1.Flink介绍
概述
Apache Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。由于流处理和批处理所提供的SLA(服务等级协议)是完全不相同, 流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。比较典型的有:实现批处理的开源方案有MapReduce、Spark;实现流处理的开源方案有Storm;Spark的Streaming 其实本质上也是微批处理。
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
特性
- 有状态计算的Exactly-once语义。状态是指flink能够维护数据在时序上的聚类和聚合,同时它的checkpoint机制
- 支持带有事件时间(event time)语义的流处理和窗口处理。事件时间的语义使流计算的结果更加精确,尤其在事件到达无序或者延迟的情况下。
- 支持高度灵活的窗口(window)操作。支持基于time、count、session,以及data-driven的窗口操作,能很好的对现实环境中的创建的数据进行建模。
- 轻量的容错处理( fault tolerance)。 它使得系统既能保持高的吞吐率又能保证exactly-once的一致性。通过轻量的state snapshots实现
- 支持高吞吐、低延迟、高性能的流处理
- 支持savepoints 机制(一般手动触发)。即可以将应用的运行状态保存下来;在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间。
- 支持大规模的集群模式,支持yarn、Mesos。可运行在成千上万的节点上
- 支持具有Backpressure功能的持续流模型
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果进行缓存
API支持
- DataStream API
- DataSet API
- Table API
- Streaming SQL
Libs支持
- 支持复杂事件处理(CEP)
- 支持机器学习(FlinkML)
- 支持图分析处理(Gelly)
- 支持关系数据处理(Table)
整体组件栈
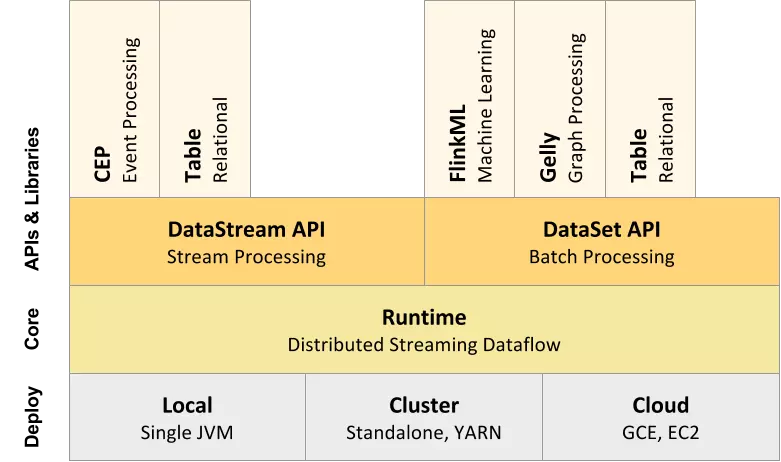
Deployment层: 该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN),(GCE/EC2)。
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层: 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)
应用场景
-
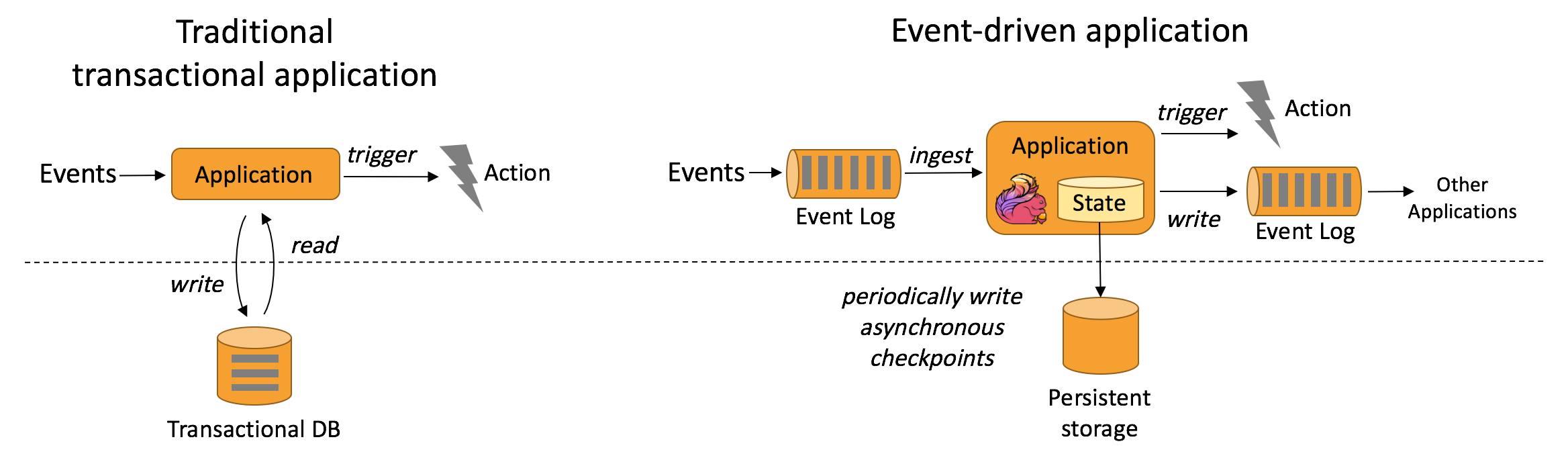
事件驱动型应用
在传统架构中,应用需要读写远程事务型数据库(图中左侧)。事件驱动型应用(图中右侧)是基于状态化流处理来完成,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。
-
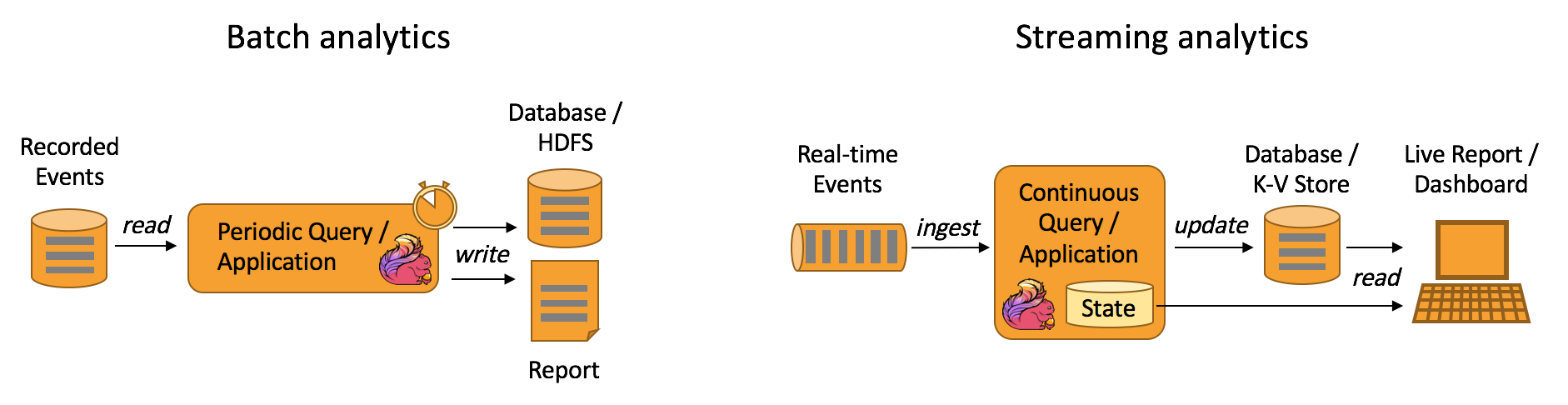
数据分析应用
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。
-
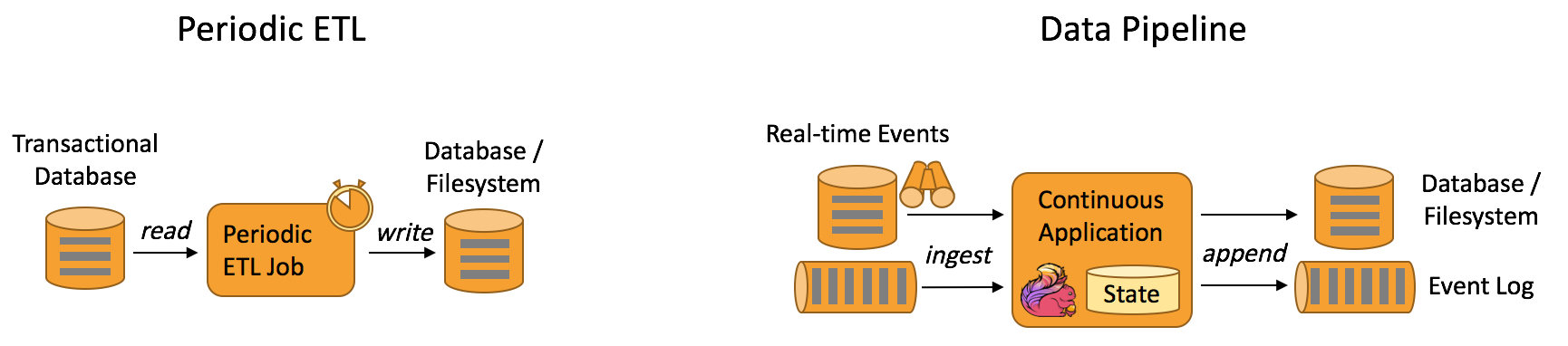
数据管道应用
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
欢迎关注我的微信公众号
互联网矿工
