本笔记只记录重点,完整内容见原书。
1.卓有成效的程序员
本书提出方法,提高程序员的工作效率。
1.1 自动化法则
-
建立本地缓存
wget --mirror -w 2 --html-extension --convert-links -P /home/scc/example/参数 作用 --mirror(-m)给网站建立本地镜像 -w(--wait)重新尝试的间隔秒 --html-extension把文件拓展名改为html --convert-links把页面上所有的链接转为本地链接 -P保存网站镜像的本地目录 -
自动访问网站
curl "www.neyzoter.cn/app/query?date=2020&num=10" # 通过POST来和资源交互 curl -d "date=2020&num=10" www.neyzoter.cn/app/query参数 作用 -d(--data)HTTP POST data -
在构建之外使用Ant
Ant可以实现打包前,将无关文件清理掉。
<!--clean-all 方法--> <target name="clean-all" depends="init"> <delete verbose="true" includeEmptyDirs="true"> <fileset dir="${clean.dir}"> <include name ="**/*.war" /> <include name ="**/*.ear" /> <include name ="**/*.jar" /> <containsregexp expression=".*~$"/> </fileset> </delete> <delete verbose="true" includeEmptyDirs="true"> <fileset dir="${clean.dir}" defaultexcludes="no"> <patternset refid="generated-dirs" /> </fileset> </delete> </target>打包
<!--打包样例,需要依赖clean-all--> <target name="zip-samples" depends="clean-all"> <delete file="${class-zip-name}" /> <echo message="You file name is ${class-zip-name}" /> <zip destfile="${class-zip-name}.zip" basedir="." compress="true" excludes="*.xml,*.zip,*.cmd" /> </target> -
用Rake执行常见任务
Rake是Ruby的make工具,能够与操作系统轻松交互,比如可以使用Rake快速打开几个文件。
-
使用Selenium浏览网页
Selenium是一个开源的测试工具,用于Web应用程序的用户验收测试。Selenium借助JS自动化了浏览器操作,从而可以模拟用户的行为。Selenium IDE是一个FireFox的插件,可以记录浏览器操作,不需要测试人员每次都要进行重复的操作。
-
使用bash统计异常数
#!/bin/bash # 遍历所有ERROR,排序,消除重复 for X in $(egrep -o "[A-Z]\w*Exception" log.txt | sort | uniq); do # 异常输出到控制台上 echo -n -e "$X " # 统计个数 grep -c "$X" log.txt done -
别给牦牛剪毛
别让自动化的努力变成剪牦牛毛——指的是如果在写自动化脚本的时候,发现了很多其他无关的问题,比如版本不兼容、驱动有问题等,需要尽快抽身,而不是不停解决以上无关的问题。
1.2 哲学
-
事物本质性质和附属性质(亚力士多德)
本质复杂性是指要解决问题的核心,而附属复杂性是值在解决核心问题时,可能需要附属解决的问题。比如为了分析某个数据库数据,需要连接数据库并导出数据,导出数据的过程即为附属性质而分析数据库才是本质性质。很多组织会在附属性质上花费比本质性质更多的时间和精力。
所以,去除本质复杂性,也要去除附属复杂性。
-
奥卡姆剃刀原理
如果对于一个现象有多种解释,那么最简单的往往是最正确的。
“80-10-10”准则(Dietzler定律)是指80%的客户需求可以很快完成,下一个10%需要花很大努力完成,而最后10%几乎不可能完成,因为不想将所有工具和框架都“招致麾下”。
一些语言的诞生是为了让程序员摆脱一些麻烦,但随着时间推移,可能语言的功能越来越多,然而使得解决方案变得不正确(不符合奥卡姆剃刀原理)。
所以,适合的才是最好的,不要总是追求样样精通。
-
笛米特法则
任何对象都不需要知道与之交互的那个对象的任何内部细节。
比如,下面的方法是不合适的,
Job job = new Job("Safety Engineer", 5000.00); Person homer = new person("Homer", job); // 通过Person来获取Job,直接操作Job对象是不合适的 homer.getJob().setPosition("Janitor");正确的做法应该是在Person类中定义可以更改Position的方法
// 正确的做法应该是在Person类中定义可以更改Position的方法 homer.changeJobPositionTo("Janitor");
1.3 多语言编程
计算机语言会越来越细分领域,追求通用性的语言会被抛弃。
2. TCP-IP详解卷1:协议
第17章 TCP:传输控制协议
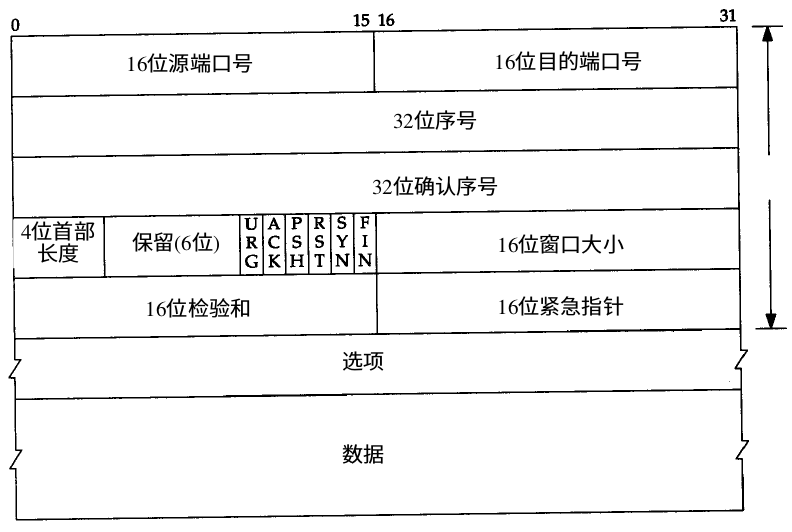
+------------------------+-------------------------------+-----------------------------+
| IP首部 | TCP首部 | TCP数据 |
+------------------------+-------------------------------+-----------------------------+
20 bytes 20 bytes
-
TCP首部的6个标志比特
URG:紧急指针有效
ACK:确认序号有效
PSH:接收方应该尽快将这个报文段交给应用层
RST:重建连接
SYN:同步序号用来发起一个连接
FIN:发端完成发送任务
-
序号
序号用来计数数据的字节数,到达最大后,重新从0开始计数。
-
确认序号
ACK也即对应确认需要,每次发送一个包即增加1。
-
窗口大小
窗口大小是在接收方的TCP帧头中指定的。在后期更新前,发送方最多发送窗口大小这么多的数据。见TCP/IP协议20.4节。
-
16位校验和
校验报文段是否在传输过程中出现了问题,如果有问题,接收端会通过发送ACK+N,使发送端重新发送。
-
16位紧急指针
只有当URG标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。见TCP/IP协议20.8节中。
-
选项
- 最长报文大小MMS,每个连接方通常在通信的第一个报文段(为建立连接而设置 S Y N标志的那个段)中指明这个选项。指明本端所能接收的最大长度的报文段。见TCP/IP协议18.4节。
第18章 TCP连接的建立与终止
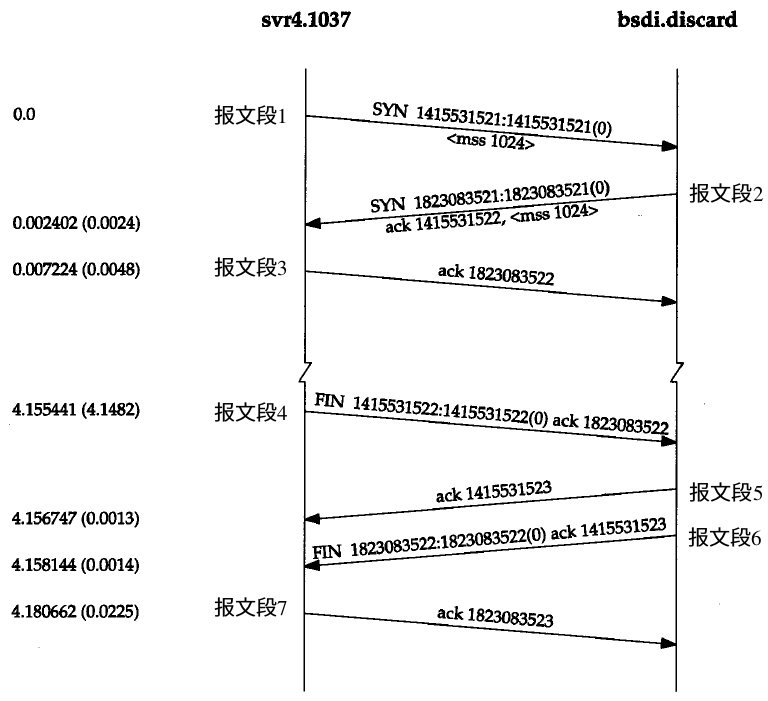
以下是TCP的三次握手和四次挥手过程:
-
连接终止协议
终止连接需要4次握手,有TCP的半关闭(Half-Close)造成的。一个TCP连接是全双工(两个方向上同时传递),因此每个方向必须单独进行关闭。这一原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止该方向的连接。当一端接受到一个FIN,它必须通知应用层另一端已经终止了那个方向的数据传输(也就是FIN的ack)。
第20章 TCP的成块数据流
滑动窗口协议是一种流量控制方法。协议允许发送方在停止并等待确认前可以连续发送多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。
-
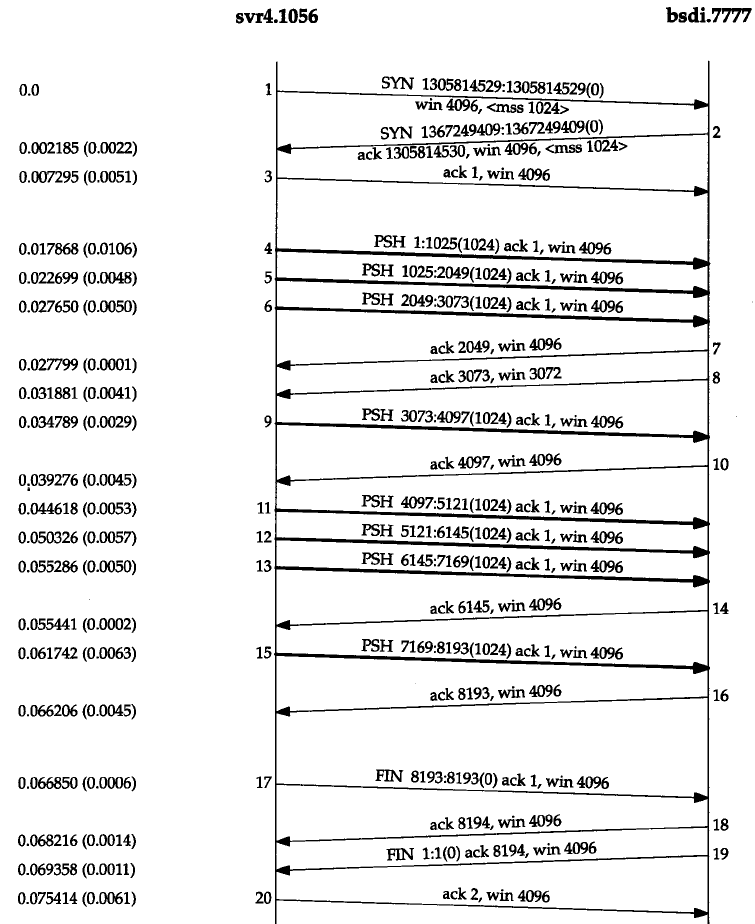
滑动窗口
窗口大小是在接收方的TCP帧头中指定的。在后期更新前,发送方最多发送窗口大小这么多的数据。下面是一个数据通信过程,
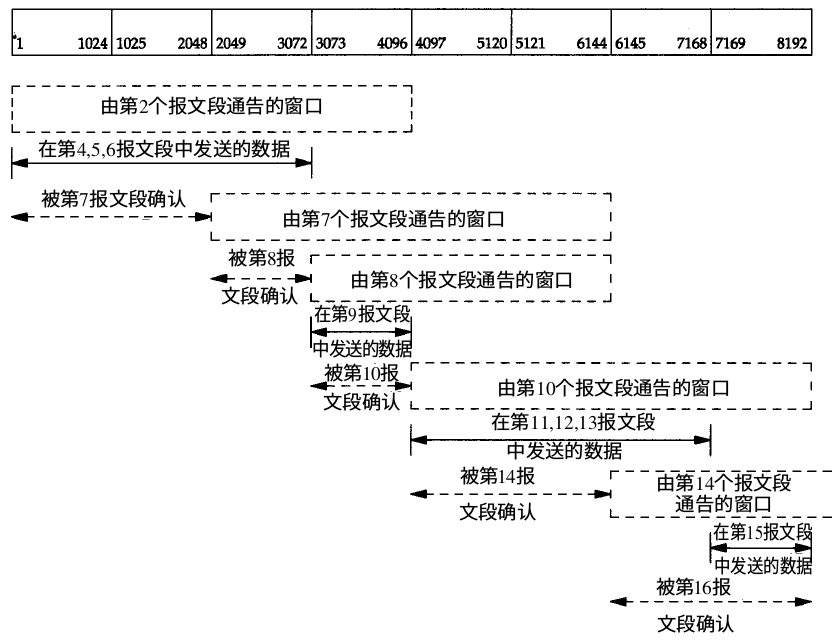
下面是滑动窗口的展示图,
-
慢启动
慢启动算法通过观察到新分组进入网络的速率应该与另一端返回确认的速率相同而进行工作。慢启动为发送方的 T C P增加了另一个窗口:拥塞窗口 (congestion window)。发送端每收到一个ACK,拥塞窗口就增加一个报文段。发送方取拥塞窗口与通告窗口中的最小值作为发送上限。拥塞窗口(已经发送的)是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制。
3. 大型分布式网站架构设计与实践
通过服务(SOA系统)的方式进行交互,保证交互的标准性;
采用可水平伸缩的集群方式来支撑巨大的访问量,设计到负载均衡问题;
通过分布式缓存解决大量的数据缓存问题;
通过监控、恢复措施提高系统的稳定性;
3.1 面向服务的体系架构(SOA)
3.1.1 基于TCP协议的RPC
RPC:远程过程调用。
-
对象的序列化
数据需要转化为二进制流在网络上传输,涉及到对象的序列化和反序列化问题。解决方案包括Google的Protocal Buffer、Java自带的序列化方式、Hessian、JSON、XML、Spark的Kryo。下面是一个Java序列化的例子,
public class SerializationUtil implements Serializable { private static final long serialVersionUID = 1065846828160869484L; public static byte[] serialize(Object obj) throws Exception{ ByteArrayOutputStream baos = null; ObjectOutputStream oos = null; try{ // create byte array output stream baos = new ByteArrayOutputStream(); // create obj output stream, write into baos oos = new ObjectOutputStream(baos); // write obj into baos oos.writeObject(obj); // trans to byte[] byte[] bytes = baos.toByteArray(); oos.close(); return bytes; }catch (Exception e){ throw e; } } public static Object deserialize(byte[] bytes){ ByteArrayInputStream bais = null; Object tmpObject = null; try { // trans to ByteArrayInputStream bais = new ByteArrayInputStream(bytes); // trans to obj InputStream ObjectInputStream ois = new ObjectInputStream(bais); // trans to obj tmpObject = (Object)ois.readObject(); ois.close(); return tmpObject; } catch (Exception e) { e.printStackTrace(); } return null; } } -
基于TCP的RPC简单实现
- 服务(接口)和实现类
/** * RPC 服务接口 * @author Charles Song * @date 2020-4-19 */ public interface RpcService { String printString (String str) ; } /** * RPC服务实现 */ public class RpcServiceImpl implements RpcService{ @Override public String printString (String str) { System.out.println(str); return str; } }- 服务提供者
/** * RPC 服务提供者 * @author Charles Song * @date 2020-4-19 */ public class RpcProvider { public static final int PORT = 5000; public static void main (String[] args) { // 创建保存服务实现类的对象 HashMap<String, Object> servicesImpl = new HashMap<>(10); // 加入RpcService接口实现RpcServiceImpl servicesImpl.put(RpcService.class.getName(), new RpcServiceImpl()); try{ ServerSocket serverSocket = new ServerSocket(PORT); System.out.println("Waiting for RPC..."); while (true) { Socket socket = serverSocket.accept(); ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream()); // 获取接口名称 String ifName = objectInputStream.readUTF(); System.out.println("Interface Name : " + ifName); // 获取方法名称 String methodName = objectInputStream.readUTF(); System.out.println("Method Name : " + methodName); // 获取方法参数类型 Class<?>[] methodArgClass = (Class<?>[]) objectInputStream.readObject(); // 获取方法的参数 Object[] arguments = (Object[]) objectInputStream.readObject(); // 获取接口 Class serviceIfClass = Class.forName(ifName); // 获取接口的实现 Object serviceImpl = servicesImpl.get(ifName); // 获取方法 Method method = serviceIfClass.getMethod(methodName, methodArgClass); // 调用函数methodArgClass Object result = method.invoke(serviceImpl, arguments); // 将结果发送给消费者 ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream()); objectOutputStream.writeObject(result); } } catch (Exception e) { System.err.println(e); } } }- 服务消费者
/** * RPC 服务使用者 * @author Charles Song * @date 2020-4-19 */ public class RpcConsumer { public static void main (String[] args) { try { String ifName = RpcService.class.getName(); Method method = RpcService.class.getMethod("printString", String.class); String methodName = method.getName(); Class[] methodArgClass = method.getParameterTypes(); Object[] arguments = {"Msg Received..."}; Socket socket = new Socket("127.0.0.1", RpcProvider.PORT); ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream()); // 接口名称 objectOutputStream.writeUTF(ifName); // 方法名称 objectOutputStream.writeUTF(methodName); // 方法参数类型 objectOutputStream.writeObject(methodArgClass); // 方法参数 objectOutputStream.writeObject(arguments); ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream()); Object result = objectInputStream.readObject(); System.out.println("result = " + (String)result); } catch (Exception e) { System.out.println(e); } } }运行结果:
## 服务提供者 Waiting for RPC... Interface Name : cn.neyzoter.oj.test.rpc.RpcService Method Name : printString Msg Received... ## 服务消费者 result = Msg Received...
3.1.2 基于HTTP协议RPC
服务消费者在HTTP的URL中加入要调用的服务名称、服务参数等信息,服务提供者根据服务名称从Map中获取服务实现对象,进而执行。
-
JSON和XML
对象可以通过JSON和XML工具类转化为字符串流。
Person person = new Person(); // jackson 的ObjectMapper可以将对象转化为JSON ObjectMapper = new ObjectMapper(); StringWriter sw = new StringWriter(); JsonGenerator gen = new JsonFactory().createJsonGenerator(sw); mapper.writeValue(gen, person); gen.close;
3.1.3 服务的路由和负载均衡
公共业务被拆分,形成共用的服务,最大程度保证代码和逻辑的复用,这种设计称为SOA(Service-Oriented Architecture)。服务消费者通过路由可以找到对应的服务地址列表。负载较高的服务,可以通过负载均衡策略,将服务请求发送到集群中的其中一个节点来执行。
+-------------------+ +------------+
| service1 | | addr1 |
| service2 | | addr2 |
consumer ---> | service3 | ---> | addr3 |
| service4 | | addr4 |
| service5 | +------------+
+-------------------+
服务路由 地址列表
当服务越来越多,集群规模变大,人工维护成本大,路由/负载均衡压力变大,容易出现单点故障。比如下图中,单个路由查询服务集群,负载均衡算法将请求指向到某一个服务器上。
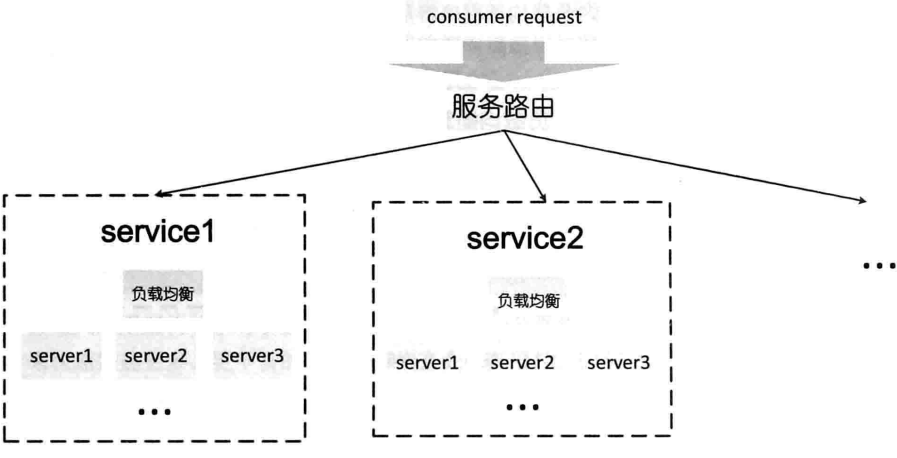
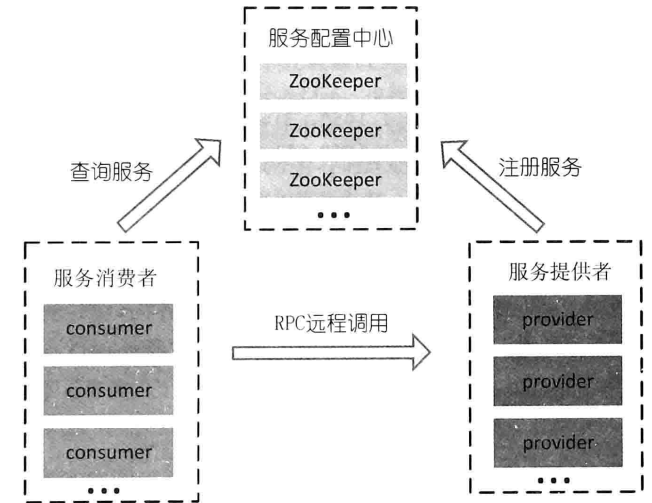
服务配置中心,一个动态注册和获取服务的地方来统一管理服务名称和对应的服务器列表信息。服务提供者启动时,将其提供的服务名称、服务器地址注册到服务配置中心,服务消费者通过服务配置中心来获得需要调用的服务的机器列表,通过相应的负载均衡算法,选取其中的一台服务器进行调用。服务器宕机或者下线时,机器需要动态从服务配置中心里面移除,并通知服务消费者。因为为了提高效率,服务消费者会将服务和机器地址缓存在本地。这种无中心化的结构解决了之前负载均衡设备所导致的单点故障问题,并大大减轻了服务配置中心的压力。ZooKeeper可以作为服务配置中心的实现,
3.4 系统稳定性
3.4.1 监控指标
集群指标包括:系统负载、CPU使用率、IO繁忙程度、网络拥堵情况、内存利用率、应用心跳等。
-
系统负载load
特定时间间隔内运行队列中的平均线程数。
# 获取load,这个load是多个核共同的load,平均负载需要处以核的个数 $ uptime 18:52:16 up 8:09, 1 user, load average: 0.59, 0.58, 0.69 -
CPU利用率
# 获取CPU利用率 $ top | grep Cpu # 用户时间 系统时间 Nice时间 空闲时间 等待时间 硬件中断处理时间 软件中断处理时间 丢失时间 # 用户时间,CPU执行用户进程占用的时间 # 系统时间,CPU内核态占用的时间 # Nice时间,系统调度进程优先级的时间 # 空闲时间,系统处于空闲状态 # 等待时间,CPU等待IO操作的时间 # 硬件中断时间,系统处理硬件中断的时间 # 软件中断时间,系统处理软件终端的时间 # 丢失时间,强制等待虚拟CPU的时间(虚拟化服务) %Cpu(s): 8.0 us, 1.5 sy, 0.0 ni, 90.2 id, 0.1 wa, 0.0 hi, 0.2 si, 0.0 st可以按
1来得到所有CPU单独的使用率情况。 -
磁盘剩余空间
$ df -h Filesystem Size Used Avail Use% Mounted on udev 7.8G 0 7.8G 0% /dev tmpfs 1.6G 9.6M 1.6G 1% /run /dev/nvme0n1p7 29G 21G 5.9G 78% / tmpfs 7.8G 189M 7.6G 3% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup -
网络拥堵情况
# -n : 回报网络情况 # DEV : 查看各个网卡的情况 # 第一个1 : 每1秒采样1次 # 第二个1 : 总共采样1次 $ sar -n DEV 1 1 # lo表示本地回环网络 # docker0表示docker # enp3s0表示网卡 # rxpck/s : 接收的数据包个数 # txpck/s : 发送的数据包个数 # rxkB/s : 接收的数据字节数 # txkB/s : 发送的数据字节数 # rxcmp/s : 接收到的压缩包数量 # txcmp/s : 发送的压缩包数量 # rxmcst/s : 每秒收到的广播包的数量 # Average : 采样平均值 Linux 4.15.0-96-generic (neyzoter) 2020年04月22日 _x86_64_ (8 CPU) 19时12分41秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 19时12分42秒 lo 25.00 25.00 3.91 3.91 0.00 0.00 0.00 0.00 19时12分42秒 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 19时12分42秒 enp3s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil Average: lo 25.00 25.00 3.91 3.91 0.00 0.00 0.00 0.00 Average: docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: enp3s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 -
磁盘IO
磁盘IO繁忙度反映了系统负载情况
## -d 仅显示磁盘统计信息.与-c选项互斥. ## -k 以K为单位显示每秒的磁盘请求数,默认单位块. $ iostat -d -k # tps : 每秒处理的IO请求数 # kB_read/s : 每秒读 # kB_wrtn/s : 每秒写 # kB_read : 读总量 # kB_wrtn : 写总量 Linux 4.15.0-96-generic (neyzoter) 2020年04月22日 _x86_64_ (8 CPU) Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn loop0 0.00 0.00 0.00 12 0 nvme0n1 14.82 107.94 201.57 3368298 6289637 sda 0.06 2.44 5.34 76250 166712 -
内存使用
通过free可以查看内存和交换区使用情况
# -g : GB $ free -m # total : 总内存 # used : 已经使用的内存 # free : 未使用的内存 # shared : 多个进程共享的内存空间大小 # buff/cache : 缓存大小 # available : 可使用的大小 # Mem : 内存 # Swap : 交换区 total used free shared buff/cache available Mem: 15937 6117 2844 1011 6974 8344 Swap: 15624 0 15624通过vmstat可以查看交换区的详细使用情况
$ vmstat # si : 每秒从磁盘交换到内存的数据量, KB/s # s0 : 每秒从内存交换到磁盘的数据量, KB/s procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 2886424 997720 6139968 0 0 24 45 261 243 8 2 90 0 0 -
qps(query per second)
每秒查询数。qps超过阈值,需要对集群扩容,以应对高请求。
-
rt(response time)
请求响应时间。可以通过Ngnix的访问日志,得到每个请求的响应时间。
-
数据库操作ps
select/ps: 每秒处理select的数量;update/ps:每秒处理update的数量;delete/ps:每秒处理delete的数量。
欢迎关注我的微信公众号
互联网矿工
