IoTDB的数据模型、存储引擎。
0.名词解释
-
物理量
Measurement,IoTDB的最基本的数据点,类似于InfluxDB的时间线概念。
-
逻辑存储组
Storage Group,对应到数据库(Database)。
-
实体
Entity,也叫设备,可以包含多个物理量。
-
标签
Tag,用于对物理量进行标记,可用于快速批量搜索等场景。
1.数据模型
IoTDB按照路径组织物理量,以下图为例,可以通过 root.ln.wf01.wt01.status唯一定位到一个物理量。
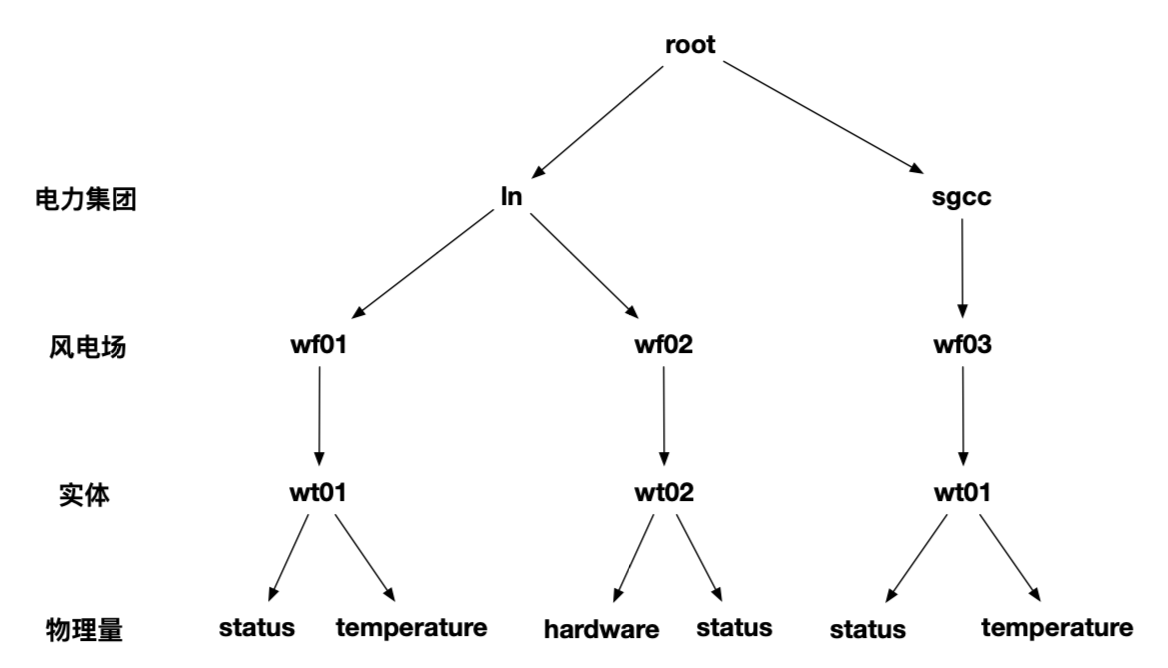
路径第一级为root,系统默认创建。路径第二级为数据库名,在存储概念中也称为逻辑存储组。存储路径倒数第二级表示实体,可以包含多个物理量。最后一级表示物理量。
物理量的标签在物理量创建时设置,可以修改,但同一个物理量的标签是固定的。我们都知道InfluxDB中标签作为时间线的标识一部分。意味着改变标签后,InfluxDB将会新建时间线,而非原时间线。很多人滥用标签,比如将TraceID放入到标签,造成了时间线快速膨胀,早晨性能问题。我认为TraceID这类不断变化的数据并不适合放到标签中。不管是InfluxDB还是IoTDB,这种做法必然破坏时序数据库的设计理念,造成创建大量的时间线,进而引发时间线膨胀问题。当然IoTDB本身就不支持为每个数据值设置标签。
“为每个数据设置标签”和“高压缩率/高速写入/大数据量”这两种能力本身是矛盾的。“为每个数据设置标签”往往是为了快速找到一些数据,必然需要为这些数据创建标签的索引。时序数据库的大数据量特点是一个根本的场景,也是从关系型数据库发展而来的基本需求。“为每个数据设置标签”的实现可能让时序数据回到关系型数据库的问题——索引极速膨胀,甚至超过数据本身。与此同时,时序数据高速写入的情况下,还需要管理标签的索引、标签的存储,大大加大CPU和IO资源压力。此外,时序数据库的“高压缩率”能力必将导致时序数据的编码/合并/压缩,伴随着数据大规模的搬迁。数据大规模的搬迁会让标签索引管理应接不暇。所以说,标签和物理量绑定的设计是正确的,也是妥协的产物。
IoTDB支持创建模板,能够做到快速实例化实体。模板支持创建、挂载、激活、解绑、删除等方式。
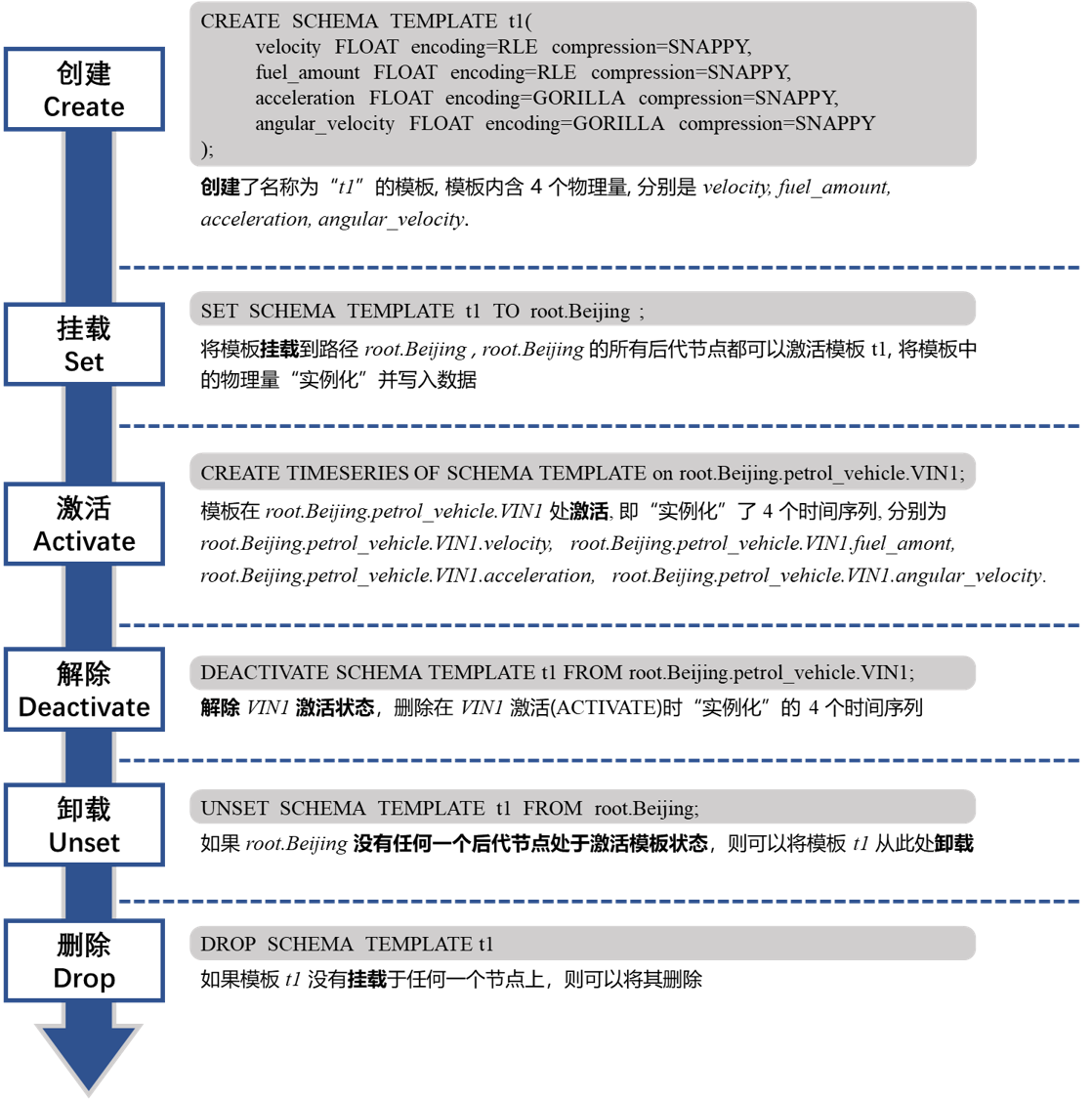
这里有一个问题,如果想要修改某个实体的模板,是做不到的。但实际的场景中,施工会出现频繁而持续的模板改动,甚至不同的实体会分化到不同的模板下。在系统维护节点,偶尔也会改动模板。如果需要改动模板,则需要将原来的实体删除,造成所有数据丢失。用户不得已进行数据的备份和恢复工作。
2.存储
下方是一个典型的数据文件存储结构。
.
├── consensus
│ ├── data_region
│ │ └── 1_1
│ │ └── configuration.dat
│ └── schema_region
│ └── 47474747-4747-4747-4747-000200000000
│ ├── current
│ │ ├── log_inprogress_0
│ │ ├── raft-meta
│ │ └── raft-meta.conf
│ ├── in_use.lock
│ └── sm
├── data
│ ├── sequence
│ │ └── root.ln // 数据库
│ │ └── 1 // DataRegionId,由实体path hash得到
│ │ └── 0 // 时间分区
│ │ ├── 1672106890628-1-0-0.tsfile // 数据
│ │ ├── 1672106890628-1-0-0.tsfile.mods // 数据修改记录
│ │ └── 1672106890628-1-0-0.tsfile.resource // 数据概述
│ └── unsequence
│ └── root.ln
│ └── 1
│ └── 0
│ ├── 1672107062990-2-0-0.tsfile
│ ├── 1672107062990-2-0-0.tsfile.mods
│ └── 1672107062990-2-0-0.tsfile.resource
├── system
│ ├── compression_ratio
│ │ └── Ratio-2.940341-2 // 压缩率信息
│ ├── databases
│ │ └── root.ln
│ │ └── 1
│ │ └── upgrade
│ │ └── Version-100
│ ├── roles
│ ├── schema
│ │ ├── root.ln
│ │ │ └── 0
│ │ │ └── tlog.txt // tag信息
│ │ └── system.properties
│ ├── udf
│ │ └── tmp
│ ├── upgrade
│ │ └── upgrade.txt
│ └── users
│ └── root.profile
└── wal
└── root.ln-1
├── _0.checkpoint
└── _2-31-1.wal
consensus目录是用于集群见保证数据一致性的。IoTDB底层基于RAFT实现数据一致性。
data目录是时序数据的存储目录,分为顺序sequence和乱序unsequence。IoTDB会为每个物理量维护顺序sequence的最新时间戳,如果新数据早于该时间戳,则认为是乱序的,需要将数据保存到乱序unsequence目录下。这么做的原因是IoTDB的特点(也是所有时序数据库的特点,具体可以看LSM树)决定的,即数据先缓存再批量刷盘。下图是IoTDB数据上报-缓存-刷盘-合并等过程的示意图。
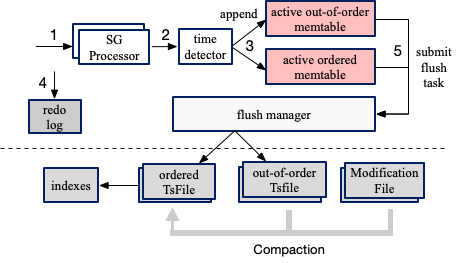
为了提高数据写入速度,IoTDB会先数据缓存到内存也就是memtable。memtable达到一定的大小后,会将不同的时序数据组织成一条一条、按照时间排序的连续存储块(Chunk,每个Chunk下有多个存储页Page)批量刷入磁盘。在这个过程中会进行编码(比如二阶查分编码TS_2DIFF、游程编码RLE、字典编码DICTIONARY等)、压缩(比如SNAPPY压缩、LZ4压缩、GZIP压缩等)。Page的大小会限制在一定数据量,比如100个数据带你,是IoTDB编解码、压解缩的单位。回到“如果新数据早于该时间戳,则认为是乱序的,需要将数据保存到乱序unsequence目录下”的问题。如果允许乱序的数据立刻插入顺序sequence文件中,则需要定位到对应的Page,将其解压缩、解码、插入数据、编码、压缩并重新写入磁盘,搬迁所在的Chunk后其他数据并重新组织Chunk的索引。在上述过程中,会消耗较多的CPU和IO资源。
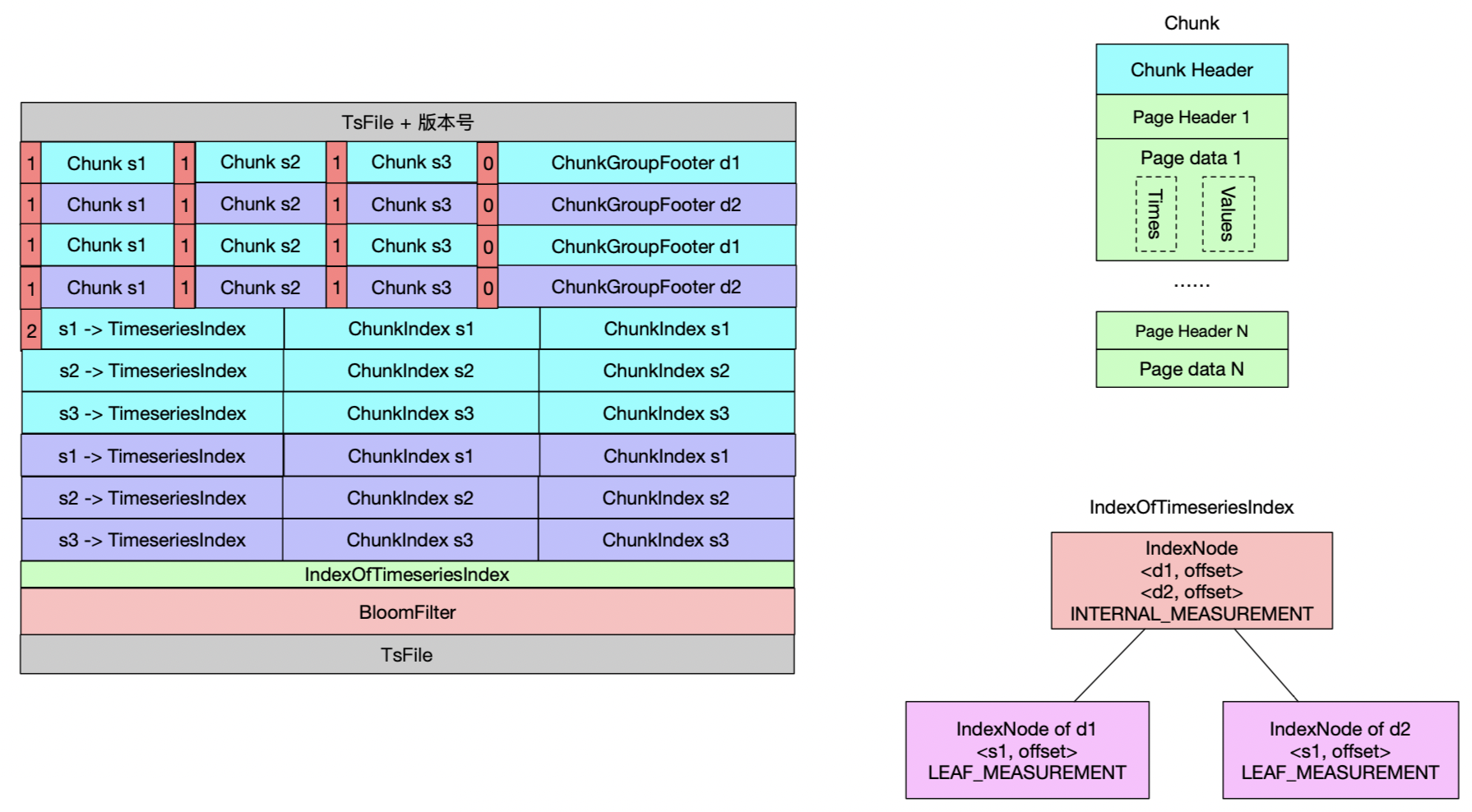
编码/压缩算法会根据历史数据进行学习,提高压缩率。所以为了进一步提高压缩率,IoTDB会将不同的文件进行合并,防止同一个物理量的数据无序/零散分布在不同的文件。与此同时,也会将乱序unsequence的数据合并到顺序sequence中。乱序和顺序合并后,也会在一定程度上提高查询效率。不然,我们可想而知,查询引擎需要在两个目录下都搜索一遍。
在data的sequence或unsequnce目录下,按照数据库/DataRegion/时间分区的层级关系组织。DataRegion主要用于负载均衡,由实体的路径经过Hash得到。时间分区默认7天创建一个。时间分区的目录名表示自Unix时间0开始,7天的倍数。在每个时间分区下分为TsFile、Resource文件、Mods文件等。如果在合并期间刷盘,会增加携带“compaction”的文件,而不会立刻合并在其他的文件中。TsFile即上图,文件名按照{创建文件的时间}-{文件粒度版本号}-{内部合并次数}-{乱序合并次数}.tsfile的歌是。其中文件粒度版本号在每次新增一个TsFile都会增加1。Resource文件是TsFile的概述文件,包括时间索引信息、RAFT日志、墓碑文件路径等。
data目录是存储存储引擎的核心,需要考虑时间线膨胀、高压缩率、高速写入、高速读取(比如通过统计信息)、删除、更新、顺序/乱序、保留策略等诸多问题。从IoTDB的功能对比和性能测试结果看,压缩率、读写速度都很优秀。压缩率通过编码和压缩两个过程提升。用户可以根据自行选择每个物理量的编码和压缩算法。其中读取数据的速度通过Page块的统计信息、Bloom过滤器等方式提升。
| TSDB | IoTDB | InfluxDB | OpenTSDB | KairosDB | TimescaleDB |
|---|---|---|---|---|---|
| Align by time | ++ | + | - | - | + |
| Compression(压缩率) | ++ | +- | +- | +- | +- |
| MQTT support | ++ | + | - | - | +- |
| Run on Edge-side Device | ++ | + | - | +- | + |
| Multi-instance Sync | ++ | - | - | - | - |
| JDBC Driver | + | - | - | - | ++ |
| Standard SQL | + | - | - | - | ++ |
| Spark integration | ++ | - | - | - | - |
| Hive integration | ++ | - | - | - | - |
| Writing data to NFS (HDFS) | ++ | - | + | - | - |
| Flink integration | ++ | - | - | - | - |
| TSDB | IoTDB | InfluxDB | KairosDB | TimescaleDB |
|---|---|---|---|---|
| Scalable Writes | ++ | + | + | + |
| Raw Data Query | ++ | + | + | + |
| Aggregation Query | ++ | + | + | + |
| Downsampling Query | ++ | + | +- | +- |
| Latest Query | ++ | + | +- | + |
删除、更新、顺序/乱序问题的处理过程和数据顺序刷盘过程解耦,看着很清晰。如果用过TDengine的话,会了解到有一个last文件的概念。主要用于在多表少频(点位多,点位数据产生慢)的情况下,将同一个超级表下的同类型数据放在一起,提高压缩率。IoTDB是否会出现多表低频下压缩率低的情况呢?我认为在初期也会出现的,只是随着合并的不断发生,会大大减轻这种情况。如果时间分区的时间窗口越小,越可能出现这种问题。
system目录是系统配置、标签、压缩率等信息。
wal目录是write-ahead-log。由于LSM内存先行的特点,可能出现数据丢失。wal目录用于保存所有的操作日志,方便在启动时恢复数据。这也是LSM树的基本操作。
3.演进与展望
IoTDB有较多值得我们学习的地方,也有一些问题,值得我们去展望和改进。
值得我们学习的是(前文可能没有提到,可以前往IoTDB官网查看详细描述):
-
统计信息提升查询效率
-
统计memtable的大小,通过丢弃的方式防止OOM,提升稳定性
-
顺序/乱序数据分开处理,插入/修改数据过程分开处理,逻辑清晰,支撑高速写入
-
实体模板绑定和解绑,提升实例化效率
-
标签不作为时间线的标记,而是元数据的标记,防止标签被滥用
-
不同物理量可以共用时间线,提高压缩率
-
正在考虑和评估将索引和数据分开,索引支持B+树
模块 子模块及作用 在TsFile外部缺点 在TsFile外部优点 IndexOfTimeseriesIndex 时间序列索引的索引(二级索引) 系统管理文件数会翻倍读写打开文件数会翻倍 索引文件可以灵活修改,不影响数据文件;支持一个数据文件对应多索引文件;读取索引内容无需跳过数据区,磁盘定位快 BloomFilter 针对序列的布隆过滤 -
Chunk中的Page Header连续存储,而不是和Data混合
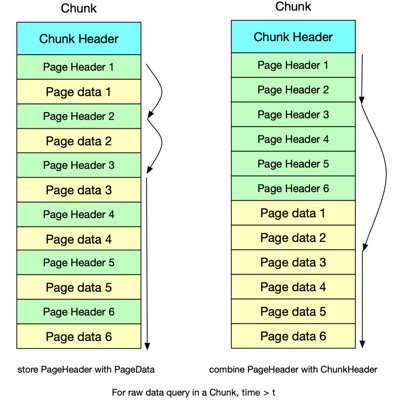
-
区分编码和压缩
展望和改进:
-
实体模板不支持对一个实体重复绑定、修改和解绑
如果能够支持模板绑定后自动识别和原模型的区别,并处理差异,将会大大方便某些场景。比如在工业场景下,用户为很多设备(实体)定义了模板,但是需要对其中一些设备进行修改,其余的不变。用户可以直接创建一个新的模板,绑定到对应的设备上,自动识别差异。在这个过程中能保留未删除的数据,标记删除的数据,同时创建新增的数据。
-
数据保留时间为数据库级别
不能像InfluxDB一样做到时间线级别的数据保留管理。这个和InfluxDB的存储结构有关——RP为顶层的目录,RP下数据的保留时间相同,所以InfluxDB可以快速删除文件,而不需要提取文件中的某些数据进行删除。这也引入了问题,数据的RP改变后,数据就查不到了。用户需要自行实现数据迁移。
IoTDB采用独立后台进程维护数据保留任务,在发现一个文件的数据超过期限,即可将文件直接删除。因为只支持到数据库级别的数据保留策略,所以也不需要判断哪些物理量可以删除。
两个方案的选择要看具体的场景,不可一概而论哪个更好。
4.参考
欢迎关注我的微信公众号
互联网矿工
