1、介绍
本笔记包含大数据框架——hadoop。
2、Hadoop基础
2.1 介绍
目的
提高处理速度。
方法
把数据分到多块硬盘,然后同时读取。代码向数据迁移,避免大规模数据时,造成大量数据迁移的情况,尽量让一段数据的计算发生在同一台机器上。
关键技术
1.数据分布在多台机器
可靠性:每个数据块都复制到多个节点
性能:多个节点同时处理数据
2.计算随数据走
网络IO速度 « 本地磁盘IO速度,大数据系统会尽量地将任务分配到离数据最近的机器上运行(程序运行时,将程序及其依赖包都复制到数据所在的机器运行)
代码向数据迁移,避免大规模数据时,造成大量数据迁移的情况,尽量让一段数据的计算发生在同一台机器上
3.串行IO取代随机IO
传输时间 « 寻道时间,一般数据写入后不再修改
适合场景
大规模数据
流式数据(写一次,读多次)
商用硬件(一般硬件)
不适合场景
低延时的数据访问
大量的小文件
频繁修改文件(基本就是写1次)
hadoop框架
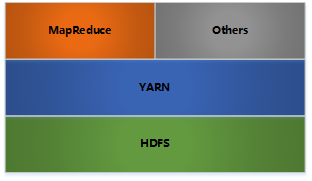
- HDFS: 分布式文件存储——提供对应用程序数据的高吞吐量访问
- YARN: 分布式资源管理——用于作业调度和集群资源管理的框架
- MapReduce: 分布式计算——基于YARN的用于并行处理大数据集的系统
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
2.2 HDFS
Hadoop Distributed File System,分布式文件系统
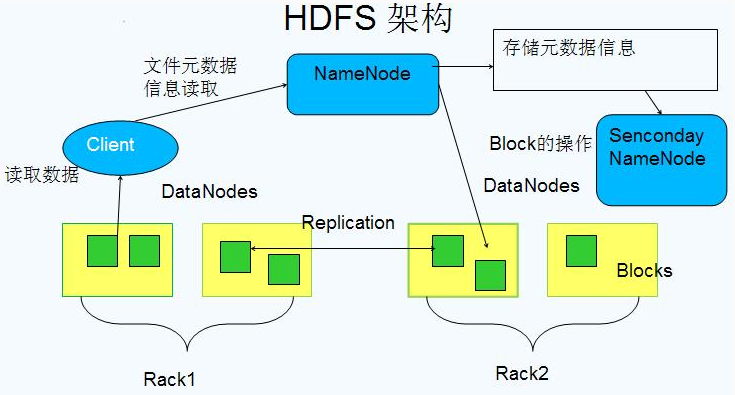
2.2.1 Block数据(黄色)
基本存储单位,一般大小为64M配置大的块主要是因为:(1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)
一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
基本的读写位,类似于磁盘的页,每次都是读写一个块
每个块都会被复制到多台机器,默认复制3份
2.2.2 NameNode
1、存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
2、一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
3、数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
4、NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
2.2.3 Secondary NameNode
定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机
2.2.4 DataNode
1、保存具体的block数据
2、负责数据的读写操作和复制操作
3、DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
4、DataNode之间会进行通信,复制数据块,保证数据的冗余性
2.2.5 Rack
Rack表示机架,一个机架内的计算机通信速率一般大于跨越不同机架的计算机通信。
2.3 YARN
2.3.1 旧的MapReduce架构
组件
- JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker: 加载或关闭任务,定时报告认为状态
![]()
旧的MapReduce架构问题(单点问题和资源利用率问题):
- JobTracker是MapReduce的集中处理点,存在单点故障
- JobTracker完成了太多的任务,造成了过多的资源消耗,当MapReduce job 非常多的时候,会造成很大的内存开销。这也是业界普遍总结出老Hadoop的MapReduce只能支持4000 节点主机的上限
- 在TaskTracker端,以map/reduce task的数目作为资&##x6E90;的表示过于简单,没有考虑到cpu/ 内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OOM
- 在TaskTracker端,把资源强制划分为map task slot和reduce task slot, 如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费,也就集群资源利用的问题
2.3.2 YARN组件
YARN就是将JobTracker的职责进行拆分,将资源管理(ResourceManager)和任务调度监控(Application Master)拆分成独立的进程。
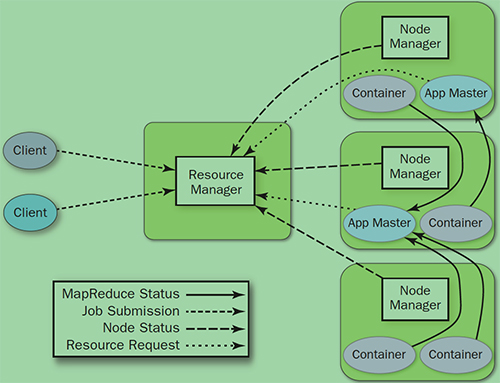
YARN架构下形成了一个通用的资源管理平台(Platform)和一个通用的应用计算平台(Application Framework),避免了旧架构的单点问题和资源利用率问题,同时也让在其上运行的应用不再局限于MapReduce形式
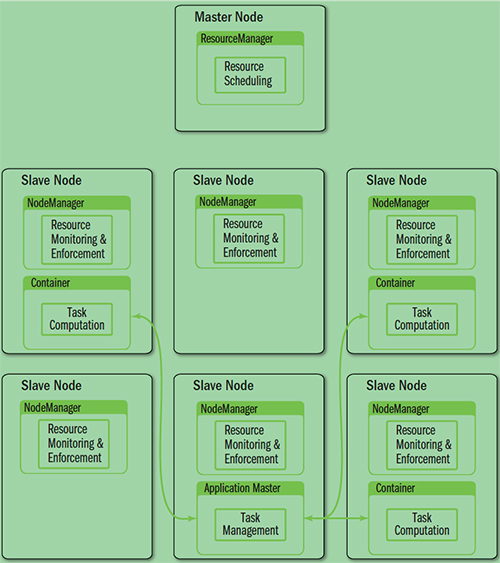
- ResourceManager
全局资源管理和任务调度——提供了计算资源的分配和管理
- NodeManager
单个节点的资源管理和监控——提供了计算资源的分配和管理
- ApplicationMaster
单个作业的资源管理和任务监控——完成应用程序的运行
- Container
资源申请的单位和任务运行的容器
Hadoop1(JobTracker)和Hadoop2(YARN)的区别。
![]()
2.3.3 YARN处理流程
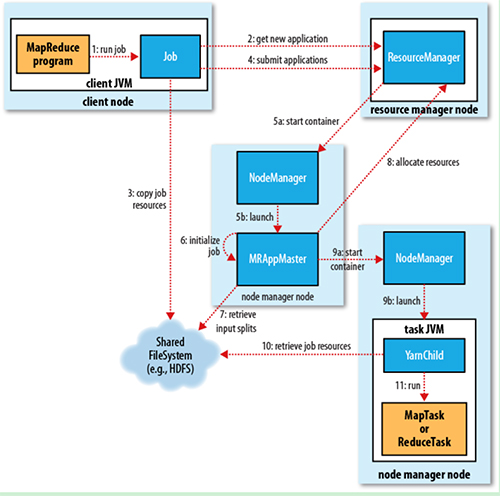
1. Job submission
从ResourceManager中获取一个Application ID检查作业输出配置,计算输入分片拷贝作业资源(job jar、配置文件、分片信息)到HDFS,以便后面任务的执行
2. Job initialization
ResourceManager将作业递交给Scheduler(有很多调度算法,一般是根据优先级)Scheduler为作业分配一个Container,ResourceManager就加载一个application master process并交给NodeManager管理ApplicationMaster主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个Map task和相应的reduce task Application Master还决定如何运行作业,如果作业很小(可配置),则直接在同一个JVM下运行
3. Task assignment
ApplicationMaster向Resource Manager申请资源(一个个的Container,指定任务分配的资源要求)一般是根据data locality来分配资源
4. Task execution
ApplicationMaster根据ResourceManager的分配情况,在对应的NodeManager中启动Container 从HDFS读取任务所需资源(job jar,配置文件等),然后执行该任务
5. Progress and status update
定时将任务的进度和状态报告给ApplicationMaster Client定时向ApplicationMaster获取整个任务的进度和状态
6. Job completion
Client定时检查整个作业是否完成 作业完成后,会清空临时文件、目录等
2.4 MapReduce
一种分布式的计算方式指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
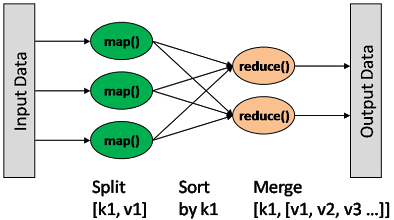
2.4.1 MapReduce读取数据
流程:通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit(作用:代表一个个逻辑分片,并没有真正存储数据,只是提供了一个如何将数据分片的方法,包含分片数据的位置、split的大小等信息),每个InputSplit对应一个Map处理,RecordReader(作用:将InputSplit拆分成一个个<key,value>对给Map处理,也是实际的文件读取分隔对象</key,value>)读取InputSplit的内容给Map
类结构
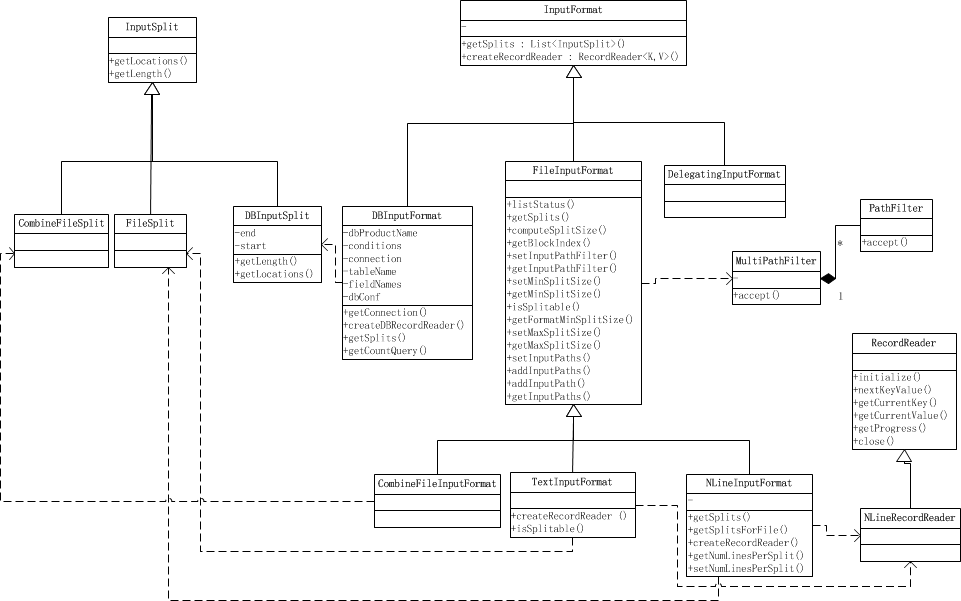
List getSplits():获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题
RecordReader <k,v>createRecordReader():</k,v> 创建RecordReader,从InputSplit中读取数据,解决读取分片中数据问题
InputFormat功能
1.验证作业输入的正确性,如格式等
2.将输入文件切割成逻辑分片(InputSplit),一个InputSplit将会被分配给一个独立的Map任务
3.提供RecordReader实现,读取InputSplit中的”K-V对”供Mapper使用
InputFormat类型
BaileyBorweinPlouffe.BbInputFormat
ComposableInputFormat
CompositeInputFormat
DBInputFormat
DistSum.Machine.AbstractInputFormat
FileInputFormat
FileInputFormat数据类型
1.TextInputFormat: 输入文件中的每一行就是一个记录,Key是这一行的byte offset,而value是这一行的内容
2.KeyValueTextInputFormat: 输入文件中每一行就是一个记录,第一个分隔符字符切分每行。在分隔符字符之前的内容为Key,在之后的为Value。分隔符变量通过key.value.separator.in.input.line变量设置,默认为(\t)字符。
3.NLineInputFormat: 与TextInputFormat一样,但每个数据块必须保证有且只有N行,mapred.line.input.format.linespermap属性,默认为1
4.SequenceFileInputFormat: 一个用来读取字符流数据的InputFormat,<key,value>为用户自定义的。字符流数据是Hadoop自定义的压缩的二进制数据格式。它用来优化从一个MapReduce任务的输出到另一个MapReduce任务的输入之间的数据传输过程。</key,value>
5.
问题
1.大量小文件如何处理?
CombineFileInputFormat可以将若干个Split打包成一个,目的是避免过多的Map任务
2.怎么计算split的?
- 分割方法
(1)通常一个split就是一个block(FileInputFormat仅仅拆分比block大的文件)
这样做的好处是使得Map可以在存储有当前数据的节点上运行本地的任务,而不需要通过网络进行跨节点的任务调度
(2)通过mapred.min.split.size, mapred.max.split.size, block.size来控制拆分的大小
如果mapred.min.split.size大于block size,则会将两个block合成到一个split,这样有部分block数据需要通过网络读取
如果mapred.max.split.size小于block size,则会将一个block拆成多个split,增加了Map任务数(Map对split进行计算且上报结果,关闭当前计算打开新的split均需要耗费资源)
- 具体流程
先获取文件在HDFS上的路径和Block信息,然后根据splitSize对文件进行切分( splitSize = computeSplitSize(blockSize, minSize, maxSize) ),默认splitSize 就等于blockSize的默认值(64m)
3.分片间的数据如何处理?
split是根据文件大小分割的,而一般处理是根据分隔符进行分割的,这样势必存在一条记录横跨两个split。

解决办法是只要不是第一个split,都会远程读取一条记录,作为最后一个数据,并忽略到第一条记录
2.4.2 MapReduce Mapper
主要是读取InputSplit的每一个Key,Value对并进行处理
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* 预处理,仅在map task启动时运行一次
*/
protected void setup(Context context) throws IOException, InterruptedException {
}
/**
* 对于InputSplit中的每一对<key, value>都会运行一次
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* 扫尾工作,比如关闭流等
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
}
/**
* map task的驱动器
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
public class MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends TaskInputOutputContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
private RecordReader<KEYIN, VALUEIN> reader;
private InputSplit split;
/**
* Get the input split for this map.
*/
public InputSplit getInputSplit() {
return split;
}
@Override
public KEYIN getCurrentKey() throws IOException, InterruptedException {
return reader.getCurrentKey();
}
@Override
public VALUEIN getCurrentValue() throws IOException, InterruptedException {
return reader.getCurrentValue();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
return reader.nextKeyValue();
}
}
2.4.3 MapReduce Shuffle
作用:对Map的结果进行排序并传输到Reduce进行处理。
Map的结果并不直接存放到硬盘,而是利用缓存做一些预排序处理。Map会调用Combiner,压缩,按key进行分区、排序等,尽量减少结果的大小。每个Map完成后都会通知Task,然后Reduce就可以进行处理。
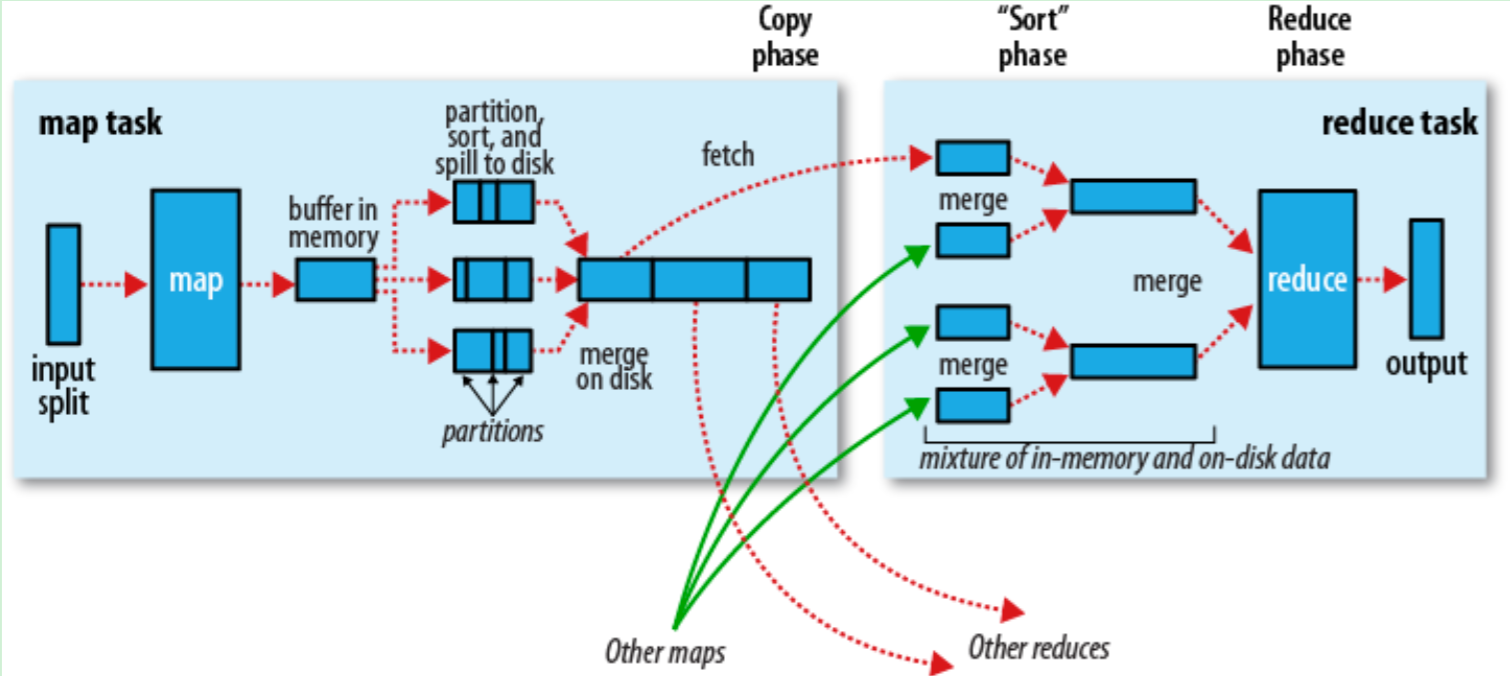
Map端
当Map程序开始产生结果的时候,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map任务可以继续输出结果,但如果缓冲区满了,Map任务则需要等待
写文件使用round-robin方式。在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)
每次结果达到缓冲区的阀值时,都会创建一个文件,在Map结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序。如果文件的数量超过3个,则并后会再次运行Combiner(1、2个文件就没有必要了)
如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
一旦Map完成,则通知任务管理器,此时Reduce就可以开始复制结果数据
Reduce端
Map的结果文件都存放到运行Map任务的机器的本地硬盘中
如果Map的结果很少,则直接放到内存,否则写入文件中
同时后台线程将这些文件进行合并和排序到一个更大的文件中(如果文件是压缩的则需要先解压)
当所有的Map结果都被复制和合并后,就会调用Reduce方法
Reduce结果会写入到HDFS中
调优
一般的原则是给shuffle分配尽可能多的内存,但前提是要保证Map、Reduce任务有足够的内存
对于Map,主要就是避免把文件写入磁盘,例如使用Combiner,增大io.sort.mb的值
对于Reduce,主要是把Map的结果尽可能地保存到内存中,同样也是要避免把中间结果写入磁盘。默认情况下,所有的内存都是分配给Reduce方法的,如果Reduce方法不怎么消耗内存,可以mapred.inmem.merge.threshold设成0,mapred.job.reduce.input.buffer.percent设成1.0
在任务监控中可通过Spilled records counter来监控写入磁盘的数,但这个值是包括map和reduce的
对于IO方面,可以Map的结果可以使用压缩,同时增大buffer size(io.file.buffer.size,默认4kb)
| 属性 | 默认值 | 描述 |
|---|---|---|
| io.sort.mb | 100 | 映射输出分类时所使用缓冲区的大小. |
| io.sort.record.percent | 0.05 | 剩余空间用于映射输出自身记录.在1.X发布后去除此属性.随机代码用于使用映射所有内存并记录信息. |
| io.sort.spill.percent | 0.80 | 针对映射输出内存缓冲和记录索引的阈值使用比例. |
| io.sort.factor | 10 | 文件分类时合并流的最大数量。此属性也用于reduce。通常把数字设为100. |
| min.num.spills.for.combine | 3 | 组合运行所需最小溢出文件数目. |
| mapred.compress.map.output | false | 压缩映射输出. |
| mapred.map.output.compression.codec | DefaultCodec | 映射输出所需的压缩解编码器. |
| mapred.reduce.parallel.copies | 5 | 用于向reducer传送映射输出的线程数目. |
| mapred.reduce.copy.backoff | 300 | 时间的最大数量,以秒为单位,这段时间内若reducer失败则会反复尝试传输 |
| io.sort.factor | 10 | 组合运行所需最大溢出文件数目. |
| mapred.job.shuffle.input.buffer.percent | 0.70 | 随机复制阶段映射输出缓冲器的堆栈大小比例 |
| mapred.job.shuffle.merge.percent | 0.66 | 用于启动合并输出进程和磁盘传输的映射输出缓冲器的阀值使用比例 |
| mapred.inmem.merge.threshold | 1000 | 用于启动合并输出和磁盘传输进程的映射输出的阀值数目。小于等于0意味着没有门槛,而溢出行为由 mapred.job.shuffle.merge.percent单独管理. |
| mapred.job.reduce.input.buffer.percent | 0.0 | 用于减少内存映射输出的堆栈大小比例,内存中映射大小不得超出此值。若reducer需要较少内存则可以提高该值. |
2.4.4 MapReduce实例
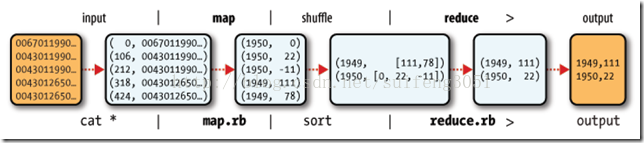
Map阶段的key/value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本,Map阶段的输出的key/value对的格式必须同Reduce阶段的输入key/value对的格式相对应。Map输入:
(0 ,0067011990999991950051507+0000+)
(1 ,0043011990999991950051512+0022+)
(2 ,0043011990999991950051518-0011+)
(3 ,0043012650999991949032412+0111+)
(4 ,0043012650999991949032418+0078+)
(5 ,0067011990999991937051507+0001+)
(6 ,0043011990999991937051512-0002+)
(7 ,0043011990999991945051518+0001+)
(8 ,0043012650999991945032412+0002+)
(9 ,0043012650999991945032418+0078+)
将上面的数据作为用户编写的map函数的输入,通过对每一行字符串的解析,得到年/温度的key/value对作为输出
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
(1937, 1)
(1937, -2)
(1945, 1)
(1945, 2)
(1945, 78)
shuffle过程,将map过程中的输出,按照相同的key将value放到同一个列表中作为用户写的reduce函数的输入
(1950, [0, 22, –11])
(1949, [111, 78])
(1937, [1, -2])
(1945, [1, 2, 78])
Reduce过程中,在列表中选择出最大的温度,将年/最大温度的key/value作为输出
(1950, 22)
(1949, 111)
(1937, 1)
(1945, 78)
2.5 安装和使用
单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
2.5.1 前期准备
单节点安装
所有服务运行在一个JVM中,适合调试、单元测试
伪集群
所有服务运行在一台机器中,每个服务都在独立的JVM中,适合做简单、抽样测试
多节点集群
服务运行在不同的机器中,适合生产环境
配置公共帐号
方便主与从进行无密钥通信,主要是使用公钥/私钥机制 所有节点的帐号都一样 在主节点上执行 ssh-keygen -t rsa生成密钥对 复制公钥到每台目标节点中
- 版本说明
Apache Hadoop 3.x now support only Java 8 Apache Hadoop from 2.7.x to 2.x support Java 7 and 8
- 必备Linux软件
$ sudo apt-get install ssh
$ sudo apt-get install pdsh
ssh安装失败的问题解决
如果出现ssh安装失败,
Reading package lists... Done
Building dependency tree
Reading state information... Done
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
ssh : Depends: openssh-server (>= 1:7.2p2-4)
E: Unable to correct problems, you have held broken packages.
则需要先安装openssh-server,安装时出现问题,
Reading package lists... Done
Building dependency tree
Reading state information... Done
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
openssh-server : Depends: openssh-client (= 1:7.2p2-4)
Depends: openssh-sftp-server but it is not going to be installed
Recommends: ssh-import-id but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
则需要先安装openssh-client=1:7.2p2-4。
sudo apt-get install openssh-client=1:7.2p2-4
sudo apt-get install openssh-server
sudo apt-get install ssh
- Hadoop下载
http://www.apache.org/dyn/closer.cgi/hadoop/common/
比如下载Hadoop3.2.0.tar.gz
- 解压hadoop
tar -zxvf hadoop文件名称.tar.gz
并移动到某一个目录下,如/opt。该目录即为hadoop的安装目录$HADOOP_HOME
2.5.2 安装
1.添加路径
“/opt/hadoop-3.2.0/”可修改。
export HADOOP_HOME=/opt/hadoop-3.2.0/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使该路径生效
source ~/.bashrc
2.配置Hadoop(伪集群安装模式)
其他安装模式:hadoop安装
目录:$HADOOP_HOME/etc/hadoop(非操作系统的/etc)
文件:
(1)etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(2)etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3)etc/hadoop/hadoop-env.sh
java的路径,需要根据自己的机器而定
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
查看hadoop的使用文档:
$ bin/hadoop
2.配置ssh
验证不需要ssh不需要密码
$ ssh localhost
如果以上不可以的话,进行
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
2.5.3 测试
1.进入hadoop安装目录($HADOOP_HOME)
cd /opt/hadoop-3.2.0
2.运行测试指令
(1)输出使用文档
$ bin/hadoop
(2)格式化文件系统
$ bin/hdfs namenode -format
(3)启动NameNode和DataNode守护进程
$ sbin/start-dfs.sh
日志默认在$HADOOP_HOME/logs
(4)浏览器查看Hadoop情况
也许不同的版本的端口9870不一样
(5)HDFS内构建目录
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
<username>:表示用户名
(6)复制要输入的文件到分布式系统中
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
(7)运行给出的例子
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar grep input output 'dfs[a-z.]+'
(8)从分布式系统中输出文件到本地文件系统
$ bin/hdfs dfs -get output output #生成一个output文件夹
$ cat output/* # 列出文件
(9)关闭进程
sbin/stop-dfs.sh
2.5.4 在单个node上的YARN
本小结基于,上面的运行测试指令的(1)-(5)步已经完成,即
$ bin/hadoop
# 格式化文件系统
$ bin/hdfs namenode -format
# 启动hdfs
$ sbin/start-dfs.sh
# 建立目录
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
1.配置文件
均为hadoop安装目录下的文件,
(1)etc/hadoop/mapred-site.xml
这里<configuration> </configuration>为根目录,只能有一个。官方的Hadoop3.2.0安装过程中该文件实例有误。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
(2)etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
2.开始ResourceManager进程和NodeManager进程
$ sbin/start-yarn.sh
3.通过web查看ResourceManager
4.运行一个Mapeduce任务
5.停止进程
$ sbin/stop-yarn.sh
2.5.5 建立和安装Cluster
见《Hadoop实战》的“Hadoop安装与配置”小节。
3、Hadoop实战
3.1 计算文本中的单词数
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
/**
* 字符计数
* @author neyzoter song
* @version 1.0.0
* @since 2019-05-27
*/
public class WordCount {
/**
* Map 方法
*/
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text,
IntWritable> output, Reporter reporter) throws IOException{
String line = value.toString();
//以"空格\t\n\r\f"分割line
StringTokenizer tokenizer = new StringTokenizer(line);
while(tokenizer.hasMoreElements()){
word.set(tokenizer.nextToken());
//输出<word, 1>的格式
output.collect(word, one);
}
}
}
/**
* Reduce方法
*/
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException{
int sum = 0;
while(values.hasNext()){
//get得到values的数目1
sum += values.next().get();
}
//输出<key, 总数目>
output.collect(key, new IntWritable(sum));
}
}
/**
* main
*/
public static void main(String[] args) throws Exception{
String path1 = "./aiot-common/src/test/java/com/neyzoter/aiot/common/test/main/file1";
String path2 = "./aiot-common/src/test/java/com/neyzoter/aiot/common/test/main/output";
//设置WordCount
JobConf conf = new JobConf(WordCount.class);
conf.setJobName(WordCount.class.getName());
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
//TextInputFormat的key是每个数据在数据分片中的字节偏移量
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(path1));
FileOutputFormat.setOutputPath(conf, new Path(path2));
JobClient.runJob(conf);
}
}
(1)InputFormat()和InputSplit
InputSplit是Hadoop定义的用来传送给每个单独的map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。生成InputSplit的方法可以通过InputFormat()来设置。数据传送给map,map会将输入分片传输到InputFormat上,InputFormat则调用getRecodReader()方法生成RecodReader,RecodReader再通过createKey()和createValue()方法创建可供map处理的<key, value>对,即<k1, v1>。
总结:InputFormat()用于生成可供map处理的<key, value>对。
(2)OutputFormat
输出格式任意。上述代码输出
Hello 1
World 2
Bye 2
(3)map和reduce
Map继承自MapReduceBase,并实现了Mapper接口,接口定义了Mapper的输入<k1,v1>和输出<k2,v2>。
Reduce继承自MapReduceBase,并实现了Reducer接口,接口定义了Reducer的输入<k2,v2>和输出<k3,v4>。
(4)运行
欢迎关注我的微信公众号
互联网矿工
