestamp以及完整的tags或者前缀tags进行查询,对于后缀维度查询也勉为其难。
2.4 OpenTSDB优化
优化一:timestamp并不是想象中细粒度到秒级或毫秒级,而是精确到小时级别,然后将小时中每一秒设置到列上。这样一行就会有3600列,每一列表示一小时的一秒。这样设置据说可以有效的取出一小时整的数据。
优化二:所有metrics以及所有标签信息(tags)都使用了全局编码将标签值编码成更短的bit,减少rowkey的存储数据量。上文分析HBase这种存储方式的弊端是说道会存在大量的数据源(tags)冗余以及指标(metric)冗余,有冗余是吧,那我就搞个编码,将string编码成bit,尽最大努力减少冗余。虽说这样的全局编码可以有效降低数据的存储量,但是因为全局编码字典需要存储在内存中,因此在很多时候(海量标签值),字典所需内存都会非常之大。
3.Druid
3.1 介绍
Druid是一个列式存储系统。
3.2 Druid的优势
1.数据压缩率高
每列独立存储,可以针对每列进行压缩,也可根据不同的列采取不同的压缩策略。
2.支持多维查找
Druid为datasource的每个列分别设置了Bitmap索引,利用Bitmap索引可以有效实现多维查找,比如用户想查找20110101T00:00:00这个时间点所有发布在USA的所有广告的浏览量,可以根据country=USA在Bitmap索引中找到要找的行号,再根据行号定位待查的metrics。
3.3 Druid的问题
问题一:数据依然存在冗余。和OpenTSDB一样,tags存在大量的冗余。
问题二:指定数据源的范围查找并没有OpenTSDB高效。这是因为Druid会将数据源拆开成多个标签,每个标签都走Bitmap索引,再最后使用与操作找到满足条件的行号,这个过程需要一定的开销。而OpenTSDB中直接可以根据数据源拼成rowkey,查找走B+树索引,效率必然会更高。
4.InfluxDB
4.1 介绍
和以上HBase、Druid相同,采用LSM结构,数据先写入内存,当内存到达一定阈值后flush到文件。InfluxDB只存储数据,可以对时序数据做非常多的优化工作。
InfluxDB中有一个seriesKey概念,即datasourc(tags)+metric,时序数据写入内存后按照seriesKey进行组织:

以上看出,InfluxDB的存储结构实际是一个map:<seriesKey, List<timestamp,value>>。内存中的数据flush的文件后,同样会将同一个seriesKey中的时间线数据写入同一个Block块内,即一个Block块内的数据都属于同一个数据源下的一个metric。
4.2 InfluxDB优势
好处一:同一数据源的tags不再冗余存储。一个Block内的数据都共用一个SeriesKey,只需要将这个SeriesKey写入这个Block的Trailer部分就可以。大大降低了时序数据的存储量。
好处二:时间序列和value可以在同一个Block内分开独立存储,独立存储就可以对时间列以及数值列分别进行压缩。InfluxDB对时间列的存储借鉴了Beringei的压缩方式,使用delta-delta压缩方式极大的提高了压缩效率。而对Value的压缩可以针对不同的数据类型采用相同的压缩效率。
好处三:对于给定数据源以及时间范围的数据查找,可以非常高效的进行查找。这一点和OpenTSDB一样。
5.Beringei
5.1 Beringei介绍
Beringei是google开源的一个时间序列数据库,模型设计类似InfluxDB,其相对于InfluxDB增加了在内存中对数据压缩的功能。
InfluxDB在写入内存的时候没有压缩,而是在数据写入文件的时候进行对应压缩。而时间序列数据存在最新数据最热的特点,存放在内存中可以大大提升效率。
5.2 Beringei和InfluxDB的区别
-
文件组织形式不同。Beringei的文件存储形式按照时间窗口组织,比如最近5分钟的数据全部写入同一个文件,这个文件分为很多block,每个block中的所有时序数据共用一个SeriesKey。Beringei文件没有索引,InfluxDB有索引。
-
Beringei目前没有倒排索引机制,因此对于多维查询并不高效。
参考
https://sq.163yun.com/blog/article/169864634071179264
欢迎关注我的微信公众号
互联网矿工
