摘自http://kafka.apachecn.org/
1、Kafka介绍
Kafka实现了生产者(收集信息)和消费者(分析信息)之间的无缝衔接,即不同的系统之间如何传递消息,是一种高产出的分布式消息系统(A high-throughput distributed messaging system)。
1.1 Kafka组件
- topic:消息存放的目录即主题
- Producer:生产消息到topic的一方
- Consumer:订阅topic消费消息的一方
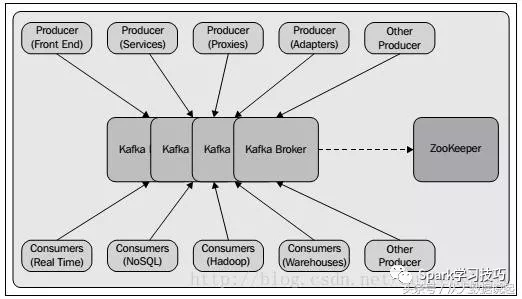
- Broker:Kafka的服务实例就是一个broker
Producer生产的消息通过网络发送给Kafka cluster,而Consumer从其中消费消息
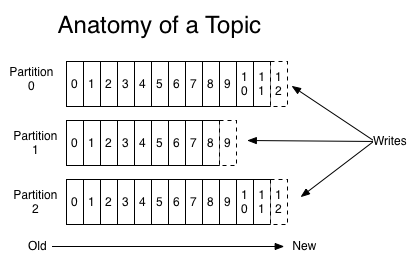
Topic 和Partition
消息发送时都被发送到一个topic,其本质就是一个目录,而topic由是由一些Partition Logs(分区日志)组成
1.2 安装
1.前期准备
2.解压
$ tar -zxvf kafka_*.tgz
并移动到要安装目录。
3.修改 kafka-server 的配置文件
$ vim kafka_home/config/server.properties
修改
broker.id=1 # 刚开始是id = 0
log.dirs=/data/kafka/logs-1 # 刚开始log存放在/tmp中
4.功能验证
- 启动zookeeper
# 默认zookeeper的客户端网络端口为2181
# clientPort=2181
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
- 启动kafka
# 默认连接zookeeper的端口为2181
# zookeeper.connect=localhost:2181
$ bin/kafka-server-start.sh config/server.properties
- 创建 topic
# 创建
# 此处--zookeeper定义zookeeper或者--boostrap-server定义kafka server均可
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
# 查看
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
- 产生消息
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
输入要产生的消息。
- 消费消息
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
打印消息。
- 查看topic信息
$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
- 设置多代理集群
# 拷贝设置文件
$ cp config/server.properties config/server-2.properties
$ cp config/server.properties config/server-3.properties
然后修改属性文件
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-2
config/server-3.properties:
broker.id=3
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-3
运行
$ bin/kafka-server-start.sh config/server-2.properties &
...
$ bin/kafka-server-start.sh config/server-3.properties &
...
创建复制因子为3的topic
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
查看信息
$ bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
“leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions. “replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive. “isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
节点2是topic唯一的分区Leader
验证(待验证,发现PID一直变动)
# 消息生成
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
# 消费消息
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
# 容错验证
## 关闭Leader节点
$ ps aux | grep server-1.properties
$ sudo kill -9 [PID]
# 查看topic信息
$ bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
2.Kafka 技术
2.1 介绍
2.1.1 API
kafka的API包括Producer、Consumer、Streams、Connector、AdminClient。
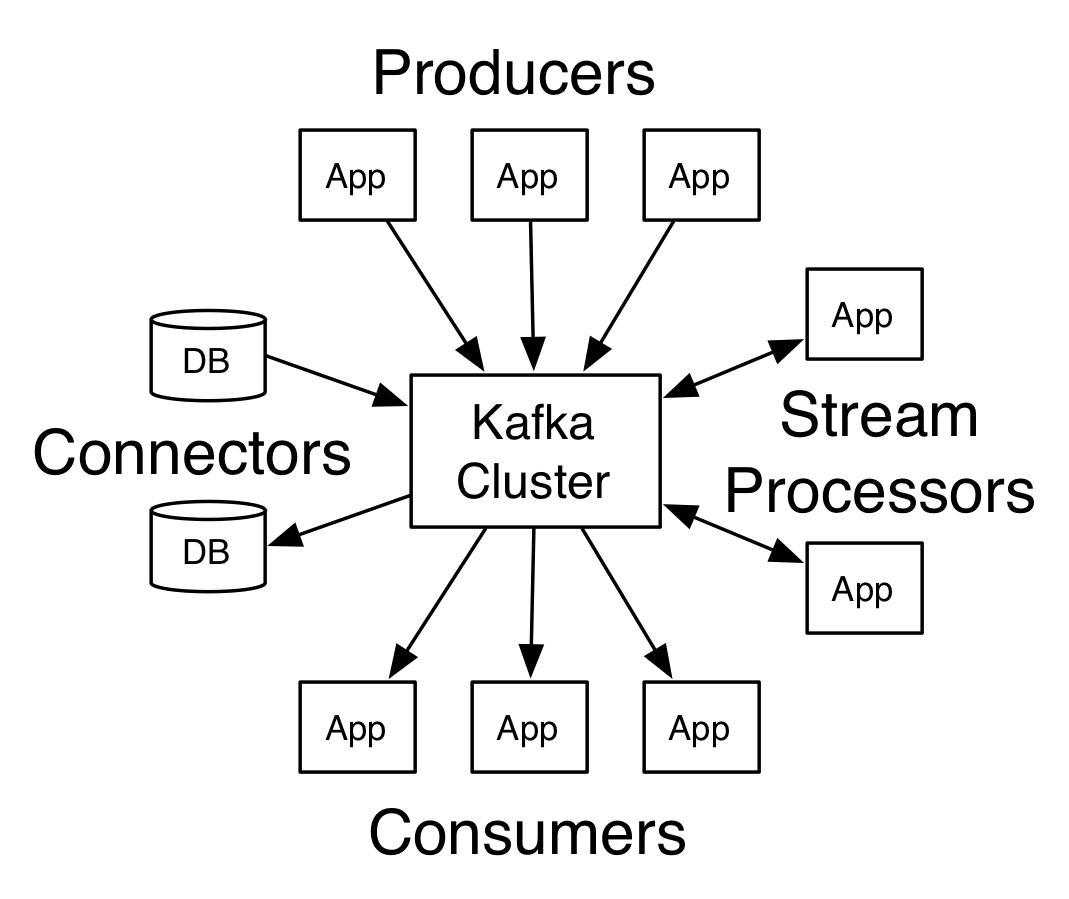
Producer用于应用(Application)生成消息至topic;
Consumer用于应用订阅一个或者多个topic,并进行流数据处理;
Streams用于应用作为流数据处理器,处理来自topic的数据,处理后,输出到topic。
Connector用于构建和运行可重用生产者或者消费者,连接Kafka topic和应用,如连接了DB的connector会记录变化。
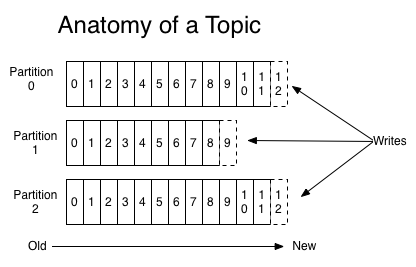
2.1.2 Topics和日志
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。
-
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制,如设置有效时间
-
每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,也可以以任意偏移量访问数据
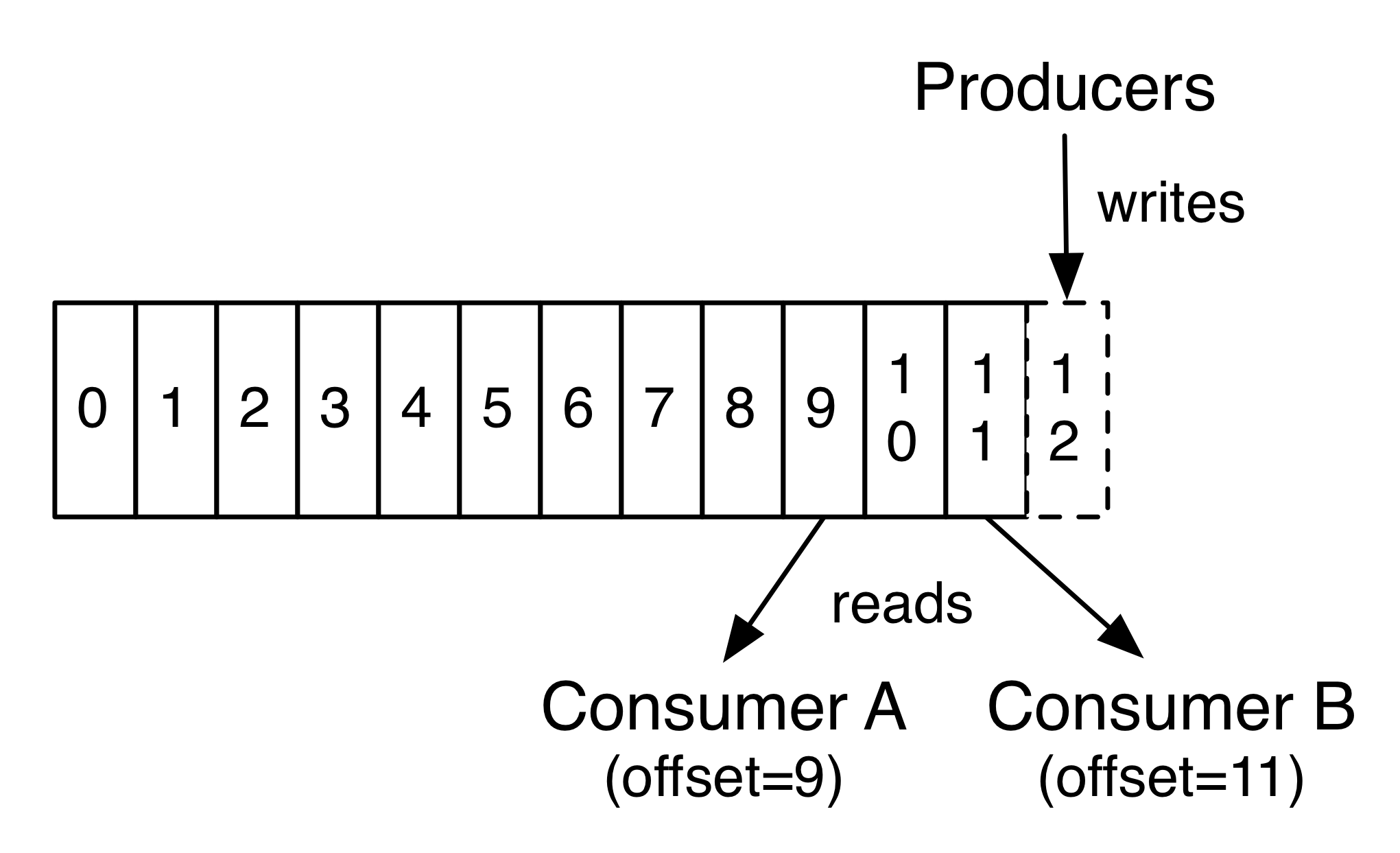
-
partition的作用:第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。第二,可以作为并行的单元集
2.1.3 分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server(broker) 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
关于broker、topic、partition的关系
一个broker就是一个服务器,partition是topic的一个分区(主要用于存储拓展和并行,肩见上方解释),patition为了实现容错性,将一个broker作为“leader”,0台或者多台其他的broker作为follwer,leader处理一切对partition的读写,而follwer只需同步数据。
2.1.4 生产者
生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。下面会介绍更多关于分区的使用。
2.1.5 消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.(处于同一个消费组的消费者,只有一个能够接受到某一条消息,而且是负载均衡的)
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
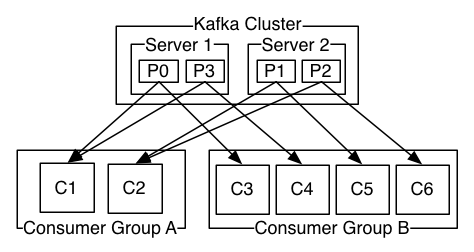
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个”逻辑订阅者”。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
2.1.6 保证
- 生产者发送到特定topic partition 的消息将按照发送的顺序处理。 也就是说,如果记录M1和记录M2由相同的生产者发送,并先发送M1记录,那么M1的偏移比M2小,并在日志中较早出现
- 一个消费者实例按照日志中的顺序查看记录.
- 对于具有N个副本的主题,我们最多容忍N-1个服务器故障,从而保证不会丢失任何提交到日志中的记录.
2.1.7 Kafka作为消息系统
传统的消息系统有两个模块: 队列 和 发布-订阅。 在队列中,消费者池从server读取数据,每条记录被池子中的一个消费者消费; 在发布订阅中,记录被广播到所有的消费者。两者均有优缺点。 队列的优点在于它允许你将处理数据的过程分给多个消费者实例,使你可以扩展处理过程(理解:一个处理,给多个消费者使用)。 不好的是,队列不是多订阅者模式的—一旦一个进程读取了数据,数据就会被丢弃。 而发布-订阅系统允许你广播数据到多个进程,但是无法进行扩展处理,因为每条消息都会发送给所有的订阅者。
消费组在Kafka有两层概念。在队列中,消费组允许你将处理过程分发给一系列进程(消费组中的成员),起到了拓展处理功能。 在发布订阅中,Kafka允许你将消息广播给多个消费组。
Kafka的优势在于每个topic都有以下特性—可以扩展处理并且允许多订阅者模式(通过消息组实现,见上方解释)—不需要只选择其中一个.
Kafka相比于传统消息队列还具有更严格的顺序保证
传统队列在服务器上保存有序的记录,如果多个消费者消费队列中的数据, 服务器将按照存储顺序输出记录。 虽然服务器按顺序输出记录,但是记录被异步传递给消费者, 因此记录可能会无序的到达不同的消费者。这意味着在并行消耗的情况下, 记录的顺序是丢失的。因此消息系统通常使用“唯一消费者”的概念,即只让一个进程从队列中消费, 但这就意味着不能够并行地处理数据。
Kafka 设计的更好。topic中的partition是一个并行的概念。 Kafka能够为一个消费者池提供顺序保证和负载平衡,是通过将topic中的partition分配给消费者组中的消费者来实现的, 以便每个分区由消费组中的一个消费者消耗。通过这样,我们能够确保消费者是该分区的唯一读者,并按顺序消费数据。 众多分区保证了多个消费者实例间的负载均衡。但请注意,消费者组中的消费者实例个数不能超过分区的数量。
2.1.8 Kafka作为存储系统
许多消息队列可以发布消息,除了消费消息之外还可以充当中间数据的存储系统。那么Kafka作为一个优秀的存储系统有什么不同呢?
数据写入Kafka后被写到磁盘,并且进行备份以便容错。直到完全备份,Kafka才让生产者认为完成写入,即使写入失败Kafka也会确保继续写入
Kafka使用磁盘结构,具有很好的扩展性—50kb和50TB的数据在server上表现一致。
可以存储大量数据,并且可通过客户端控制它读取数据的位置,您可认为Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
2.1.9 Kafka做流处理
Kafka 流处理不仅仅用来读写和存储流式数据,它最终的目的是为了能够进行实时的流处理。
在Kafka中,流处理器不断地从输入的topic获取流数据,处理数据后,再不断生产流数据到输出的topic中去。
例如,零售应用程序可能会接收销售和出货的输入流,经过价格调整计算后,再输出一串流式数据。
简单的数据处理可以直接用生产者和消费者的API。对于复杂的数据变换,Kafka提供了Streams API。 Stream API 允许应用做一些复杂的处理,比如将流数据聚合或者join。
这一功能有助于解决以下这种应用程序所面临的问题:处理无序数据,当消费端代码变更后重新处理输入,执行有状态计算等。
Streams API建立在Kafka的核心之上:它使用Producer和Consumer API作为输入,使用Kafka进行有状态的存储, 并在流处理器实例之间使用相同的消费组机制来实现容错。
2.1.10 Kafka做批处理
Kafka结合了像HDFS这样的分布式文件系统可以存储用于批处理的静态文件、传统的企业消息系统允许处理订阅后到达的数据
2.2 使用案例
2.2.1 消息
Kafka 很好地替代了传统的message broker(消息代理)。 Message brokers 可用于各种场合(如将数据生成器与数据处理解耦,缓冲未处理的消息等)。 与大多数消息系统相比,Kafka拥有更好的吞吐量、内置分区、具有复制和容错的功能,这使它成为一个非常理想的大型消息处理应用。
2.2.2 跟踪网站活动
Kafka 的初始用例是将用户活动跟踪管道重建为一组实时发布-订阅源。 这意味着网站活动(浏览网页、搜索或其他的用户操作)将被发布到中心topic,其中每个活动类型有一个topic。 这些订阅源提供一系列用例,包括实时处理、实时监视、对加载到Hadoop或离线数据仓库系统的数据进行离线处理和报告等。
每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大。
2.2.3 度量
Kafka 通常用于监控数据。这涉及到从分布式应用程序中汇总数据,然后生成可操作的集中数据源。
2.2.4 日志聚合
许多人使用Kafka来替代日志聚合解决方案。 日志聚合系统通常从服务器收集物理日志文件,并将其置于一个中心系统(可能是文件服务器或HDFS)进行处理。 Kafka 从这些日志文件中提取信息,并将其抽象为一个更加清晰的消息流。 这样可以实现更低的延迟处理且易于支持多个数据源及分布式数据的消耗。 与Scribe或Flume等以日志为中心的系统相比,Kafka具备同样出色的性能、更强的耐用性(因为复制功能)和更低的端到端延迟。
2.2.5 流处理
许多Kafka用户通过管道来处理数据,有多个阶段: 从Kafka topic中消费原始输入数据,然后聚合,修饰或通过其他方式转化为新的topic, 以供进一步消费或处理。 例如,一个推荐新闻文章的处理管道可以从RSS订阅源抓取文章内容并将其发布到“文章”topic; 然后对这个内容进行标准化或者重复的内容, 并将处理完的文章内容发布到新的topic; 最终它会尝试将这些内容推荐给用户。 这种处理管道基于各个topic创建实时数据流图。
2.2.6 采集日志
Event sourcing是一种应用程序设计风格,按时间来记录状态的更改。 Kafka 可以存储非常多的日志数据,为基于 event sourcing 的应用程序提供强有力的支持。
2.2.7 提交日志
Kafka 可以从外部为分布式系统提供日志提交功能。 日志有助于记录节点和行为间的数据,采用重新同步机制可以从失败节点恢复数据。 Kafka的日志压缩 功能支持这一用法。 这一点与Apache BookKeeper 项目类似。
2.3 APIS
Producer用于应用(Application)生成消息至topic;
Consumer用于应用订阅一个或者多个topic,并进行流数据处理;
Streams用于应用作为流数据处理器,处理来自topic的数据,处理后,输出到topic。
Connector用于构建和运行可重用生产者或者消费者,连接Kafka topic和应用、系统,如连接了DB的connector会记录变化。
AdminClient用于管理和检查topics、brokers和其他的Kafka对象。
2.3.1 Producer API
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
使用实例:地址
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
2.3.2 Consumer API
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
使用实例:地址
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
2.3.3 Streams API
应用作为流数据处理器,处理来自topic的数据,处理后,输出到topic。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.0</version>
</dependency>
使用实例:地址
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream-processing-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsConfig config = new StreamsConfig(props);
StreamsBuilder builder = new StreamsBuilder();
builder.<String, String>stream("my-input-topic").mapValues(value -> value.length().toString()).to("my-output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
2.3.4 Connect API
2.3.5 AdminClient API
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
2.4 配置
2.4.1 Broker配置
核心基础配置:
broker.id
log.dirs
zookeeper.connect
| 名称 | 描述 | 类型 | 默认值 | 有效值 | 重要性 |
|---|---|---|---|---|---|
| zookeeper.connect | Zookeeper主机地址 | string | 高 | ||
| advertised.host.name | 不建议:仅在未设置advertised.listeners 或 listeners时使用。用advertised.listeners替换。 主机名发布到zookeeper供客户端使用。在IaaS环境,这可能需要与broker绑定不通的端口。如果未设置,将使用host.name的值(如果已经配置)。否则,他将使用java.net.InetAddress.getCanonicalHostName()返回的值。 |
string | null | 高 | |
| advertised.listeners | 监听器发布到ZooKeeper供客户端使用,如果与listeners配置不同。在IaaS环境,这可能需要与broker绑定不通的接口。如果没有设置,将使用listeners的配置。与listeners不同的是,配置0.0.0.0元地址是无效的。 |
string | null | 高 | |
| advertised.port | 不建议:仅在未设置“advertised.listeners”或“listeners”时使用。使用advertised.listeners代替。 这个端口发布到ZooKeeper供客户端使用。在IaaS环境,这可能需要与broker绑定不通的端口。如果没有设置,它将绑定和broker相同的端口。 |
int | null | 高 | |
| auto.create.topics.enable | 是否允许在服务器上自动创建topic | boolean | true | 高 | |
| auto.leader.rebalance.enable | 是否允许leader平衡。后台线程会定期检查并触发leader平衡。 | boolean | true | 高 | |
| background.threads | 用于处理各种后台任务的线程数量 | int | 10 | [1,…] | 高 |
| broker.id | 用于服务的broker id。如果没设置,将生存一个唯一broker id。为了避免ZooKeeper生成的id和用户配置的broker id相冲突,生成的id将在reserved.broker.max.id的值基础上加1。 | int | -1 | 高 | |
| compression.type | 为特点的topic指定一个最终压缩类型。此配置接受的标准压缩编码方式有(’gzip’, ‘snappy’, ‘lz4’)。此外还有’uncompressed’相当于不压缩;’producer’意味着压缩类型由’producer’决定。 | string | producer | 高 | |
| delete.topic.enable | 是否允许删除topic。如果关闭此配置,通过管理工具删除topic将不再生效。 | boolean | true | 高 | |
| host.name | 不建议: 仅在未设置listeners时使用。使用listeners来代替。 如果设置了broker主机名,则他只会当定到这个地址。如果没设置,将绑定到所有接口。 |
string | ”” | 高 | |
| leader.imbalance.check.interval.seconds | 由控制器触发分区重新平衡检查的频率设置 | long | 300 | 高 | |
| leader.imbalance.per.broker.percentage | 每个broker允许的不平衡的leader的百分比,如果高于这个比值将触发leader进行平衡。这个值用百分比来指定。 | int | 10 | 高 | |
| listeners | 监听器列表 - 使用逗号分隔URI列表和监听器名称。如果侦听器名称不是安全协议,则还必须设置listener.security.protocol.map。指定主机名为0.0.0.0来绑定到所有接口。留空则绑定到默认接口上。合法监听器列表的示例:PLAINTEXT:// myhost:9092,SSL://:9091 CLIENT://0.0.0.0:9092,REPLICATION:// localhost:9093 | string | null | 高 | |
| log.dir | 保存日志数据的目录(对log.dirs属性的补充) | string | /tmp/kafka-logs | 高 | |
| log.dirs | 保存日志数据的目录,如果未设置将使用log.dir的配置。 | string | null | 高 | |
| log.flush.interval.messages | 在将消息刷新到磁盘之前,在日志分区上累积的消息数量。 | long | 9223372036854775807 | [1,…] | 高 |
| log.flush.interval.ms | 在刷新到磁盘之前,任何topic中的消息保留在内存中的最长时间(以毫秒为单位)。如果未设置,则使用log.flush.scheduler.interval.ms中的值。 | long | null | 高 | |
| log.flush.offset.checkpoint.interval.ms | 日志恢复点的最后一次持久化刷新记录的频率 | int | 60000 | [0,…] | 高 |
| log.flush.scheduler.interval.ms | 日志刷新器检查是否需要将所有日志刷新到磁盘的频率(以毫秒为单位) | long | 9223372036854775807 | 高 | |
| log.flush.start.offset.checkpoint.interval.ms | 我们更新日志持久化记录开始offset的频率 | int | 60000 | [0,…] | 高 |
| log.retention.bytes | 日志删除的大小阈值 | long | -1 | 高 | |
| log.retention.hours | 日志删除的时间阈值(小时为单位) | int | 168 | 高 | |
| log.retention.minutes | 日志删除的时间阈值(分钟为单位),如果未设置,将使用log.retention.hours的值 | int | null | 高 | |
| log.retention.ms | 日志删除的时间阈值(毫秒为单位),如果未设置,将使用log.retention.minutes的值 | long | null | 高 | |
| log.roll.hours | 新日志段轮转时间间隔(小时为单位),次要配置为log.roll.ms | int | 168 | [1,…] | 高 |
| log.roll.jitter.hours | 从logrolltimemillis(以小时计)中减去的最大抖动,次要配置log.roll.jitter.ms | int | 0 | [0,…] | 高 |
| log.roll.jitter.ms | 从logrolltimemillis(以毫秒计)中减去的最大抖动,如果未设置,则使用log.roll.jitter.hours的配置 | long | null | 高 | |
| log.roll.ms | 新日志段轮转时间间隔(毫秒为单位),如果未设置,则使用log.roll.hours配置 | long | null | 高 | |
| log.segment.bytes | 单个日志段文件最大大小 | int | 1073741824 | [14,…] | 高 |
| log.segment.delete.delay.ms | 从文件系统中删除一个日志段文件前的保留时间 | long | 60000 | [0,…] | 高 |
| message.max.bytes | kafka允许的最大的一个批次的消息大小。 如果这个数字增加,且有0.10.2版本以下的consumer,那么consumer的提取大小也必须增加,以便他们可以取得这么大的记录批次。 在最新的消息格式版本中,记录总是被组合到一个批次以提高效率。 在以前的消息格式版本中,未压缩的记录不会分组到批次中,并且此限制仅适用于该情况下的单个记录。可以使用topic设置max.message.bytes来设置每个topic。 max.message.bytes. |
int | 1000012 | [0,…] | 高 |
| min.insync.replicas | 当producer将ack设置为“全部”(或“-1”)时,min.insync.replicas指定了被认为写入成功的最小副本数。如果这个最小值不能满足,那么producer将会引发一个异常(NotEnoughReplicas或NotEnoughReplicasAfterAppend)。当一起使用时,min.insync.replicas和acks允许您强制更大的耐久性保证。 一个经典的情况是创建一个复本数为3的topic,将min.insync.replicas设置为2,并且producer使用“all”选项。 这将确保如果大多数副本没有写入producer则抛出异常。 | int | 1 | [1,…] | 高 |
| num.io.threads | 服务器用于处理请求的线程数,可能包括磁盘I/O | int | 8 | [1,…] | 高 |
| num.network.threads | 服务器用于从接收网络请求并发送网络响应的线程数 | int | 3 | [1,…] | 高 |
| num.recovery.threads.per.data.dir | 每个数据目录,用于启动时日志恢复和关闭时刷新的线程数 | int | 1 | [1,…] | 高 |
| num.replica.fetchers | 从源broker复制消息的拉取器的线程数。增加这个值可以增加follow broker的I/O并行度。 | int | 1 | 高 | |
| offset.metadata.max.bytes | 与offset提交相关联的元数据条目的最大大小 | int | 4096 | 高 | |
| offsets.commit.required.acks | 在offset提交可以接受之前,需要设置acks的数目,一般不需要更改,默认值为-1。 | short | -1 | 高 | |
| offsets.commit.timeout.ms | offset提交将延迟到topic所有副本收到提交或超时。这与producer请求超时类似。 | int | 5000 | [1,…] | 高 |
| offsets.load.buffer.size | 每次从offset段文件往缓存加载时,批量读取的数据大小 | int | 5242880 | [1,…] | 高 |
| offsets.retention.check.interval.ms | 检查失效offset的频率 | long | 600000 | [1,…] | 高 |
| offsets.retention.minutes | 超过这个保留期限未提交的offset将被丢弃 | int | 1440 | [1,…] | 高 |
| offsets.topic.compression.codec | 用于offsets topic的压缩编解码器 - 压缩可用于实现“原子”提交 | int | 0 | 高 | |
| offsets.topic.num.partitions | Offsets topic的分区数量(部署后不应更改) | int | 50 | [1,…] | 高 |
| offsets.topic.replication.factor | offset topic的副本数(设置的越大,可用性越高)。内部topic创建将失败,直到集群大小满足此副本数要求。 | short | 3 | [1,…] | 高 |
| offsets.topic.segment.bytes | 为了便于更快的日志压缩和缓存加载,offset topic段字节应该保持相对较小 | int | 104857600 | [1,…] | 高 |
| port | 不建议: 仅在未设置“listener”时使用。使用listeners来代替。端口用来来监听和接受连接 |
int | 9092 | 高 | |
| queued.max.requests | 网络线程阻塞前队列允许的最大请求数 | int | 500 | [1,…] | 高 |
| quota.consumer.default | 不建议:仅在动态默认配额未配置或在zookeeper中使用。任何由clientid区分开来的consumer,如果它每秒产生的字节数多于这个值,就会受到限制 | long | 9223372036854775807 | [1,…] | 高 |
| quota.producer.default | 不建议:仅在动态默认配额未配置或在zookeeper中使用。任何由clientid区分开来的producer,如果它每秒产生的字节数多于这个值,就会受到限制 | long | 9223372036854775807 | [1,…] | 高 |
| replica.fetch.min.bytes | 复制数据过程中,replica收到的每个fetch响应,期望的最小的字节数,如果没有收到足够的字节数,就会等待更多的数据,直到达到replicaMaxWaitTimeMs(复制数据超时时间) | int | 1 | 高 | |
| replica.fetch.wait.max.ms | 副本follow同leader之间通信的最大等待时间,失败了会重试。 此值始终应始终小于replica.lag.time.max.ms,以防止针对低吞吐量topic频繁收缩ISR | int | 500 | 高 | |
| replica.high.watermark.checkpoint.interval.ms | high watermark被保存到磁盘的频率,用来标记日后恢复点/td> | long | 5000 | 高 | |
| replica.lag.time.max.ms | 如果一个follower在这个时间内没有发送fetch请求或消费leader日志到结束的offset,leader将从ISR中移除这个follower,并认为这个follower已经挂了 | long | 10000 | 高 | |
| replica.socket.receive.buffer.bytes | socket接收网络请求的缓存大小 | int | 65536 | 高 | |
| replica.socket.timeout.ms | 副本复制数据过程中,发送网络请求的socket超时时间。这个值应该大于replica.fetch.wait.max.ms的值 | int | 30000 | 高 | |
| request.timeout.ms | 该配置控制客户端等待请求响应的最长时间。如果在超时之前未收到响应,则客户端将在必要时重新发送请求,如果重试仍然失败,则请求失败。 | int | 30000 | 高 | |
| socket.receive.buffer.bytes | 服务端用来处理socket连接的SO_RCVBUFF缓冲大小。如果值为-1,则使用系统默认值。 | int | 102400 | 高 | |
| socket.request.max.bytes | socket请求的最大大小,这是为了防止server跑光内存,不能大于Java堆的大小。 | int | 104857600 | [1,…] | 高 |
| socket.send.buffer.bytes | 服务端用来处理socket连接的SO_SNDBUF缓冲大小。如果值为-1,则使用系统默认值。 | int | 102400 | 高 | |
| transaction.max.timeout.ms | 事务允许的最大超时时间。如果客户请求的事务超时,那么broker将在InitProducerIdRequest中返回一错误。 这样可以防止客户超时时间过长,从而阻碍consumers读取事务中包含的topic。 | int | 900000 | [1,…] | 高 |
| transaction.state.log.load.buffer.size | 将producer ID和事务加载到高速缓存中时,从事务日志段(the transaction log segments)中批量读取的大小。 | int | 5242880 | [1,…] | 高 |
| transaction.state.log.min.isr | 覆盖事务topic的min.insync.replicas配置 | int | 2 | [1,…] | 高 |
| transaction.state.log.num.partitions | 事务topic的分区数(部署后不应该修改) | int | 50 | [1,…] | 高 |
| transaction.state.log.replication.factor | 事务topic的副本数(设置的越大,可用性越高)。内部topic在集群数满足副本数之前,将会一直创建失败。 | short | 3 | [1,…] | 高 |
| transaction.state.log.segment.bytes | 事务topic段应保持相对较小,以便于更快的日志压缩和缓存负载。 | int | 104857600 | [1,…] | 高 |
| transactional.id.expiration.ms | 事务协调器在未收到任何事务状态更新之前,主动设置producer的事务标识为过期之前将等待的最长时间(以毫秒为单位) | int | 604800000 | [1,…] | 高 |
| unclean.leader.election.enable | 指定副本是否能够不再ISR中被选举为leader,即使这样可能会丢数据 | boolean | false | 高 | |
| zookeeper.connection.timeout.ms | 与ZK server建立连接的超时时间,没有配置就使用zookeeper.session.timeout.ms | int | null | 高 | |
| zookeeper.session.timeout.ms | ZooKeeper的session的超时时间 | int | 6000 | 高 | |
| zookeeper.set.acl | ZooKeeper客户端连接是否设置ACL安全y安装 | boolean | false | 高 | |
| broker.id.generation.enable | 是否允许服务器自动生成broker.id。如果允许则产生的值会交由reserved.broker.max.id审核 | boolean | true | 中 | |
| broker.rack | broker的机架位置。 这将在机架感知副本分配中用于容错。例如:RACK1,us-east-1 | string | null | 中 | |
| connections.max.idle.ms | 连接空闲超时:服务器socket处理线程空闲超时关闭时间 | long | 600000 | 中 | |
| controlled.shutdown.enable | 是否允许服务器关闭broker服务 | boolean | true | 中 | |
| controlled.shutdown.max.retries | 当发生失败故障时,由于各种原因导致关闭服务的次数 | int | 3 | 中 | |
| controlled.shutdown.retry.backoff.ms | 在每次重试关闭之前,系统需要时间从上次故障状态(控制器故障切换,副本延迟等)中恢复。 这个配置决定了重试之前等待的时间。 | long | 5000 | 中 | |
| controller.socket.timeout.ms | 控制器到broker通道的socket超时时间 | int | 30000 | 中 | |
| default.replication.factor | 自动创建topic时的默认副本个数 | int | 1 | 中 | |
| delete.records.purgatory.purge.interval.requests | 删除purgatory中请求的清理间隔时间(purgatory:broker对于无法立即处理的请求,将会放在purgatory中,当请求完成后,并不会立即清除,还会继续在purgatory中占用资源,直到下一次delete.records.purgatory.purge.interval.requests) | int | 1 | 中 | |
| fetch.purgatory.purge.interval.requests | 提取purgatory中请求的间隔时间 | int | 1000 | 中 | |
| group.initial.rebalance.delay.ms | 在执行第一次重新平衡之前,group协调器将等待更多consumer加入group的时间。延迟时间越长意味着重新平衡的工作可能越小,但是等待处理开始的时间增加。 | int | 3000 | 中 | |
| group.max.session.timeout.ms | consumer注册允许的最大会话超时时间。超时时间越短,处理心跳越频繁从而使故障检测更快,但会导致broker被抢占更多的资源。 | int | 300000 | medium | |
| group.min.session.timeout.ms | consumer注册允许的最小会话超时时间。超时时间越短,处理心跳越频繁从而使故障检测更快,但会导致broker被抢占更多的资源。 | int | 6000 | 中 | |
| inter.broker.listener.name | broker间通讯的监听器名称。如果未设置,则侦听器名称由security.inter.broker.protocol定义。 同时设置此项和security.inter.broker.protocol属性是错误的,只设置一个。 | string | null | 中 | |
| inter.broker.protocol.version | 指定使用哪个版本的 inter-broker 协议。 在所有broker升级到新版本之后,这通常会有冲突。一些有效的例子是:0.8.0, 0.8.1, 0.8.1.1, 0.8.2, 0.8.2.0, 0.8.2.1, 0.9.0.0, 0.9.0.1,详情可以检查apiversion的完整列表 | string | 1.0-IV0 | 中 | |
| log.cleaner.backoff.ms | 检查log是否需要清除的时间间隔。 | long | 15000 | [0,…] | 中 |
| log.cleaner.dedupe.buffer.size | 日志去重清理线程所需要的内存 | long | 134217728 | 中 | |
| log.cleaner.delete.retention.ms | 日志记录保留时间 | long | 86400000 | 中 | |
| log.cleaner.enable | 在服务器上启用日志清理器进程。如果任何topic都使用cleanup.policy = compact,包括内部topic offset,则建议开启。如果被禁用的话,这些topic将不会被压缩,而且会不断增长。 | boolean | true | 中 | |
| log.cleaner.io.buffer.load.factor | 日志清理器去重的缓存负载数。完全重复数据的缓存比例可以改变。数值越高,清理的越多,但会导致更多的hash冲突 | double | 0.9 | 中 | |
| log.cleaner.io.buffer.size | 所有清理线程的日志清理I/O缓存区所需要的内存 | int | 524288 | [0,…] | 中 |
| log.cleaner.io.max.bytes.per.second | 日志清理器受到的大小限制数,因此它的I/O读写总和将小于平均值 | double | 1.7976931348623157E308 | 中 | |
| log.cleaner.min.cleanable.ratio | 日志中脏数据清理比例 | double | 0.5 | 中 | |
| log.cleaner.min.compaction.lag.ms | 消息在日志中保持未压缩的最短时间。 仅适用于正在压缩的日志。 | long | 0 | 中 | |
| log.cleaner.threads | 用于日志清理的后台线程的数量 | int | 1 | [0,…] | 中 |
| log.cleanup.policy | 超出保留窗口期的日志段的默认清理策略。用逗号隔开有效策略列表。有效策略:“delete”和“compact” | list | delete | [compact, delete] | 中 |
| log.index.interval.bytes | 添加offset索引字段大小间隔(设置越大,代表扫描速度越快,但是也更耗内存) | int | 4096 | [0,…] | 中 |
| log.index.size.max.bytes | offset索引的最大字节数 | int | 10485760 | [4,…] | 中 |
| log.message.format.version | 指定broker用于将消息附加到日志的消息格式版本。应该是一个有效的apiversion值。例如:0.8.2,0.9.0.0,0.10.0,详情去看apiversion。通过设置特定的消息格式版本,用户得保证磁盘上的所有现有消息的版本小于或等于指定的版本。不正确地设置这个值会导致旧版本的用户出错,因为他们将接收到他们无法处理的格式消息。 | string | 1.0-IV0 | 中 | |
| log.message.timestamp.difference.max.ms | broker收到消息时的时间戳和消息中指定的时间戳之间允许的最大差异。当log.message.timestamp.type=CreateTime,如果时间差超过这个阈值,消息将被拒绝。如果log.message.timestamp.type = logappendtime,则该配置将被忽略。允许的最大时间戳差值,不应大于log.retention.ms,以避免不必要的频繁日志滚动。 | long | 9223372036854775807 | 中 | |
| log.message.timestamp.type | 定义消息中的时间戳是消息创建时间还是日志追加时间。 该值应该是“createtime”或“logappendtime”。 | string | CreateTime | [CreateTime, LogAppendTime] | 中 |
| log.preallocate | 创建新的日志段前是否应该预先分配文件?如果你在windows上使用kafka,你可能需要打开个这个选项 | boolean | false | 中 | |
| log.retention.check.interval.ms | 日志清理器检查是否有日志符合删除的频率(以毫秒为单位) | long | 300000 | [1,…] | 中 |
| max.connections.per.ip | 每个IP允许的最大连接数 | int | 2147483647 | [1,…] | 中 |
| max.connections.per.ip.overrides | 每个IP或主机名将覆盖默认的最大连接数 | string | ”” | 中 | |
| num.partitions | 每个topic的默认日志分区数 | int | 1 | [1,…] | 中 |
| principal.builder.class | 实现kafkaprincipalbuilder接口类的全名,该接口用于构建授权期间使用的kafkaprincipal对象。此配置还支持以前已弃用的用于ssl客户端身份验证的principalbuilder接口。如果未定义主体构建器,则默认采用所使用的安全协议。对于ssl身份验证,如果提供了一个主体名称,主体名称将是客户端证书的专有名称;否则,如果不需要客户端身份验证,则主体名称将是匿名的。对于sasl身份验证,如果使用gssapi,则将使用由sasl.kerberos.principal.to.local.rules定义的规则来生成主体,而使用其他机制的sasl身份验证ID。若果用明文,委托人将是匿名的。 |
class | null | 中 | |
| producer.purgatory.purge.interval.requests | producer请求purgatory的清除间隔(请求数量) | int | 1000 | 中 | |
| queued.max.request.bytes | 在不再读取请求之前队列的字节数 | long | -1 | 中 | |
| replica.fetch.backoff.ms | 当拉取分区发生错误时,睡眠的时间。 | int | 1000 | [0,…] | 中 |
| replica.fetch.max.bytes | 尝试提取每个分区的消息的字节数。这并不是绝对最大值,如果第一个非空分区的第一个批量记录大于这个值,那么批处理仍将被执行并返回,以确保进度可以正常进行下去。broker接受的最大批量记录大小通过message.max.bytes(broker配置)或max.message.bytes(topic配置)进行配置。 |
int | 1048576 | [0,…] | medium |
| replica.fetch.response.max.bytes | 预计整个获取响应的最大字节数。记录被批量取回时,如果取第一个非空分区的第一个批量记录大于此值,记录的批处理仍将被执行并返回以确保可以进行下去。因此,这不是绝对的最大值。 broker接受的最大批量记录大小通过message.max.bytes(broker配置)或max.message.bytes(topic配置)进行配置。 |
int | 10485760 | [0,…] | 中 |
| reserved.broker.max.id | 可以用于broker.id的最大数量 | int | 1000 | [0,…] | 中 |
| sasl.enabled.mechanisms | kafka服务器中启用的sasl机制的列表。 该列表可能包含安全提供程序可用的任何机制。默认情况下只有gssapi是启用的。 | list | GSSAPI | 中 | |
| sasl.kerberos.kinit.cmd | Kerberos kinit 命令路径。 | string | /usr/bin/kinit | 中 | |
| sasl.kerberos.min.time.before.relogin | 登录线程在尝试刷新间隔内的休眠时间。 | long | 60000 | 中 | |
| sasl.kerberos.principal.to.local.rules | 主体名称到简称映射的规则列表(通常是操作系统用户名)。按顺序,使用与principal名称匹配的第一个规则将其映射到简称。列表中的任何后续规则都将被忽略。 默认情况下,{username} / {hostname} @ {realm}形式的主体名称映射到{username}。 有关格式的更多细节,请参阅安全授权和acls。 请注意,如果由principal.builder.class配置提供了kafkaprincipalbuilder的扩展,则忽略此配置。 | list | DEFAULT | 中 | |
| sasl.kerberos.service.name | kafka运行的kerberos的主体名称。 这可以在kafka的JAAS配置或在kafka的配置中定义。 | string | null | 中 | |
| sasl.kerberos.ticket.renew.jitter | 添加到更新时间的随机抖动的百分比 | double | 0.05 | 中 | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将休眠,直到从上次刷新到ticket的到期的时间到达(指定窗口因子),在此期间它将尝试更新ticket。 | double | 0.8 | 中 | |
| sasl.mechanism.inter.broker.protocol | SASL机制,用于broker之间的通讯,默认是GSSAPI。 | string | GSSAPI | 中 | |
| security.inter.broker.protocol | broker之间的安全通讯协议,有效值有:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL。同时设置此配置和inter.broker.listener.name属性会出错 | string | PLAINTEXT | 中 | |
| ssl.cipher.suites | 密码套件列表。 这是一种用于使用tls或ssl网络协议来协商网络连接的安全设置的认证,加密,mac和密钥交换算法的命名组合。 默认情况下,所有可用的密码套件都受支持。 | list | null | 中 | |
| ssl.client.auth | 配置请求客户端的broker认证。常见的设置:ssl.client.auth=required如果设置需要客户端认证。ssl.client.auth=requested客户端认证可选,不同于requested,客户端可选择不提供自身的身份验证信息。ssl.client.auth=none 不需要客户端身份认证。 |
string | none | [required, requested, none] | 中 |
| ssl.enabled.protocols | 已启用的SSL连接协议列表。 | list | TLSv1.2,TLSv1.1,TLSv1 | 中 | |
| ssl.key.password | 秘钥库文件中的私钥密码。对客户端是可选的。 | password | null | 中 | |
| ssl.keymanager.algorithm | 用于SSL连接的密钥管理工厂算法。默认值是为Java虚拟机配置的密钥管理器工厂算法。 | string | SunX509 | 中 | |
| ssl.keystore.location | 密钥仓库文件的位置。客户端可选,并可用于客户端的双向认证。 | string | null | 中 | |
| ssl.keystore.password | 密钥仓库文件的仓库密码。客户端可选,只有ssl.keystore.location配置了才需要。 | password | null | 中 | |
| ssl.keystore.type | 密钥仓库文件的格式。客户端可选。 | string | JKS | 中 | |
| ssl.protocol | 用于生成SSLContext,默认是TLS,适用于大多数情况。允许使用最新的JVM,LS, TLSv1.1 和TLSv1.2。 SSL,SSLv2和SSLv3 老的JVM也可能支持,但由于有已知的安全漏洞,不建议使用。 | string | TLS | ||
| ssl.provider | 用于SSL连接的安全提供程序的名称。默认值由JVM的安全程序提供。 | string | null | 中 | |
| ssl.trustmanager.algorithm | 信任管理工厂用于SSL连接的算法。默认为Java虚拟机配置的信任算法。 | string | PKIX | 中 | |
| ssl.truststore.location | 信任文件的存储位置。 | string | null | 中 | |
| ssl.truststore.password | 信任存储文件的密码。 如果密码未设置,则仍然可以访问信任库,但完整性检查将被禁用。 | password | null | 中 | |
| ssl.truststore.type | 信任存储文件的文件格式。 | string | JKS | 中 | |
| alter.config.policy.class.name | 应该用于验证的alter configs策略类。 该类应该实现org.apache.kafka.server.policy.alterconfigpolicy接口。 | class | null | 低 | |
| authorizer.class.name | 用于认证授权的程序类 | string | ”” | 低 | |
| create.topic.policy.class.name | 用于验证的创建topic策略类。 该类应该实现org.apache.kafka.server.policy.createtopicpolicy接口。 | class | null | 低 | |
| listener.security.protocol.map | 侦听器名称和安全协议之间的映射。必须定义为相同的安全协议可用于多个端口或IP。例如,即使两者都需要ssl,内部和外部流量也可以分开。具体的说,用户可以定义名字为INTERNAL和EXTERNAL的侦听器,这个属性为:internal:ssl,external:ssl。 如图所示,键和值由冒号分隔,映射条目以逗号分隔。 每个监听者名字只能在映射表上出现一次。 通过向配置名称添加规范化前缀(侦听器名称小写),可以为每个侦听器配置不同的安全性(ssl和sasl)设置。 例如,为内部监听器设置不同的密钥仓库,将会设置名称为“listener.name.internal.ssl.keystore.location”的配置。 如果没有设置侦听器名称的配置,配置将回退到通用配置(即ssl.keystore.location)。 |
string | PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL | 低 | |
| metric.reporters | 度量报告的类列表,通过实现MetricReporter接口,允许插入新度量标准类。JmxReporter包含注册JVM统计。 |
list | ”” | 低 | |
| metrics.num.samples | 维持计算度量的样本数 | int | 2 | [1,…] | 低 |
| metrics.recording.level | 指标的最高记录级别 | string | INFO | 低 | |
| metrics.sample.window.ms | 计算度量样本的时间窗口 | long | 30000 | [1,…] | 低 |
| quota.window.num | 在内存中保留客户端限额的样本数 | int | 11 | [1,…] | 低 |
| quota.window.size.seconds | 每个客户端限额的样本时间跨度 | int | 1 | [1,…] | 低 |
| replication.quota.window.num | 在内存中保留副本限额的样本数 | int | 11 | [1,…] | 低 |
| replication.quota.window.size.seconds | 每个副本限额样本数的时间跨度 | int | 1 | [1,…] | 低 |
| ssl.endpoint.identification.algorithm | 端点身份标识算法,使用服务器证书验证服务器主机名 | string | null | 低 | |
| ssl.secure.random.implementation | 用于SSL加密操作的SecureRandom PRNG实现 | string | null | 低 | |
| transaction.abort.timed.out.transaction.cleanup.interval.ms | 回滚已超时的事务的时间间隔 | int | 60000 | [1,…] | 低 |
| transaction.remove.expired.transaction.cleanup.interval.ms | 删除由于transactional.id.expiration.ms传递过程而过期的事务的时间间隔 | int | 3600000 | [1,…] | low |
| zookeeper.sync.time.ms | ZK follower同步可落后leader多久/td> | int | 2000 | 低 |
2.4.2 Topic级别配置
与Topic相关的配置既包含服务器默认值,也包含可选的每个Topic覆盖值。 如果没有给出每个Topic的配置,那么服务器默认值就会被使用。 通过提供一个或多个 --config 选项,可以在创建Topic时设置覆盖值。 本示例使用自定义的最大消息大小和刷新率创建了一个名为 my-topic 的topic:
$ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
也可以在使用alter configs命令稍后更改或设置覆盖值. 本示例重置my-topic的最大消息的大小:
$ bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --alter --add-config max.message.bytes=128000
可以执行如下操作来检查topic设置的覆盖值
$ bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --describe
可以执行如下操作来删除一个覆盖值
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --alter --delete-config max.message.bytes
以下是Topic级别配置。 “服务器默认属性”列是该属性的默认配置。 一个Topic如果没有给出一个明确的覆盖值,相应的服务器默认配置将会生效。
| 名称 | 描述 | 类型 | 默认值 | 有效值 | 服务器默认属性 | 重要性 |
|---|---|---|---|---|---|---|
| cleanup.policy | 该配置项可以是 “delete” 或 “compact”。 它指定在旧日志段上使用的保留策略。 默认策略 (“delete”) 将在达到保留时间或大小限制时丢弃旧段。 “compact” 设置将启用该topic的日志压缩 。 | list | delete | [compact, delete] | log.cleanup.policy | medium |
| compression.type | 为给定的topic指定最终压缩类型。这个配置接受标准的压缩编解码器 (‘gzip’, ‘snappy’, lz4) 。它为’uncompressed’时意味着不压缩,当为’producer’时,这意味着保留producer设置的原始压缩编解码器。 | string | producer | [uncompressed, snappy, lz4, gzip, producer] | compression.type | medium |
| delete.retention.ms | 保留 日志压缩topics的删除墓碑标记的时间。此设置还对consumer从偏移量0开始时必须完成读取的时间进行限制,以确保它们获得最后阶段的有效快照(否则,在完成扫描之前可能会收集到删除墓碑)。 | long | 86400000 | [0,…] | log.cleaner.delete.retention.ms | medium |
| file.delete.delay.ms | 删除文件系统上的一个文件之前所需等待的时间。 | long | 60000 | [0,…] | log.segment.delete.delay.ms | medium |
| flush.messages | 这个设置允许指定一个时间间隔n,每隔n个消息我们会强制把数据fsync到log。例如,如果设置为1,我们会在每条消息之后同步。如果是5,我们会在每五个消息之后进行fsync。一般来说,我们建议您不要设置它,而是通过使用replication机制来持久化数据,和允许更高效的操作系统后台刷新功能。这个设置可以针对每个topic的情况自定义 (请参阅 topic的配置部分). | long | 9223372036854775807 | [0,…] | log.flush.interval.messages | medium |
| flush.ms | 这个设置允许指定一个时间间隔,每隔一段时间我们将强制把数据fsync到log。例如,如果这个设置为1000,我们将在1000 ms后执行fsync。一般来说,我们建议您不要设置它,而是通过使用replication机制来持久化数据,和允许更高效的操作系统后台刷新功能。 | long | 9223372036854775807 | [0,…] | log.flush.interval.ms | medium |
| follower.replication.throttled.replicas | 应该在follower侧限制日志复制的副本列表。该列表应以[PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:…的形式描述一组副本,或者也可以使用通配符“*”来限制该topic的所有副本。 | list | ”” | [partitionId],[brokerId]:[partitionId],[brokerId]:… | follower.replication.throttled.replicas | medium |
| index.interval.bytes | 此设置控制Kafka向其偏移索引添加索引条目的频率。默认设置确保我们大约每4096个字节索引一条消息。更多的索引允许读取更接近日志中的确切位置,但这会使索引更大。您可能不需要改变该值。 | int | 4096 | [0,…] | log.index.interval.bytes | medium |
| leader.replication.throttled.replicas | 应该在leader侧限制日志复制的副本列表。该列表应以[PartitionId]:[BrokerId],[PartitionId]:[BrokerId]:…的形式描述一组副本,或者也可以使用通配符“*”来限制该topic的所有副本。 | list | ”” | [partitionId],[brokerId]:[partitionId],[brokerId]:… | leader.replication.throttled.replicas | medium |
| max.message.bytes | Kafka允许的最大记录批次大小。如果这个参数被增加了且consumers是早于0.10.2版本,那么consumers的fetch size必须增加到该值,以便他们可以取得这么大的记录批次。在最新的消息格式版本中,记录总是分组成多个批次以提高效率。在以前的消息格式版本中,未压缩的记录不会分组到多个批次,并且限制在该情况下只能应用单条记录。 | int | 1000012 | [0,…] | message.max.bytes | medium |
| message.format.version | 指定broker将用于将消息附加到日志的消息格式版本。该值应该是有效的ApiVersion。如:0.8.2,0.9.0.0,0.10.0,查看ApiVersion获取更多细节。通过设置特定的消息格式版本,用户将发现磁盘上的所有现有消息都小于或等于指定的版本。不正确地设置此值将导致旧版本的使用者中断,因为他们将收到他们不理解的格式的消息。 | string | 1.0-IV0 | log.message.format.version | medium | |
| message.timestamp.difference.max.ms | broker接收消息时所允许的时间戳与消息中指定的时间戳之间的最大差异。如果message.timestamp.type=CreateTime,则如果时间戳的差异超过此阈值,则将拒绝消息。如果message.timestamp.type=LogAppendTime,则忽略此配置。 | long | 9223372036854775807 | [0,…] | log.message.timestamp.difference.max.ms | medium |
| message.timestamp.type | 定义消息中的时间戳是消息创建时间还是日志附加时间。值应该是“CreateTime”或“LogAppendTime” | string | CreateTime | log.message.timestamp.type | medium | |
| min.cleanable.dirty.ratio | 此配置控制日志compaction程序尝试清理日志的频率(假设启用了log compaction)。默认情况下,我们将避免清除超过50%的日志已经合并的日志。这个比率限制了重复在日志中浪费的最大空间(最多为50%,日志中最多有50%可能是重复的)。一个更高的比率将意味着更少,更高效的清理,但将意味着在日志中浪费更多的空间。 | double | 0.5 | [0,…,1] | log.cleaner.min.cleanable.ratio | medium |
| min.compaction.lag.ms | 消息在日志中保持未压缩的最短时间。仅适用于被合并的日志。 | long | 0 | [0,…] | log.cleaner.min.compaction.lag.ms | medium |
| min.insync.replicas | 当producer将ack设置为“all”(或“-1”)时,此配置指定必须确认写入才能被认为成功的副本的最小数量。如果这个最小值无法满足,那么producer将引发一个异常(NotEnough Replicas或NotEnough ReplicasAfterAppend)。 当使用时,min.insync.Copicas和ack允许您执行更好的持久化保证。一个典型的场景是创建一个复制因子为3的topic,将min.insync.Copicas设置为2,并生成带有“All”的ack。这将确保如果大多数副本没有接收到写,则producer将引发异常。 | int | 1 | [1,…] | min.insync.replicas | medium |
| preallocate | 如果在创建新的日志段时应该预先分配磁盘上的文件,则为True。 | boolean | false | log.preallocate | medium | |
| retention.bytes | 如果使用“delete”保留策略,此配置控制分区(由日志段组成)在放弃旧日志段以释放空间之前的最大大小。默认情况下,没有大小限制,只有时间限制。由于此限制是在分区级别强制执行的,因此,将其乘以分区数,计算出topic保留值,以字节为单位。 | long | -1 | log.retention.bytes | medium | |
| retention.ms | 如果使用“delete”保留策略,此配置控制保留日志的最长时间,然后将旧日志段丢弃以释放空间。这代表了用户读取数据的速度的SLA。 | long | 604800000 | log.retention.ms | medium | |
| segment.bytes | 此配置控制日志的段文件大小。保留和清理总是一次完成一个文件,所以更大的段大小意味着更少的文件,但对保留的粒度控制更少。 | int | 1073741824 | [14,…] | log.segment.bytes | medium |
| segment.index.bytes | 此配置控制将偏移量映射到文件位置的索引大小。我们预先分配这个索引文件并且只在日志滚动后收缩它。您通常不需要更改此设置。 | int | 10485760 | [0,…] | log.index.size.max.bytes | medium |
| segment.jitter.ms | 从预定的分段滚动时间减去最大随机抖动,以避免段滚动产生惊群效应。 | long | 0 | [0,…] | log.roll.jitter.ms | medium |
| segment.ms | 这个配置控制在一段时间后,Kafka将强制日志滚动,即使段文件没有满,以确保保留空间可以删除或合并旧数据。 | long | 604800000 | [0,…] | log.roll.ms | medium |
| unclean.leader.election.enable | 指示是否启用不在ISR集合中的副本选为领导者作为最后的手段,即使这样做可能导致数据丢失。 | boolean | false | unclean.leader.election.enable | medium |
2.4.3 Producer配置
Java生产者的配置
| NAME | DESCRIPTION | TYPE | DEFAULT | VALID VALUES | IMPORTANCE |
|---|---|---|---|---|---|
| bootstrap.servers | 这是一个用于建立初始连接到kafka集群的”主机/端口对”配置列表。不论这个参数配置了哪些服务器来初始化连接,客户端都是会均衡地与集群中的所有服务器建立连接。—配置的服务器清单仅用于初始化连接,以便找到集群中的所有服务器。配置格式: host1:port1,host2:port2,.... 由于这些主机是用于初始化连接,以获得整个集群(集群是会动态变化的),因此这个配置清单不需要包含整个集群的服务器。(当然,为了避免单节点风险,这个清单最好配置多台主机)。 |
list | high | ||
| key.serializer | 关键字的序列化类,实现以下接口: org.apache.kafka.common.serialization.Serializer接口。 |
class | high | ||
| value.serializer | 值的序列化类,实现以下接口: org.apache.kafka.common.serialization.Serializer接口。 |
class | high | ||
| acks | 此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。 这个参数是为了保证发送请求的可靠性。以下配置方式是允许的:acks=0如果设置为0,则 producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。acks=1如果设置为1,leader节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。acks=all 如果设置为all,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1与acks=all是等效的。 |
string | 1 | [all, -1, 0, 1] | high |
| buffer.memory | Producer 用来缓冲等待被发送到服务器的记录的总字节数。如果记录发送的速度比发送到服务器的速度快, Producer 就会阻塞,如果阻塞的时间超过 max.block.ms 配置的时长,则会抛出一个异常。这个配置与 Producer 的可用总内存有一定的对应关系,但并不是完全等价的关系,因为 Producer 的可用内存并不是全部都用来缓存。一些额外的内存可能会用于压缩(如果启用了压缩),以及维护正在运行的请求。 |
long | 33554432 | [0,…] | high |
| compression.type | Producer 生成数据时可使用的压缩类型。默认值是none(即不压缩)。可配置的压缩类型包括:none, gzip, snappy, 或者 lz4 。压缩是针对批处理的所有数据,所以批处理的效果也会影响压缩比(更多的批处理意味着更好的压缩)。 |
string | none | high | |
| retries | 若设置大于0的值,则客户端会将发送失败的记录重新发送,尽管这些记录有可能是暂时性的错误。请注意,这种 retry 与客户端收到错误信息之后重新发送记录并无区别。允许 retries 并且没有设置max.in.flight.requests.per.connection为1时,记录的顺序可能会被改变。比如:当两个批次都被发送到同一个 partition ,第一个批次发生错误并发生 retries 而第二个批次已经成功,则第二个批次的记录就会先于第一个批次出现。 |
int | 0 | [0,…,2147483647] | high |
| ssl.key.password | key store 文件中私钥的密码。这对于客户端来说是可选的。 | password | null | high | |
| ssl.keystore.location | key store 文件的位置。这对于客户端来说是可选的,可用于客户端的双向身份验证。 | string | null | high | |
| ssl.keystore.password | key store 文件的密码。这对于客户端是可选的,只有配置了 ssl.keystore.location 才需要配置该选项。 | password | null | high | |
| ssl.truststore.location | trust store 文件的位置。 | string | null | high | |
| ssl.truststore.password | trust store 文件的密码。如果一个密码没有设置到 trust store ,这个密码仍然是可用的,但是完整性检查是禁用的。 | password | null | high | |
| batch.size | 当将多个记录被发送到同一个分区时, Producer 将尝试将记录组合到更少的请求中。这有助于提升客户端和服务器端的性能。这个配置控制一个批次的默认大小(以字节为单位)。当记录的大小超过了配置的字节数, Producer 将不再尝试往批次增加记录。发送到 broker 的请求会包含多个批次的数据,每个批次对应一个 partition 的可用数据小的 batch.size 将减少批处理,并且可能会降低吞吐量(如果 batch.size = 0的话将完全禁用批处理)。 很大的 batch.size 可能造成内存浪费,因为我们一般会在 batch.size 的基础上分配一部分缓存以应付额外的记录。 | int | 16384 | [0,…] | medium |
| client.id | 发出请求时传递给服务器的 ID 字符串。这样做的目的是为了在服务端的请求日志中能够通过逻辑应用名称来跟踪请求的来源,而不是只能通过IP和端口号跟进。 | string | ”” | medium | |
| connections.max.idle.ms | 在此配置指定的毫秒数之后,关闭空闲连接。 | long | 540000 | medium | |
| linger.ms | producer 会将两个请求发送时间间隔内到达的记录合并到一个单独的批处理请求中。通常只有当记录到达的速度超过了发送的速度时才会出现这种情况。然而,在某些场景下,即使处于可接受的负载下,客户端也希望能减少请求的数量。这个设置是通过添加少量的人为延迟来实现的&mdash;即,与其立即发送记录, producer 将等待给定的延迟时间,以便将在等待过程中到达的其他记录能合并到本批次的处理中。这可以认为是与 TCP 中的 Nagle 算法类似。这个设置为批处理的延迟提供了上限:一旦我们接受到记录超过了分区的 batch.size ,Producer 会忽略这个参数,立刻发送数据。但是如果累积的字节数少于 batch.size ,那么我们将在指定的时间内“逗留”(linger),以等待更多的记录出现。这个设置默认为0(即没有延迟)。例如:如果设置linger.ms=5 ,则发送的请求会减少并降低部分负载,但同时会增加5毫秒的延迟。 |
long | 0 | [0,…] | medium |
| max.block.ms | 该配置控制KafkaProducer.send()和KafkaProducer.partitionsFor() 允许被阻塞的时长。这些方法可能因为缓冲区满了或者元数据不可用而被阻塞。用户提供的序列化程序或分区程序的阻塞将不会被计算到这个超时。 |
long | 60000 | [0,…] | medium |
| max.request.size | 请求的最大字节数。这个设置将限制 Producer 在单个请求中发送的记录批量的数量,以避免发送巨大的请求。这实际上也等同于批次的最大记录数的限制。请注意,服务器对批次的大小有自己的限制,这可能与此不同。 | int | 1048576 | [0,…] | medium |
| partitioner.class | 指定计算分区的类,实现 org.apache.kafka.clients.producer.Partitioner 接口。 |
class | org.apache.kafka.clients.producer.internals.DefaultPartitioner | medium | |
| receive.buffer.bytes | 定义读取数据时 TCP 接收缓冲区(SO_RCVBUF)的大小,如果设置为-1,则使用系统默认值。 | int | 32768 | [-1,…] | medium |
| request.timeout.ms | 客户端等待请求响应的最大时长。如果超时未收到响应,则客户端将在必要时重新发送请求,如果重试的次数达到允许的最大重试次数,则请求失败。这个参数应该比 replica.lag.time.max.ms (Broker 的一个参数)更大,以降低由于不必要的重试而导致的消息重复的可能性。 | int | 30000 | [0,…] | medium |
| sasl.jaas.config | SASL 连接使用的 JAAS 登陆上下文参数,以 JAAS 配置文件的格式进行配置。 JAAS 配置文件格式可参考这里。值的格式: ‘ (=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | Kafka 运行时的 Kerberos 主体名称。可以在 Kafka 的 JAAS 配置文件或者 Kafka 的配置文件中配置。 | string | null | medium | |
| sasl.mechanism | 用于客户端连接的 SASL 机制。可以是任意安全可靠的机制。默认是 GSSAPI 机制。 | string | GSSAPI | medium | |
| security.protocol | 与 brokers 通讯的协议。可配置的值有: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL. | string | PLAINTEXT | medium | |
| send.buffer.bytes | 定义发送数据时的 TCP 发送缓冲区(SO_SNDBUF)的大小。如果设置为-1,则使用系统默认值。 | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | 可用于 SSL 连接的协议列表。 | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | key store 文件的文件格类型。这对于客户端来说是可选的。 | string | JKS | medium | |
| ssl.protocol | 用于生成SSLContext的SSL协议。默认设置是TLS,大多数情况下不会有问题。在最近的jvm版本中,允许的值是TLS、tlsv1.1和TLSv1.2。在旧的jvm中可能会支持SSL、SSLv2和SSLv3,但是由于存在已知的安全漏洞,因此不建议使用。 | string | TLS | medium | |
| ssl.provider | 用于 SSL 连接security provider 。默认值是当前 JVM 版本的默认 security provider 。 | string | null | medium | |
| ssl.truststore.type | trust store 的文件类型。 | string | JKS | medium | |
| enable.idempotence | 当设置为true时, Producer 将确保每个消息在 Stream 中只写入一个副本。如果为false,由于 Broker 故障导致 Producer 进行重试之类的情况可能会导致消息重复写入到 Stream 中。请注意,启用幂等性需要确保max.in.flight.requests.per.connection小于或等于5,retries大于等于0,并且ack必须设置为all 。如果这些值不是由用户明确设置的,那么将自动选择合适的值。如果设置了不兼容的值,则将抛出一个ConfigException的异常。 |
boolean | false | low | |
| interceptor.classes | 配置 interceptor 类的列表。实现org.apache.kafka.clients.producer.ProducerInterceptor接口之后可以拦截(并可能改变)那些 Producer 还没有发送到 kafka 集群的记录。默认情况下,没有 interceptor 。 |
list | null | low | |
| max.in.flight.requests.per.connection | 在发生阻塞之前,客户端的一个连接上允许出现未确认请求的最大数量。注意,如果这个设置大于1,并且有失败的发送,则消息可能会由于重试而导致重新排序(如果重试是启用的话)。 | int | 5 | [1,…] | low |
| metadata.max.age.ms | 刷新元数据的时间间隔,单位毫秒。即使没有发现任何分区的 leadership 发生变更也会强制刷新以便能主动发现新的 Broker 或者新的分区。 | long | 300000 | [0,…] | low |
| metric.reporters | 用于指标监控报表的类清单。实现org.apache.kafka.common.metrics.MetricsReporter接口之后允许插入能够通知新的创建度量的类。JmxReporter 总是包含在注册的 JMX 统计信息中。 |
list | ”” | low | |
| metrics.num.samples | 计算 metrics 所需要维持的样本数量。 | int | 2 | [1,…] | low |
| metrics.recording.level | metrics 的最高纪录级别。 | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | 计算 metrics 样本的时间窗口。 | long | 30000 | [0,…] | low |
| reconnect.backoff.max.ms | 当重新连接到一台多次连接失败的 Broker 时允许等待的最大毫秒数。如果配置该参数,则每台主机的 backoff 将呈指数级增长直到达到配置的最大值。当统计到 backoff 在增长,系统会增加20%的随机波动以避免大量的连接失败。 | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | 在尝试重新连接到给定的主机之前,需要等待的基本时间。这避免了在一个紧凑的循环中反复连接到同一个主机。这个 backoff 机制应用于所有客户端尝试连接到 Broker 的请求。 | long | 50 | [0,…] | low |
| retry.backoff.ms | 在尝试将一个失败的请求重试到给定的 topic 分区之前需要等待的时间。这避免在某些失败场景下在紧凑的循环中重复发送请求。 | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit 命令的路径。 | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | 重新尝试登陆之前,登录线程的休眠时间。 | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | 随机抖动增加到更新时间的百分比。 | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | 登录线程将持续休眠直到上一次刷新到 ticket 的过期时间窗口,在此时间窗口它将尝试更新 ticket 。 | double | 0.8 | low | |
| ssl.cipher.suites | 密码套件列表。密码套件是利用 TLS 或 SSL 网络协议来实现网络连接的安全设置,是一个涵盖认证,加密,MAC和密钥交换算法的组合。默认情况下,支持所有可用的密码套件。 | list | null | low | |
| ssl.endpoint.identification.algorithm | 使用服务器证书验证服务器主机名的 endpoint 识别算法。 | string | null | low | |
| ssl.keymanager.algorithm | key manager factory 用于 SSL 连接的算法。默认值是Java虚拟机配置的 key manager factory 算法。 | string | SunX509 | low | |
| ssl.secure.random.implementation | 用于 SSL 加密操作的 SecureRandom PRNG 实现。 | string | null | low | |
| ssl.trustmanager.algorithm | trust manager factory 用于SSL连接的算法。默认值是Java虚拟机配置的 trust manager factory 算法。 | string | PKIX | low | |
| transaction.timeout.ms | 主动中止进行中的事务之前,事务协调器等待 Producer 更新事务状态的最长时间(以毫秒为单位)。如果此值大于 Broker 中的 max.transaction.timeout.ms 设置的时长,则请求将失败并提示”InvalidTransactionTimeout”错误。 | int | 60000 | low | |
| transactional.id | 用于事务交付的 TransactionalId。 这使跨越多个生产者会话的可靠性语义成为可能,因为它可以保证客户在开始任何新的事务之前,使用相同的 TransactionalId 的事务都已经完成。 如果没有提供 TransactionalId ,则 Producer 被限制为幂等递送。 请注意,如果配置了 TransactionalId,则必须启用 enable.idempotence 。 缺省值为空,这意味着无法使用事务。 | string | null | non-empty string | low |
2.4.4 Consumer 配置
| NAME | DESCRIPTION | TYPE | DEFAULT | VALID VALUES | IMPORTANCE |
|---|---|---|---|---|---|
| bootstrap.servers | A list of host/port pairs to use for establishing the initial connection to the Kafka cluster. The client will make use of all servers irrespective of which servers are specified here for bootstrapping—this list only impacts the initial hosts used to discover the full set of servers. This list should be in the form host1:port1,host2:port2,.... Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list need not contain the full set of servers (you may want more than one, though, in case a server is down). |
list | high | ||
| key.deserializer | Deserializer class for key that implements the org.apache.kafka.common.serialization.Deserializer interface. |
class | high | ||
| value.deserializer | Deserializer class for value that implements the org.apache.kafka.common.serialization.Deserializer interface. |
class | high | ||
| fetch.min.bytes | The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request. The default setting of 1 byte means that fetch requests are answered as soon as a single byte of data is available or the fetch request times out waiting for data to arrive. Setting this to something greater than 1 will cause the server to wait for larger amounts of data to accumulate which can improve server throughput a bit at the cost of some additional latency. | int | 1 | [0,…] | high |
| group.id | A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using subscribe(topic) or the Kafka-based offset management strategy. |
string | ”” | high | |
| heartbeat.interval.ms | The expected time between heartbeats to the consumer coordinator when using Kafka’s group management facilities. Heartbeats are used to ensure that the consumer’s session stays active and to facilitate rebalancing when new consumers join or leave the group. The value must be set lower than session.timeout.ms, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalances. |
int | 3000 | high | |
| max.partition.fetch.bytes | The maximum amount of data per-partition the server will return. Records are fetched in batches by the consumer. If the first record batch in the first non-empty partition of the fetch is larger than this limit, the batch will still be returned to ensure that the consumer can make progress. The maximum record batch size accepted by the broker is defined via message.max.bytes(broker config) or max.message.bytes(topic config). See fetch.max.bytes for limiting the consumer request size. |
int | 1048576 | [0,…] | high |
| session.timeout.ms | The timeout used to detect consumer failures when using Kafka’s group management facility. The consumer sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove this consumer from the group and initiate a rebalance. Note that the value must be in the allowable range as configured in the broker configuration by group.min.session.timeout.msand group.max.session.timeout.ms. |
int | 10000 | high | |
| ssl.key.password | The password of the private key in the key store file. This is optional for client. | password | null | high | |
| ssl.keystore.location | The location of the key store file. This is optional for client and can be used for two-way authentication for client. | string | null | high | |
| ssl.keystore.password | The store password for the key store file. This is optional for client and only needed if ssl.keystore.location is configured. | password | null | high | |
| ssl.truststore.location | The location of the trust store file. | string | null | high | |
| ssl.truststore.password | The password for the trust store file. If a password is not set access to the truststore is still available, but integrity checking is disabled. | password | null | high | |
| auto.offset.reset | What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted):earliest: automatically reset the offset to the earliest offsetlatest: automatically reset the offset to the latest offsetnone: throw exception to the consumer if no previous offset is found for the consumer’s groupanything else: throw exception to the consumer. | string | latest | [latest, earliest, none] | medium |
| connections.max.idle.ms | Close idle connections after the number of milliseconds specified by this config. | long | 540000 | medium | |
| enable.auto.commit | If true the consumer’s offset will be periodically committed in the background. | boolean | true | medium | |
| exclude.internal.topics | Whether records from internal topics (such as offsets) should be exposed to the consumer. If set to truethe only way to receive records from an internal topic is subscribing to it. |
boolean | true | medium | |
| fetch.max.bytes | The maximum amount of data the server should return for a fetch request. Records are fetched in batches by the consumer, and if the first record batch in the first non-empty partition of the fetch is larger than this value, the record batch will still be returned to ensure that the consumer can make progress. As such, this is not a absolute maximum. The maximum record batch size accepted by the broker is defined via message.max.bytes(broker config) or max.message.bytes(topic config). Note that the consumer performs multiple fetches in parallel. |
int | 52428800 | [0,…] | medium |
| isolation.level | Controls how to read messages written transactionally. If set to read_committed, consumer.poll() will only return transactional messages which have been committed. If set to read_uncommitted’ (the default), consumer.poll() will return all messages, even transactional messages which have been aborted. Non-transactional messages will be returned unconditionally in either mode.Messages will always be returned in offset order. Hence, inread_committedmode, consumer.poll() will only return messages up to the last stable offset (LSO), which is the one less than the offset of the first open transaction. In particular any messages appearing after messages belonging to ongoing transactions will be withheld until the relevant transaction has been completed. As a result, read_committedconsumers will not be able to read up to the high watermark when there are in flight transactions.Further, when in read_committed the seekToEnd method will return the LSO |
string | read_uncommitted | [read_committed, read_uncommitted] | medium |
| max.poll.interval.ms | The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. | int | 300000 | [1,…] | medium |
| max.poll.records | The maximum number of records returned in a single call to poll(). | int | 500 | [1,…] | medium |
| partition.assignment.strategy | The class name of the partition assignment strategy that the client will use to distribute partition ownership amongst consumer instances when group management is used | list | class org.apache.kafka.clients.consumer.RangeAssignor | medium | |
| receive.buffer.bytes | The size of the TCP receive buffer (SO_RCVBUF) to use when reading data. If the value is -1, the OS default will be used. | int | 65536 | [-1,…] | medium |
| request.timeout.ms | The configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted. | int | 305000 | [0,…] | medium |
| sasl.jaas.config | JAAS login context parameters for SASL connections in the format used by JAAS configuration files. JAAS configuration file format is described here. The format for the value is: ‘(=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | The Kerberos principal name that Kafka runs as. This can be defined either in Kafka’s JAAS config or in Kafka’s config. | string | null | medium | |
| sasl.mechanism | SASL mechanism used for client connections. This may be any mechanism for which a security provider is available. GSSAPI is the default mechanism. | string | GSSAPI | medium | |
| security.protocol | Protocol used to communicate with brokers. Valid values are: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL. | string | PLAINTEXT | medium | |
| send.buffer.bytes | The size of the TCP send buffer (SO_SNDBUF) to use when sending data. If the value is -1, the OS default will be used. | int | 131072 | [-1,…] | medium |
| ssl.enabled.protocols | The list of protocols enabled for SSL connections. | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | The file format of the key store file. This is optional for client. | string | JKS | medium | |
| ssl.protocol | The SSL protocol used to generate the SSLContext. Default setting is TLS, which is fine for most cases. Allowed values in recent JVMs are TLS, TLSv1.1 and TLSv1.2. SSL, SSLv2 and SSLv3 may be supported in older JVMs, but their usage is discouraged due to known security vulnerabilities. | string | TLS | medium | |
| ssl.provider | The name of the security provider used for SSL connections. Default value is the default security provider of the JVM. | string | null | medium | |
| ssl.truststore.type | The file format of the trust store file. | string | JKS | medium | |
| auto.commit.interval.ms | The frequency in milliseconds that the consumer offsets are auto-committed to Kafka if enable.auto.commitis set to true. |
int | 5000 | [0,…] | low |
| check.crcs | Automatically check the CRC32 of the records consumed. This ensures no on-the-wire or on-disk corruption to the messages occurred. This check adds some overhead, so it may be disabled in cases seeking extreme performance. | boolean | true | low | |
| client.id | An id string to pass to the server when making requests. The purpose of this is to be able to track the source of requests beyond just ip/port by allowing a logical application name to be included in server-side request logging. | string | ”” | low | |
| fetch.max.wait.ms | The maximum amount of time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy the requirement given by fetch.min.bytes. | int | 500 | [0,…] | low |
| interceptor.classes | A list of classes to use as interceptors. Implementing the org.apache.kafka.clients.consumer.ConsumerInterceptorinterface allows you to intercept (and possibly mutate) records received by the consumer. By default, there are no interceptors. |
list | null | low | |
| metadata.max.age.ms | The period of time in milliseconds after which we force a refresh of metadata even if we haven’t seen any partition leadership changes to proactively discover any new brokers or partitions. | long | 300000 | [0,…] | low |
| metric.reporters | A list of classes to use as metrics reporters. Implementing the org.apache.kafka.common.metrics.MetricsReporterinterface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics. |
list | ”” | low | |
| metrics.num.samples | The number of samples maintained to compute metrics. | int | 2 | [1,…] | low |
| metrics.recording.level | The highest recording level for metrics. | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | long | 30000 | [0,…] | low |
| reconnect.backoff.max.ms | The maximum amount of time in milliseconds to wait when reconnecting to a broker that has repeatedly failed to connect. If provided, the backoff per host will increase exponentially for each consecutive connection failure, up to this maximum. After calculating the backoff increase, 20% random jitter is added to avoid connection storms. | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | The base amount of time to wait before attempting to reconnect to a given host. This avoids repeatedly connecting to a host in a tight loop. This backoff applies to all connection attempts by the client to a broker. | long | 50 | [0,…] | low |
| retry.backoff.ms | The amount of time to wait before attempting to retry a failed request to a given topic partition. This avoids repeatedly sending requests in a tight loop under some failure scenarios. | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit command path. | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | Login thread sleep time between refresh attempts. | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | Percentage of random jitter added to the renewal time. | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | Login thread will sleep until the specified window factor of time from last refresh to ticket’s expiry has been reached, at which time it will try to renew the ticket. | double | 0.8 | low | |
| ssl.cipher.suites | A list of cipher suites. This is a named combination of authentication, encryption, MAC and key exchange algorithm used to negotiate the security settings for a network connection using TLS or SSL network protocol. By default all the available cipher suites are supported. | list | null | low | |
| ssl.endpoint.identification.algorithm | The endpoint identification algorithm to validate server hostname using server certificate. | string | null | low | |
| ssl.keymanager.algorithm | The algorithm used by key manager factory for SSL connections. Default value is the key manager factory algorithm configured for the Java Virtual Machine. | string | SunX509 | low | |
| ssl.secure.random.implementation | The SecureRandom PRNG implementation to use for SSL cryptography operations. | string | null | low | |
| ssl.trustmanager.algorithm | The algorithm used by trust manager factory for SSL connections. Default value is the trust manager factory algorithm configured for the Java Virtual Machine. | string | PKIX | low |
2.4.5 Connect配置
| NAME | DESCRIPTION | TYPE | DEFAULT | VALID VALUES | IMPORTANCE |
|---|---|---|---|---|---|
| config.storage.topic | The name of the Kafka topic where connector configurations are stored | string | high | ||
| group.id | A unique string that identifies the Connect cluster group this worker belongs to. | string | high | ||
| key.converter | Converter class used to convert between Kafka Connect format and the serialized form that is written to Kafka. This controls the format of the keys in messages written to or read from Kafka, and since this is independent of connectors it allows any connector to work with any serialization format. Examples of common formats include JSON and Avro. | class | high | ||
| offset.storage.topic | The name of the Kafka topic where connector offsets are stored | string | high | ||
| status.storage.topic | The name of the Kafka topic where connector and task status are stored | string | high | ||
| value.converter | Converter class used to convert between Kafka Connect format and the serialized form that is written to Kafka. This controls the format of the values in messages written to or read from Kafka, and since this is independent of connectors it allows any connector to work with any serialization format. Examples of common formats include JSON and Avro. | class | high | ||
| internal.key.converter | Converter class used to convert between Kafka Connect format and the serialized form that is written to Kafka. This controls the format of the keys in messages written to or read from Kafka, and since this is independent of connectors it allows any connector to work with any serialization format. Examples of common formats include JSON and Avro. This setting controls the format used for internal bookkeeping data used by the framework, such as configs and offsets, so users can typically use any functioning Converter implementation. | class | low | ||
| internal.value.converter | Converter class used to convert between Kafka Connect format and the serialized form that is written to Kafka. This controls the format of the values in messages written to or read from Kafka, and since this is independent of connectors it allows any connector to work with any serialization format. Examples of common formats include JSON and Avro. This setting controls the format used for internal bookkeeping data used by the framework, such as configs and offsets, so users can typically use any functioning Converter implementation. | class | low | ||
| bootstrap.servers | A list of host/port pairs to use for establishing the initial connection to the Kafka cluster. The client will make use of all servers irrespective of which servers are specified here for bootstrapping—this list only impacts the initial hosts used to discover the full set of servers. This list should be in the form host1:port1,host2:port2,.... Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list need not contain the full set of servers (you may want more than one, though, in case a server is down). |
list | localhost:9092 | high | |
| heartbeat.interval.ms | The expected time between heartbeats to the group coordinator when using Kafka’s group management facilities. Heartbeats are used to ensure that the worker’s session stays active and to facilitate rebalancing when new members join or leave the group. The value must be set lower than session.timeout.ms, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalances. |
int | 3000 | high | |
| rebalance.timeout.ms | The maximum allowed time for each worker to join the group once a rebalance has begun. This is basically a limit on the amount of time needed for all tasks to flush any pending data and commit offsets. If the timeout is exceeded, then the worker will be removed from the group, which will cause offset commit failures. | int | 60000 | high | |
| session.timeout.ms | The timeout used to detect worker failures. The worker sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove the worker from the group and initiate a rebalance. Note that the value must be in the allowable range as configured in the broker configuration by group.min.session.timeout.msand group.max.session.timeout.ms. |
int | 10000 | high | |
| ssl.key.password | The password of the private key in the key store file. This is optional for client. | password | null | high | |
| ssl.keystore.location | The location of the key store file. This is optional for client and can be used for two-way authentication for client. | string | null | high | |
| ssl.keystore.password | The store password for the key store file. This is optional for client and only needed if ssl.keystore.location is configured. | password | null | high | |
| ssl.truststore.location | The location of the trust store file. | string | null | high | |
| ssl.truststore.password | The password for the trust store file. If a password is not set access to the truststore is still available, but integrity checking is disabled. | password | null | high | |
| connections.max.idle.ms | Close idle connections after the number of milliseconds specified by this config. | long | 540000 | medium | |
| receive.buffer.bytes | The size of the TCP receive buffer (SO_RCVBUF) to use when reading data. If the value is -1, the OS default will be used. | int | 32768 | [0,…] | medium |
| request.timeout.ms | The configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted. | int | 40000 | [0,…] | medium |
| sasl.jaas.config | JAAS login context parameters for SASL connections in the format used by JAAS configuration files. JAAS configuration file format is described here. The format for the value is: ‘(=)*;’ | password | null | medium | |
| sasl.kerberos.service.name | The Kerberos principal name that Kafka runs as. This can be defined either in Kafka’s JAAS config or in Kafka’s config. | string | null | medium | |
| sasl.mechanism | SASL mechanism used for client connections. This may be any mechanism for which a security provider is available. GSSAPI is the default mechanism. | string | GSSAPI | medium | |
| security.protocol | Protocol used to communicate with brokers. Valid values are: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL. | string | PLAINTEXT | medium | |
| send.buffer.bytes | The size of the TCP send buffer (SO_SNDBUF) to use when sending data. If the value is -1, the OS default will be used. | int | 131072 | [0,…] | medium |
| ssl.enabled.protocols | The list of protocols enabled for SSL connections. | list | TLSv1.2,TLSv1.1,TLSv1 | medium | |
| ssl.keystore.type | The file format of the key store file. This is optional for client. | string | JKS | medium | |
| ssl.protocol | The SSL protocol used to generate the SSLContext. Default setting is TLS, which is fine for most cases. Allowed values in recent JVMs are TLS, TLSv1.1 and TLSv1.2. SSL, SSLv2 and SSLv3 may be supported in older JVMs, but their usage is discouraged due to known security vulnerabilities. | string | TLS | medium | |
| ssl.provider | The name of the security provider used for SSL connections. Default value is the default security provider of the JVM. | string | null | medium | |
| ssl.truststore.type | The file format of the trust store file. | string | JKS | medium | |
| worker.sync.timeout.ms | When the worker is out of sync with other workers and needs to resynchronize configurations, wait up to this amount of time before giving up, leaving the group, and waiting a backoff period before rejoining. | int | 3000 | medium | |
| worker.unsync.backoff.ms | When the worker is out of sync with other workers and fails to catch up within worker.sync.timeout.ms, leave the Connect cluster for this long before rejoining. | int | 300000 | medium | |
| access.control.allow.methods | Sets the methods supported for cross origin requests by setting the Access-Control-Allow-Methods header. The default value of the Access-Control-Allow-Methods header allows cross origin requests for GET, POST and HEAD. | string | ”” | low | |
| access.control.allow.origin | Value to set the Access-Control-Allow-Origin header to for REST API requests.To enable cross origin access, set this to the domain of the application that should be permitted to access the API, or ‘*’ to allow access from any domain. The default value only allows access from the domain of the REST API. | string | ”” | low | |
| client.id | An id string to pass to the server when making requests. The purpose of this is to be able to track the source of requests beyond just ip/port by allowing a logical application name to be included in server-side request logging. | string | ”” | low | |
| config.storage.replication.factor | Replication factor used when creating the configuration storage topic | short | 3 | [1,…] | low |
| metadata.max.age.ms | The period of time in milliseconds after which we force a refresh of metadata even if we haven’t seen any partition leadership changes to proactively discover any new brokers or partitions. | long | 300000 | [0,…] | low |
| metric.reporters | A list of classes to use as metrics reporters. Implementing the org.apache.kafka.common.metrics.MetricsReporterinterface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics. |
list | ”” | low | |
| metrics.num.samples | The number of samples maintained to compute metrics. | int | 2 | [1,…] | low |
| metrics.recording.level | The highest recording level for metrics. | string | INFO | [INFO, DEBUG] | low |
| metrics.sample.window.ms | The window of time a metrics sample is computed over. | long | 30000 | [0,…] | low |
| offset.flush.interval.ms | Interval at which to try committing offsets for tasks. | long | 60000 | low | |
| offset.flush.timeout.ms | Maximum number of milliseconds to wait for records to flush and partition offset data to be committed to offset storage before cancelling the process and restoring the offset data to be committed in a future attempt. | long | 5000 | low | |
| offset.storage.partitions | The number of partitions used when creating the offset storage topic | int | 25 | [1,…] | low |
| offset.storage.replication.factor | Replication factor used when creating the offset storage topic | short | 3 | [1,…] | low |
| plugin.path | List of paths separated by commas (,) that contain plugins (connectors, converters, transformations). The list should consist of top level directories that include any combination of: a) directories immediately containing jars with plugins and their dependencies b) uber-jars with plugins and their dependencies c) directories immediately containing the package directory structure of classes of plugins and their dependencies Note: symlinks will be followed to discover dependencies or plugins. Examples: plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors | list | null | low | |
| reconnect.backoff.max.ms | The maximum amount of time in milliseconds to wait when reconnecting to a broker that has repeatedly failed to connect. If provided, the backoff per host will increase exponentially for each consecutive connection failure, up to this maximum. After calculating the backoff increase, 20% random jitter is added to avoid connection storms. | long | 1000 | [0,…] | low |
| reconnect.backoff.ms | The base amount of time to wait before attempting to reconnect to a given host. This avoids repeatedly connecting to a host in a tight loop. This backoff applies to all connection attempts by the client to a broker. | long | 50 | [0,…] | low |
| rest.advertised.host.name | If this is set, this is the hostname that will be given out to other workers to connect to. | string | null | low | |
| rest.advertised.port | If this is set, this is the port that will be given out to other workers to connect to. | int | null | low | |
| rest.host.name | Hostname for the REST API. If this is set, it will only bind to this interface. | string | null | low | |
| rest.port | Port for the REST API to listen on. | int | 8083 | low | |
| retry.backoff.ms | The amount of time to wait before attempting to retry a failed request to a given topic partition. This avoids repeatedly sending requests in a tight loop under some failure scenarios. | long | 100 | [0,…] | low |
| sasl.kerberos.kinit.cmd | Kerberos kinit command path. | string | /usr/bin/kinit | low | |
| sasl.kerberos.min.time.before.relogin | Login thread sleep time between refresh attempts. | long | 60000 | low | |
| sasl.kerberos.ticket.renew.jitter | Percentage of random jitter added to the renewal time. | double | 0.05 | low | |
| sasl.kerberos.ticket.renew.window.factor | Login thread will sleep until the specified window factor of time from last refresh to ticket’s expiry has been reached, at which time it will try to renew the ticket. | double | 0.8 | low | |
| ssl.cipher.suites | A list of cipher suites. This is a named combination of authentication, encryption, MAC and key exchange algorithm used to negotiate the security settings for a network connection using TLS or SSL network protocol. By default all the available cipher suites are supported. | list | null | low | |
| ssl.endpoint.identification.algorithm | The endpoint identification algorithm to validate server hostname using server certificate. | string | null | low | |
| ssl.keymanager.algorithm | The algorithm used by key manager factory for SSL connections. Default value is the key manager factory algorithm configured for the Java Virtual Machine. | string | SunX509 | low | |
| ssl.secure.random.implementation | The SecureRandom PRNG implementation to use for SSL cryptography operations. | string | null | low | |
| ssl.trustmanager.algorithm | The algorithm used by trust manager factory for SSL connections. Default value is the trust manager factory algorithm configured for the Java Virtual Machine. | string | PKIX | low | |
| status.storage.partitions | The number of partitions used when creating the status storage topic | int | 5 | [1,…] | low |
| status.storage.replication.factor | Replication factor used when creating the status storage topic | short | 3 | [1,…] | low |
| task.shutdown.graceful.timeout.ms | Amount of time to wait for tasks to shutdown gracefully. This is the total amount of time, not per task. All task have shutdown triggered, then they are waited on sequentially. | long | 5000 | low |
2.4.6 Streams配置
http://kafka.apache.org/documentation/#streamsconfigs
2.4.7 AdminClient配置
http://kafka.apache.org/documentation/#adminclientconfigs
2.5 设计思想
2.5.1 动机
我们设计的 Kafka 能够作为一个统一的平台来处理大公司可能拥有的所有实时数据馈送。 要做到这点,我们必须考虑相当广泛的用例。
Kafka 必须具有高吞吐量来支持高容量事件流,例如实时日志聚合。
Kafka 需要能够正常处理大量的数据积压,以便能够支持来自离线系统的周期性数据加载。
这也意味着系统必须处理低延迟分发,来处理更传统的消息传递用例。
我们希望支持对这些馈送进行分区,分布式,以及实时处理来创建新的分发馈送等特性。由此产生了我们的分区模式和消费者模式。
最后,在数据流被推送到其他数据系统进行服务的情况下,我们要求系统在出现机器故障时必须能够保证容错。
为支持这些使用场景导致我们设计了一些独特的元素,使得 Kafka 相比传统的消息系统更像是数据库日志。我们将在后面的章节中概述设计中的部分要素。
2.5.2 持久化
使用文件系统
设计合理的磁盘结构通常可以和网络一样快。使用6个7200rpm、SATA接口、RAID-5的磁盘阵列在JBOD配置下的顺序写入的性能约为600MB/秒,但随机写入的性能仅约为100k/秒,相差6000倍以上。因为线性的读取和写入是磁盘使用模式中最有规律的,并且由操作系统进行了大量的优化。现代操作系统提供了 read-ahead 和 write-behind 技术,read-ahead 是以大的 data block 为单位预先读取数据,而 write-behind 是将多个小型的逻辑写合并成一次大型的物理磁盘写入。
为了弥补这种性能差异,现代操作系统在越来越注重使用内存对磁盘进行 cache。现代操作系统主动将所有空闲内存用作 disk caching,代价是在内存回收时性能会有所降低。所有对磁盘的读写操作都会通过这个统一的 cache。如果不使用直接I/O,该功能不能轻易关闭。因此即使进程维护了 in-process cache,该数据也可能会被复制到操作系统的 pagecache 中,事实上所有内容都被存储了两份。
此外,Kafka 建立在 JVM 之上,任何了解 Java 内存使用的人都知道两点:
- 对象的内存开销非常高,通常是所存储的数据的两倍(甚至更多)。
- 随着堆中数据的增加,Java 的垃圾回收变得越来越复杂和缓慢。
受这些因素影响,相比于维护 in-memory cache 或者其他结构,使用文件系统和 pagecache 显得更有优势–我们可以通过自动访问所有空闲内存将可用缓存的容量至少翻倍,并且通过存储紧凑的字节结构而不是独立的对象,有望将缓存容量再翻一番。 这样使得32GB的机器缓存容量可以达到28-30GB,并且不会产生额外的 GC 负担。此外,即使服务重新启动,缓存依旧可用,而 in-process cache 则需要在内存中重建(重建一个10GB的缓存可能需要10分钟),否则进程就要从 cold cache 的状态开始(这意味着进程最初的性能表现十分糟糕)。 这同时也极大的简化了代码,因为所有保持 cache 和文件系统之间一致性的逻辑现在都被放到了 OS 中,这样做比一次性的进程内缓存更准确、更高效。如果你的磁盘使用更倾向于顺序读取,那么 read-ahead 可以有效的使用每次从磁盘中读取到的有用数据预先填充 cache。
这里给出了一个非常简单的设计:相比于维护尽可能多的 in-memory cache,并且在空间不足的时候匆忙将数据 flush 到文件系统,我们把这个过程倒过来。所有数据一开始就被写入到文件系统的持久化日志中,而不用在 cache 空间不足的时候 flush 到磁盘。实际上,这表明数据被转移到了内核的 pagecache 中。
这种 pagecache-centric 的设计风格出现在一篇关于 Varnish 设计的文章中。
常量时间
消息系统使用的持久化数据结构通常是和 BTree 相关联的消费者队列或者其他用于存储消息源数据的通用随机访问数据结构。BTree 是最通用的数据结构,可以在消息系统能够支持各种事务性和非事务性语义。 虽然 BTree 的操作复杂度是 O(log N),但成本也相当高。通常我们认为 O(log N) 基本等同于常数时间,但这条在磁盘操作中不成立。磁盘寻址是每10ms一跳,并且每个磁盘同时只能执行一次寻址,因此并行性受到了限制。 因此即使是少量的磁盘寻址也会很高的开销。由于存储系统将非常快的cache操作和非常慢的物理磁盘操作混合在一起,当数据随着 fixed cache 增加时,可以看到树的性能通常是非线性的——比如数据翻倍时性能下降不只两倍。
所以直观来看,持久化队列可以建立在简单的读取和向文件后追加两种操作之上,这和日志解决方案相同。这种架构的优点在于所有的操作复杂度都是O(1),而且读操作不会阻塞写操作,读操作之间也不会互相影响。这有着明显的性能优势,由于性能和数据大小完全分离开来——服务器现在可以充分利用大量廉价、低转速的1+TB SATA硬盘。 虽然这些硬盘的寻址性能很差,但他们在大规模读写方面的性能是可以接受的,而且价格是原来的三分之一、容量是原来的三倍。
在不产生任何性能损失的情况下能够访问几乎无限的硬盘空间,这意味着我们可以提供一些其它消息系统不常见的特性。例如:在 Kafka 中,我们可以让消息保留相对较长的一段时间(比如一周),而不是试图在被消费后立即删除。正如我们后面将要提到的,这给消费者带来了很大的灵活性。
2.5.3 效率
我们在性能上已经做了很大的努力。 我们主要的使用场景是处理WEB活动数据,这个数据量非常大,因为每个页面都有可能大量的写入。此外我们假设每个发布 message 至少被一个consumer (通常很多个consumer) 消费, 因此我们尽可能的去降低消费的代价。
我们还发现,从构建和运行许多相似系统的经验上来看,性能是多租户运营的关键。如果下游的基础设施服务很轻易被应用层冲击形成瓶颈,那么一些小的改变也会造成问题。通过非常快的(缓存)技术,我们能确保应用层冲击基础设施之前,将负载稳定下来。 当尝试去运行支持集中式集群上成百上千个应用程序的集中式服务时,这一点很重要,因为应用层使用方式几乎每天都会发生变化。
我们在上一节讨论了磁盘性能。 一旦消除了磁盘访问模式不佳的情况,该类系统性能低下的主要原因就剩下了两个:大量的小型 I/O 操作,以及过多的字节拷贝。
-
小型的 I/O 操作发生在客户端和服务端之间以及服务端自身的持久化操作中。
为了避免这种情况,我们的协议是建立在一个 “消息块” 的抽象基础上,合理将消息分组。 这使得网络请求将多个消息打包成一组,而不是每次发送一条消息,从而使整组消息分担网络中往返的开销。Consumer 每次获取多个大型有序的消息块,并由服务端 依次将消息块一次加载到它的日志中。
这个简单的优化对速度有着数量级的提升。批处理允许更大的网络数据包,更大的顺序读写磁盘操作,连续的内存块等等,所有这些都使 KafKa 将随机流消息顺序写入到磁盘, 再由 consumers 进行消费。
-
另一个低效率的操作是字节拷贝
在消息量少时,这不是什么问题。但是在高负载的情况下,影响就不容忽视。为了避免这种情况,我们使用 producer ,broker 和 consumer 都共享的标准化的二进制消息格式,这样数据块不用修改就能在他们之间传递。
broker 维护的消息日志本身就是一个文件目录,每个文件都由一系列以相同格式写入到磁盘的消息集合组成,这种写入格式被 producer 和 consumer 共用。保持这种通用格式可以对一些很重要的操作进行优化: 持久化日志块的网络传输。 现代的unix 操作系统提供了一个高度优化的编码方式,用于将数据从 pagecache 转移到 socket 网络连接中;在 Linux 中系统调用 sendfile 做到这一点。
为了理解 sendfile 的意义,了解数据从文件到套接字的常见数据传输路径就非常重要:
- 操作系统从磁盘读取数据到内核空间的 pagecache
- 应用程序读取内核空间的数据到用户空间的缓冲区
- 应用程序将数据(用户空间的缓冲区)写回内核空间到套接字缓冲区(内核空间)
- 操作系统将数据从套接字缓冲区(内核空间)复制到通过网络发送的 NIC 缓冲区
这显然是低效的,有四次 copy 操作和两次系统调用。使用 sendfile 方法,可以允许操作系统将数据从 pagecache 直接发送到网络,这样避免重新复制数据。所以这种优化方式,只需要最后一步的copy操作,将数据复制到 NIC 缓冲区。
我们期望一个普遍的应用场景,一个 topic 被多消费者消费。使用上面提交的 zero-copy(零拷贝)优化,数据在使用时只会被复制到 pagecache 中一次,节省了每次拷贝到用户空间内存中,再从用户空间进行读取的消耗。这使得消息能够以接近网络连接速度的 上限进行消费。
pagecache 和 sendfile 的组合使用意味着,在一个kafka集群中,大多数 consumer 消费时,您将看不到磁盘上的读取活动,因为数据将完全由缓存提供。
JAVA 中更多有关 sendfile 方法和 zero-copy (零拷贝)相关的资料,可以参考这里的 文章。
-
网络带宽限制
Kafka 以高效的批处理格式支持一批消息可以压缩在一起发送到服务器。这批消息将以压缩格式写入,并且在日志中保持压缩,只会在 consumer 消费时解压缩。
2.5.4 生产者
负载均衡
生产者直接发送数据到主分区的服务器上,不需要经过任何中间路由。 为了让生产者实现这个功能,所有的 kafka 服务器节点都能响应这样的元数据请求: 哪些服务器是活着的,主题的哪些分区是主分区,分配在哪个服务器上,这样生产者就能适当地直接发送它的请求到服务器上。
客户端控制消息发送数据到哪个分区,这个可以实现随机的负载均衡方式,或者使用一些特定语义的分区函数。 我们有提供特定分区的接口让用于根据指定的键值进行hash分区(当然也有选项可以重写分区函数),例如,如果使用用户ID作为key,则用户相关的所有数据都会被分发到同一个分区上。 这允许消费者在消费数据时做一些特定的本地化处理。这样的分区风格经常被设计用于一些本地处理比较敏感的消费者。
理解:通过设置不同的服务器为leader,实现不同的服务直接访问不同的服务器,闲时再同步partition。
异步发送
批处理是提升性能的一个主要驱动,为了允许批量处理,kafka 生产者会尝试在内存中汇总数据,并用一次请求批次提交信息。 批处理,不仅仅可以配置指定的消息数量,也可以指定等待特定的延迟时间(如64k 或10ms),这允许汇总更多的数据后再发送,在服务器端也会减少更多的IO操作。 该缓冲是可配置的,并给出了一个机制,通过权衡少量额外的延迟时间获取更好的吞吐量。
2.5.5 消费者
Kafka consumer通过向 broker 发出一个“fetch”请求来获取它想要消费的 partition。consumer 的每个请求都在 log 中指定了对应的 offset,并接收从该位置开始的一大块数据。因此,consumer 对于该位置的控制就显得极为重要,并且可以在需要的时候通过回退到该位置再次消费对应的数据。
Push vs. Pull
consumer从broker处pull数据,还是由broker将数据push到consumer。
Kafka:pull-based,采用传统的consumer从broker中pull数据(当然producer是push到broker的)。
Scribe/Apache Flume:push-based,采用broker主动将数据push到下游节点。
push-based和pull-based的比较:pull-based的优势包括(1)消费者消费速度低于producer的生产速度时,push-based系统的consumer会超载;而pull-based系统的consumer自行pull数据,在生产高峰期也可以保证不会超载,在生产低谷,可以将生产的数据慢慢pull和处理;(2)push-based必须立即发送数据,不知道下游consumer是否能够处理;pull-based可以大批量生产和发送给consumer。pull-based的劣势包括(1)如果 broker 中没有数据,consumer 可能会在一个紧密的循环中结束轮询,实际上 busy-waiting 直到数据到来。
消费者的位置
持续追踪已经被消费的内容是消息系统的关键性能点之一。大多数消息系统都在 broker 上保存被消费消息的元数据。也就是说,当消息被传递给 consumer,broker 要么立即在本地记录该事件,要么等待 consumer 的确认后再记录。
-
broker和consumer保持一致性的问题
问题:如果 broker 在每条消息被发送到网络的时候,立即将其标记为 consumed,那么一旦 consumer 无法处理该消息(可能由 consumer 崩溃或者请求超时或者其他原因导致),该消息就会丢失。
解决方案:
方案1:确认机制——当消息被发送出去的时候,消息仅被标记为sent 而不是 consumed;然后 broker 会等待一个来自 consumer 的特定确认,再将消息标记为consumed。该方案的问题是,(1)如果 consumer 处理了消息但在发送确认之前出错了,那么该消息就会被消费两次;(2)关于性能,现在 broker 必须为每条消息保存多个状态(首先对其加锁,确保该消息只被发送一次,然后将其永久的标记为 consumed,以便将其移除)(3)如何处理已经发送但一直得不到确认的消息。
方案2(Kafka的方案):Kafka的 topic 被分割成了一组完全有序的 partition,其中每一个 partition 在任意给定的时间内只能被每个订阅了这个 topic 的 consumer 组中的一个 consumer 消费。这意味着 partition 中 每一个 consumer 的位置仅仅是一个数字,即下一条要消费的消息的offset。这使得被消费的消息的状态信息相当少,每个 partition 只需要一个数字。这个状态信息还可以作为周期性的 checkpoint。这以非常低的代价实现了和消息确认机制等同的效果。好处是,consumer 可以回退到之前的 offset 来再次消费之前的数据,这个操作违反了队列的基本原则,但事实证明对大多数 consumer 来说这是一个必不可少的特性。例如,如果 consumer 的代码有 bug,并且在 bug 被发现前已经有一部分数据被消费了, 那么 consumer 可以在 bug 修复后通过回退到之前的 offset 来再次消费这些数据。
离线数据加载
可伸缩的持久化特性允许 consumer 只进行周期性的消费,例如批量数据加载,周期性将数据加载到诸如 Hadoop 和关系型数据库之类的离线系统中。
2.5.6 消息交付语义
producer和consumer的语义保证有多种:
- At most once——消息可能会丢失但绝不重传。
- At least once——消息可以重传但绝不丢失。
- Exactly once——这正是人们想要的, 每一条消息只被传递一次.
Kafka的语义(producer角度)
发布消息时,有一个消息的概念被“committed”到 log 中。 一旦producer消息被提交,只要有一个 broker 备份了该消息写入的 partition,并且保持“alive”状态,该消息就不会丢失。
如果一个 producer 在试图发送消息的时候发生了网络故障, 则不确定网络错误发生在消息提交之前还是之后。 以下是处理方法:
0.11.0.0版本之前:如果 producer 没有收到表明消息已经被提交的响应,producer将消息重传。即提供了at-least-once的消息交付语义,因为如果最初的请求事实上执行成功了,那么重传过程中该消息就会被再次写入到 log 当中(导致了该消息的log可能会被写入多次)。
0.11.0.0版本及之后:(1)Kafka producer新增幂等性,该选项保证重传不会在 log 中产生重复条目。为实现这个目的, broker 给每个 producer 都分配了一个 ID ,并且 producer 给每条被发送的消息分配了一个序列号来避免产生重复的消息。(2)producer新增了类似事务的语义将消息发送到多个topic partition,即要么所有的消息都被成功的写入到了 log,要么一个都没写进去。
Kafka的语义(consumer角度)
所有的副本(主partition的复制)都有相同的 log 和相同的 offset。consumer 负责控制它在 log 中的位置。如果 consumer 永远不崩溃,那么它可以将这个位置信息只存储在内存中。但如果 consumer 发生了故障,我们希望这个 topic partition 被另一个进程接管, 那么新进程需要选择一个合适的位置开始进行处理。假设 consumer 要读取一些消息——它有几个处理消息和更新位置选项:
-
at-most-once Consumer 可以先读取消息,然后将它的位置保存到 log 中,最后再对消息进行处理。在这种情况下,消费者进程可能会在保存其位置之后,带还没有保存消息处理的输出之前发生崩溃。而在这种情况下,即使在此位置之前的一些消息没有被处理,接管处理的进程将从保存的位置开始。在 consumer 发生故障的情况下,这对应于“at-most-once”(消息有可能丢失但绝不重传)的语义,可能会有消息得不到处理。
-
at-least-once Consumer 可以先读取消息,然后处理消息,最后再保存它的位置。在这种情况下,消费者进程可能会在处理了消息之后,但还没有保存位置之前发生崩溃。而在这种情况下,当新的进程接管后,它最初收到的一部分消息都已经被处理过了。在 consumer 发生故障的情况下,这对应于“at-least-once”(消息可以重传但绝不丢失。)的语义。 在许多应用场景中,消息都设有一个主键,所以更新操作是幂等的(相同的消息接收两次时,第二次写入会覆盖掉第一次写入的记录)。
-
exactly-once 从一个 kafka topic 中消费并输出到另一个 topic 时 (正如在一个Kafka Streams 应用中所做的那样),我们可以使用我们上文提到的0.11.0.0 及以后版本中的新事务型 producer,并将 consumer 的位置存储为一个 topic 中的消息,所以我们可以在输出 topic 接收已经被处理的数据的时候,在同一个事务中向 Kafka 写入 offset。此事务保证consumer接收消息、处理消息和offset写入均成功进行或者同时不成功。
producer新增了类似事务的语义将消息发送到多个topic partition,即要么所有的消息都被成功的写入到了 log,要么一个都没写进去。
如果事务被中断,则消费者的位置将恢复到原来的值,而输出 topic 上产生的数据对其他消费者是否可见,取决于事务的“隔离级别”。 在默认的“read_uncommitted”隔离级别中,所有消息对 consumer 都是可见的,即使它们是中止的事务的一部分,但是在“read_committed”的隔离级别中,消费者只能访问已提交的事务中的消息(以及任何不属于事务的消息)。
写入外部系统的场景
在写入外部系统的应用场景中,限制在于需要在 consumer 的 offset 与实际存储为输出的内容间进行协调。解决这一问题的经典方法是在 consumer offset 的存储和 consumer 的输出结果的存储之间引入 two-phase commit。但这可以用更简单的方法处理,而且通常的做法是让 consumer 将其 offset 存储在与其输出相同的位置。 这也是一种更好的方式,因为大多数 consumer 想写入的输出系统都不支持 two-phase commit。举个例子,Kafka Connect连接器,它将所读取的数据和数据的 offset 一起写入到 HDFS,以保证数据和 offset 都被更新,或者两者都不被更新。 对于其它很多需要这些较强语义,并且没有主键来避免消息重复的数据系统,我们也遵循类似的模式。
因此,事实上 Kafka 在Kafka Streams中支持了exactly-once 的消息交付功能,并且在 topic 之间进行数据传递和处理时,通常使用事务型 producer/consumer 提供 exactly-once 的消息交付功能。 到其它目标系统的 exactly-once 的消息交付通常需要与该类系统协作,但 Kafka 提供了 offset,使得这种应用场景的实现变得可行。(详见 Kafka Connect)。否则,Kafka 默认保证 at-least-once 的消息交付, 并且 Kafka 允许用户通过禁用 producer 的重传功能和让 consumer 在处理一批消息之前提交 offset,来实现 at-most-once 的消息交付。
2.5.7 Replication
Kafka备份
Kafka 允许 topic 的 partition 拥有若干副本,你可以在server端配置partition 的副本数量。当集群中的节点出现故障时,能自动进行故障转移,保证数据的可用性。
创建副本的单位是 topic 的 partition ,正常情况下, 每个分区都有一个 leader 和零或多个 followers 。 总的副本数是包含 leader 的总和。 所有的读写操作都由 leader 处理(所以要知道Leader的IP和端口,不然通过设置成follower的IP和端口会连接失败),一般 partition 的数量都比 broker 的数量多的多,各分区的 leader 均 匀的分布在brokers 中。所有的 followers 节点都同步 leader 节点的日志,日志中的消息和偏移量(理解:日志包括了消息和偏移量)都和 leader 中的一致。(当然, 在任何给定时间, leader 节点的日志末尾时可能有几个消息尚未被备份完成)。
Followers 节点就像普通的 consumer 那样从 leader 节点那里拉取消息并保存在自己的日志文件中。Followers 节点可以从 l 节点那里批量拉取消息日志到自己的日志文件中。
Kafka分配Replica的算法
1.将所有存活的N个Brokers和待分配的Partition排序
2.将第i个Partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本
3.将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
最终形成以下结果,

Kafka判断节点存活alive的方式
1.节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接。 2.如果节点是个 follower ,它必须能及时的同步 leader 的写操作,并且延时不能太久。
满足这两个条件的节点处于 “in sync” 状态,区别于 “alive” 和 “failed” 。 Leader会追踪所有 “in sync” 的节点。如果有节点挂掉了, 或是写超时, 或是心跳超时, leader 就会把它从同步副本列表中移除。 同步超时和写超时的时间由 replica.lag.time.max.ms 配置确定。
分布式系统中,我们只尝试处理 “fail/recover” 模式的故障,即节点突然停止工作,然后又恢复(节点可能不知道自己曾经挂掉)的状况。Kafka 没有处理所谓的 “Byzantine” 故障,即一个节点出现了随意响应和恶意响应(可能由于 bug 或 非法操作导致)。
备份日志:Quorums,ISRs和状态机
Kafka的核心是备份日志文件(理解:日志包括了消息和偏移量)。备份日志文件是分布式数据系统最基础的要素之一,实现方法也有很多种。其他系统也可以用 kafka 的备份日志模块来实现状态机风格的分布式系统。
如果 leader crash,我们就需要从 follower 中选举出一个新的 leader。 但是 followers 自身也有可能落后或者 crash,所以 我们必须确保我们leader的候选者们 是一个数据同步 最新的 follower 节点。
-
Quorums(Kafka未使用)
Quorums读写机制:如果选择写入时候需要保证一定数量的副本写入成功,读取时需要保证读取一定数量的副本,读取和写入之间有重叠。
实现Quorums的常见方法:对提交决策和 leader 选举使用多数投票机制。Kafka 没有采取这种方式。假设我们有2f + 1个副本,如果在 leader 宣布消息提交之前必须有f+1个副本收到 该消息,并且如果我们从这至少f+1个副本之中,有着最完整的日志记录的 follower 里来选择一个新的 leader,那么在故障次数少于f的情况下,选举出的 leader 保证具有所有提交的消息。这是因为在任意f+1个副本中,至少有一个副本一定包含 了所有提交的消息。该副本的日志将是最完整的,因此将被选为新的 leader。
多数投票的优点是,延迟是取决于最快的(f个,我的理解)服务器。也就是说,如果副本数是3,则备份完成的等待时间取决于最快的 Follwer 。除了Leader,还需要1个备份,最快的服务器响应后,即可满足f+1个副本有着完整的日志记录
多数投票缺点是,故障数f,则需要2f+1份数据(副本),对于处理海量数据问题不切实际。故常用于共享集群配置(如ZooKeeper),而不适用于原始数据存储
-
ISR(Kafka使用)
Kafka 动态维护了一个同步状态的备份的集合 (a set of in-sync replicas), 简称 ISR ,在这个集合中的节点都是和 leader 保持高度一致的,只有这个集合的成员才 有资格被选举为 leader,一条消息必须被这个集合 所有 节点读取并追加到日志中了,这条消息才能视为提交。这个 ISR 集合发生变化会在 ZooKeeper 持久化,正因为如此,这个集合中的任何一个节点都有资格被选为 leader 。这对于 Kafka 使用模型中, 有很多分区和并确保主从关系是很重要的。因为 ISR 模型和 f+1 副本,一个 Kafka topic 冗余 f 个节点故障而不会丢失任何已经提交的消息。
在实际中,为了冗余 f 节点故障,大多数投票和 ISR 都会在提交消息前确认相同数量的备份被收到(例如在一次故障生存之后,大多数的 quorum 需要三个备份节点和一次确认,ISR 只需要两个备份节点和一次确认)
-
分布式算法
- ZooKeeper 的 Zab, Raft, 和 Viewstamped Replication
- Kafka 的ISR模型(来自微软的PacificA)
- Quorums
-
Kafka不要求崩溃的节点恢复所有的数据
另一个重要的设计区别是,Kafka 不要求崩溃的节点恢复所有的数据,在这种空间中的复制算法经常依赖于存在 “稳定存储”,在没有违反潜在的一致性的情况下,出现任何故障再恢复情况下都不会丢失。 这个假设有两个主要的问题。首先,我们在持久性数据系统的实际操作中观察到的最常见的问题是磁盘错误,并且它们通常不能保证数据的完整性。其次,即使磁盘错误不是问题,我们也不希望在每次写入时都要求使用 fsync 来保证一致性, 因为这会使性能降低两到三个数量级。我们的协议能确保备份节点重新加入ISR 之前,即使它挂时没有新的数据, 它也必须完整再一次同步数据。
-
Unclean leader 选举: 如果节点全挂了?
Kafka 对于数据不会丢失的保证,是基于至少一个节点在保持同步状态,一旦分区上的所有备份节点都挂了,就无法保证了。
但是,实际在运行的系统需要去考虑假设一旦所有的备份都挂了,怎么去保证数据不会丢失,这里有两种实现的方法
- 等待一个 ISR 的副本重新恢复正常服务,并选择这个副本作为领 leader (它有极大可能拥有全部数据)。
- 选择第一个重新恢复正常服务的副本(不一定是 ISR 中的)作为leader。
这是可用性和一致性之间的简单妥协,如果我只等待 ISR 的备份节点,那么只要 ISR 备份节点都挂了,我们的服务将一直会不可用,如果它们的数据损坏了或者丢失了,那就会是长久的宕机。另一方面,如果不是 ISR 中的节点恢复服务并且我们允许它成为 leader , 那么它的数据就是可信的来源,即使它不能保证记录了每一个已经提交的消息。 kafka 默认选择第二种策略,当所有的 ISR 副本都挂掉时,会选择一个可能不同步的备份作为 leader ,可以配置属性 unclean.leader.election.enable 禁用此策略,那么就会使用第 一种策略即停机时间优于不同步。
这种困境不只有 Kafka 遇到,它存在于任何 quorum-based 规则中。例如,在大多数投票算法当中,如果大多数服务器永久性的挂了,那么您要么选择丢失100%的数据,要么违背数据的一致性选择一个存活的服务器作为数据可信的来源。
-
可用性和持久性保证
向 Kafka 写数据时,producers 设置 ack 是否提交完成, 0:不等待broker返回确认消息,1: leader保存成功返回或, -1(all): 所有ISR备份都保存成功返回.(不保证ISR之外的备份写入消息)
这确保了分区的最大可用性(备份节点都挂掉时,可以直接采用第一个重新恢复正常服务的副本,不一定是ISR的备份),但是对于偏好数据持久性而不是可用性的一些用户,可能不想用这种策略,因此,我们提供了两个topic 配置,可用于优先配置消息数据持久性:
- 禁用 unclean leader 选举机制 - 如果所有的备份节点都挂了,分区数据就会不可用,直到最近的 leader 恢复正常。这种策略优先于数据丢失的风险, 参看上一节的 unclean leader 选举机制。
- 指定最小的 ISR 集合大小,只有当 ISR 的大小大于最小值,分区才能接受写入操作,以防止仅写入单个备份的消息丢失造成消息不可用的情况,这个设置只有在生产者使用 acks = all 的情况下才会生效,这至少保证消息被 ISR 副本写入。此设置是一致性和可用性 之间的折衷,对于设置更大的最小ISR大小保证了更好的一致性,因为它保证将消息被写入了更多的备份,减少了消息丢失的可能性。但是,这会降低可用性,因为如果 ISR 副本的数量低于最小阈值,那么分区将无法写入。(我的理解,减小ISR内备份数据,降低写入出错的可能)
-
备份管理
以上关于备份日志的讨论只涉及单个日志文件,即一个 topic 分区,事实上,一个Kafka集群管理着成百上千个这样的 partitions。我们尝试以轮询调度的方式将集群内的 partition 负载均衡,避免大量topic拥有的分区集中在 少数几个节点上。同样,我们也试图平衡leadership,以至于每个节点都是部分 partition 的leader节点。
优化主从关系的选举过程也是重要的,这是数据不可用的关键窗口。原始的实现是当有节点挂了后,进行主从关系选举时,会对挂掉节点的所有partition 的领导权重新选举。相反,我们会选择一个 broker 作为 “controller”节点。controller 节点负责 检测 brokers 级别故障,并负责在 broker 故障的情况下更改这个故障 Broker 中的 partition 的 leadership 。这种方式可以批量的通知主从关系的变化,使得对于拥有大量partition 的broker ,选举过程的代价更低并且速度更快。如果 controller 节点挂了,其他 存活的 broker 都可能成为新的 controller 节点。
2.5.8 日志压缩
日志压缩可确保 Kafka 始终至少为单个 topic partition 的数据日志中的每个 message key 保留最新的已知值。 这样的设计解决了应用程序崩溃、系统故障后恢复或者应用在运行维护过程中重启后重新加载缓存的场景。
简单的日志保留方法:当旧的数据保留时间超过指定时间、日志大达到规定大小后就丢弃。这样的策略非常适用于处理那些暂存的数据,例如记录每条消息之间相互独立的日志。 然而在实际使用过程中还有一种非常重要的场景——根据key进行数据变更(例如更改数据库表内容),使用以上的方式显然不行。
假设我们有一个topic,里面的内容包含用户的email地址;每次用户更新他们的email地址时,我们发送一条消息到这个topic,这里使用用户Id作为消息的key值。
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
日志压缩为我提供了更精细的保留机制,所以我们至少保留每个key的最后一次更新 (例如:bill@gmail.com),而不是根据上述简单的日志保留方法(当旧的数据保留时间超过指定时间、日志大达到规定大小后就丢弃)。 这样我们保证日志包含每一个key的最终值而不只是最近变更的完整快照。这意味着下游的消费者可以获得最终的状态而无需拿到所有的变化的消息信息。
几个使用场景:
- 数据库更改订阅。 通常需要在多个数据系统设置拥有一个数据集,这些系统中通常有一个是某种类型的数据库(无论是RDBMS或者新流行的key-value数据库)。 例如,你可能有一个数据库,缓存,搜索引擎集群或者Hadoop集群。每次变更数据库,也同时需要变更缓存、搜索引擎以及hadoop集群。 在只需处理最新日志的实时更新的情况下,你只需要最近的日志。但是,如果你希望能够重新加载缓存或恢复搜索失败的节点,你可能需要一个完整的数据集。
- 事件源。 这是一种应用程序设计风格,它将查询处理与应用程序设计相结合,并使用变更的日志作为应用程序的主要存储。
- 日志高可用。 执行本地计算的进程可以通过注销对其本地状态所做的更改来实现容错,以便另一个进程可以重新加载这些更改并在出现故障时继续进行。 一个具体的例子就是在流查询系统中进行计数,聚合和其他类似“group by”的操作。实时流处理框架Samza, 使用这个特性正是出于这一原因。
我们从一开始就捕获每一次变更。 使用这个完整的日志,我们可以通过回放日志来恢复到任何一个时间点的状态。 然而这种假设的情况下,完整的日志是不实际的,对于那些每一行记录会变更多次的系统,即使数据集很小,日志也会无限的增长下去。 丢弃旧日志的简单操作可以限制空间的增长,但是无法重建状态——因为旧的日志被丢弃,可能一部分记录的状态会无法重建(这些记录所有的状态变更都在旧日志中)。
日志压缩机制是更细粒度的、每个记录都保留的机制,而不是基于时间的粗粒度。 这个理念是选择性的删除那些有更新的变更的记录的日志。 这样最终日志至少包含每个key的记录的最后一个状态。
这个策略可以为每个Topic设置,这样一个集群中,可以一部分Topic通过时间和大小保留日志,另外一些可以通过压缩压缩策略保留。
这个功能的灵感来自于LinkedIn的最古老且最成功的基础设置——一个称为Databus的数据库变更日志缓存系统。 不像大多数的日志存储系统,Kafka是专门为订阅和快速线性的读和写的组织数据。 和Databus不同,Kafka作为真实的存储,压缩日志是非常有用的,这非常有利于上游数据源不能重放的情况。
日志压缩基础
这是一个高级别的日志逻辑图,展示了kafka日志的每条消息的offset逻辑结构。
Log head中包含传统的Kafka日志,它包含了连续的offset和所有的消息。 日志压缩增加了处理tail Log的选项。 上图展示了日志压缩的的Log tail的情况。tail中的消息保存了初次写入时的offset。 即使该offset的消息被压缩,所有offset仍然在日志中是有效的。在这个场景中,无法区分和下一个出现的更高offset的位置。 如上面的例子中,36、37、38是属于相同位置的,从他们开始读取日志都将从38开始。
压缩也允许删除。通过消息的key和空负载(null payload)来标识该消息可从日志中删除。 这个删除标记将会引起所有之前拥有相同key的消息被移除(包括拥有key相同的新消息)。 但是删除标记比较特殊,它将在一定周期后被从日志中删除来释放空间。这个时间点被称为“delete retention point”,如上图。
压缩操作通过在后台周期性的拷贝日志段来完成。 清除操作不会阻塞读取,并且可以被配置不超过一定IO吞吐来避免影响Producer和Consumer。实际的日志段压缩过程有点像这样:
日志压缩的保障措施
- 任何滞留在日志head中的所有消费者能看到写入的所有消息;这些消息都是有序的offset。 topic使用min.compaction.lag.ms来保障消息写入之前必须经过的最小时间长度,才能被压缩。 这限制了一条消息在Log Head中的最短存在时间。
- 始终保持消息的有序性。压缩永远不会重新排序消息,只是删除了一些。
- 消息的Offset不会变更。这是消息在日志中的永久标志。
- 任何从头开始处理日志的Consumer至少会拿到每个key的最终状态。 另外,只要Consumer在小于Topic的delete.retention.ms设置(默认24小时)的时间段内到达Log head,将会看到所有删除记录的所有删除标记。 换句话说,因为移除删除标记和读取是同时发生的,Consumer可能会因为落后超过delete.retention.ms而导致错过删除标记。
日志压缩细节
日志压缩由Log Cleaner执行,后台线程池重新拷贝日志段,移除那些key存在于Log Head中的记录。每个压缩线程如下工作:
- 选择log head与log tail比率最高的日志。
- 在head log中为每个key的最后offset创建一个的简单概要。
- 它从日志的开始到结束,删除那些在日志中最新出现的key的旧的值。新的、干净的日志将会立即被交到到日志中,所以只需要一个额外的日志段空间(不是日志的完整副本)
- 日志head的概要本质上是一个空间密集型的哈希表,每个条目使用24个字节。所以如果有8G的整理缓冲区, 则能迭代处理大约366G的日志头部(假设消息大小为1k)。
配置Log Cleaner
Log Cleaner默认启用。这会启动清理的线程池。如果要开始特定Topic的清理功能,可以开启特定的属性:
`log.cleanup.policy=compact`
这个可以通过创建Topic时配置或者之后使用Topic命令实现。
Log Cleaner可以配置保留最小的不压缩的head log。可以通过配置压缩的延迟时间:
`log.cleaner.min.compaction.lag.ms`
这可以保证消息在配置的时长内不被压缩。 如果没有设置,除了最后一个日志外,所有的日志都会被压缩。 活动的 segment 是不会被压缩的,即使它保存的消息的滞留时长已经超过了配置的最小压缩时间长。
关于cleaner更详细的配置在 这里。
2.5.9 Quotas配额
Kafka broker可以对客户端做两种类型的资源配额限制:
- 定义字节率的阈值来限定网络带宽的配额。 (从 0.9 版本开始)
- request 请求率的配额,网络和 I/O线程 cpu利用率的百分比。 (从 0.11 版本开始)
为什么要对资源进行配额?
producers 和 consumers 可能会生产或者消费大量的数据或者产生大量的请求,导致对 broker 资源的垄断,引起网络的饱和,对其他clients和brokers本身造成DOS攻击。 资源的配额保护可以有效防止这些问题,在大型多租户集群中,因为一小部分表现不佳的客户端降低了良好的用户体验,这种情况下非常需要资源的配额保护。 实际情况中,当把Kafka当做一种服务提供的时候,可以根据客户端和服务端的契约对 API 调用做限制。
客户端group
Kafka client 是一个用户的概念, 是在一个安全的集群中经过身份验证的用户。在一个支持非授权客户端的集群中,用户是一组非授权的 users,broker使用一个可配置的PrincipalBuilder
资源配额可以针对 (user,client-id),users 或者client-id groups 三种规则进行配置。对于一个请求连接,连接会匹配最细化的配额规则的限制。同一个 group 的所有连接共享这个 group 的资源配额。 举个例子,如果 (user=”test-user”, client-id=”test-client”) 客户端producer 有10MB/sec 的生产资源配置,这10MB/sec 的资源在所有 “test-user” 用户,client-id是 “test-client” 的producer实例中是共享的。
Quota Configuration(资源配额的配置)
资源配额的配置可以根据 (user, client-id),user 和 client-id 三种规则进行定义。在配额级别需要更高(或者更低)的配额的时候,是可以覆盖默认的配额配置。 这种机制和每个 topic 可以自定义日志配置属性类似。 覆盖 User 和 (user, client-id) 规则的配额配置会写到zookeeper的 /config/users路径下,client-id 配额的配置会写到 /config/clients 路径下。 这些配置的覆盖会被所有的 brokers 实时的监听到并生效。所以这使得我们修改配额配置不需要重启整个集群。更多细节参考 here。 每个 group 的默认配额可以使用相同的机制进行动态更新。
举个例子,如果 (user=”test-user”, client-id=”test-client”) 客户端producer 有10MB/sec 的生产资源配置,这10MB/sec 的资源在所有 “test-user” 用户,client-id是 “test-client” 的producer实例中是共享的。
配额配置的优先级顺序是:
/config/users/<user>/clients/<client-id>/config/users/<user>/clients/<default>/config/users/<user>/config/users/<default>/clients/<client-id>/config/users/<default>/clients/<default>/config/users/<default>/config/clients/<client-id>/config/clients/<default>
Broker 的配置属性 (quota.producer.default, quota.consumer.default) 也可以用来设置 client-id groups 默认的网络带宽配置。这些配置属性在未来的 release 版本会被 deprecated。 client-id 的默认配额也是用zookeeper配置,和其他配额配置的覆盖和默认方式是相似的。
Network Bandwidth Quotas(网络带宽配额配置)
网络带宽配额使用字节速率阈值来定义每个 group 的客户端的共享配额。 默认情况下,每个不同的客户端 group 是集群配置的固定配额,单位是 bytes/sec。 这个配额会以broker 为基础进行定义。在 clients 被限制之前,每个 group 的clients可以发布和拉取单个broker 的最大速率,单位是 bytes/sec。
Request Rate Quotas(请求速率配额)
请求速率的配额定义了一个客户端可以使用 broker request handler I/O 线程和网络线程在一个配额窗口时间内使用的百分比。 n% 的配置代表一个线程的 n%的使用率,所以这种配额是建立在总容量 ((num.io.threads + num.network.threads) * 100)%之上的. 每个 group 的client 的资源在被限制之前可以使用单位配额时间窗口内I/O线程和网络线程利用率的 n%。 由于分配给 I/O和网络线程的数量是基于 broker 的核数,所以请求量的配额代表每个group 的client 使用cpu的百分比。
Enforcement(限制)
默认情况下,集群给每个不同的客户端group 配置固定的配额。 这个配额是以broker为基础定义的。每个 client 在受到限制之前可以利用每个broker配置的配额资源。 我们觉得给每个broker配置资源配额比为每个客户端配置一个固定的集群带宽资源要好,为每个客户端配置一个固定的集群带宽资源需要一个机制来共享client 在brokers上的配额使用情况。这可能比配额本身实现更难。
broker在检测到有配额资源使用违反规则会怎么办?在我们计划中,broker不会返回error,而是会尝试减速 client 超出的配额设置。 broker 会计算出将客户端限制到配额之下的延迟时间,并且延迟response响应。这种方法对于客户端来说也是透明的(客户端指标除外)。这也使得client不需要执行任何特殊的 backoff 和 retry 行为。而且不友好的客户端行为(没有 backoff 的重试)会加剧正在解决的资源配额问题。
网络字节速率和线程利用率可以用多个小窗口来衡量(例如 1秒30个窗口),以便快速的检测和修正配额规则的违反行为。实际情况中 较大的测量窗口(例如,30秒10个窗口)会导致大量的突发流量,随后长时间的延迟,会使得用户体验不是很好。
2.6 实现思路
2.6.1 网络层
网络层相当于一个 NIO 服务,在此不在详细描述. sendfile(零拷贝) 的实现是通过 MessageSet 接口的 writeTo 方法完成的.这样的机制允许 file-backed 集使用更高效的 transferTo 实现,而不在使用进程内的写缓存.线程模型是一个单独的接受线程和 N 个处理线程,每个线程处理固定数量的连接.这种设计方式在其他地方经过大量的测试,发现它是实现简单而且快速的.协议保持简单以允许未来实现其他语言的客户端.
2.6.2 消息
消息包含一个可变长度的 header ,一个可变长度不透明的字节数组 key ,一个可变长度不透明的字节数组 value ,消息中 header 的格式会在下一节描述. 保持消息中的 key 和 value 不透明(二进制格式)是正确的决定: 目前构建序列化库取得很大的进展,而且任何单一的序列化方式都不能满足所有的用途.毋庸置疑,使用kafka的特定应用程序可能会要求特定的序列化类型作为自己使用的一部分. RecordBatch 接口就是一种简单的消息迭代器,它可以使用特定的方法批量读写消息到 NIO 的 Channel 中.
2.6.3 消息格式
消息通常按照批量的方式写入.record batch 是批量消息的技术术语,它包含一条或多条 records.不良情况下, record batch 只包含一条 record. Record batches 和 records 都有他们自己的 headers.在 kafka 0.11.0及后续版本中(消息格式的版本为 v2 或者 magic=2)解释了每种消息格式.点击查看消息格式详情.
-
Record Batch
RecordBatch在硬盘上的格式:
baseOffset: int64 batchLength: int32 partitionLeaderEpoch: int32 magic: int8 (current magic value is 2) crc: int32 attributes: int16 bit 0~2: 0: no compression 1: gzip 2: snappy 3: lz4 bit 3: timestampType bit 4: isTransactional (0 means not transactional) bit 5: isControlBatch (0 means not a control batch) bit 6~15: unused lastOffsetDelta: int32 firstTimestamp: int64 maxTimestamp: int64 producerId: int64 producerEpoch: int16 baseSequence: int32 records: [Record]启用压缩时,压缩的记录数据将直接按照记录数进行序列化。
CRC(一种数据校验码) 会覆盖从属性到批处理结束的数据, (即 CRC 后的所有字节数据). CRC 位于 magic 之后,这意味着,在决定如何解释批次的长度和 magic 类型之前,客户端需要解析 magic 类型.CRC 计算不包括分区 learder epoch 字段,是为了避免 broker 收到每个批次的数据时 需要重新分配计算 CRC . CRC-32C (Castagnoli) 多项式用于计算.
压缩: 不同于旧的消息格式, magic v2 及以上版本在清理日志时保留原始日志中首次及最后一次 offset/sequence .这是为了能够在日志重新加载时恢复生产者的状态.例如,如果我们不保留最后一次序列号,当分区 learder 失败以后,生产者会报 OutOfSequence 的错误.必须保留基础序列号来做重复检查(broker 通过检查生产者该批次请求中第一次及最后一次序列号是否与上一次的序列号相匹配来判断是否重复).因此,当批次中所有的记录被清理但批次数据依然保留是为了保存生产者最后一次的序列号,日志中可能有空的数据.不解的是在压缩中时间戳可能不会被保留,所以如果批次中的第一条记录被压缩,时间戳也会改变
RecordBatch-批次控制
批次控制包含成为控制记录的单条记录. 控制记录不应该传送给应用程序,相反,他们是消费者用来过滤中断的事务消息.
控制记录的 key 符合以下模式:
version: int16 (current version is 0) type: int16 (0 indicates an abort marker, 1 indicates a commit)批次记录值的模式依赖于类型. 对客户端来说它是透明的.
-
Record(记录)
Record 级别的头部信息在0.11.0 版本引入. 拥有 headers 的 Record 的磁盘格式如下.
length: varint attributes: int8 bit 0~7: unused timestampDelta: varint offsetDelta: varint keyLength: varint key: byte[] valueLen: varint value: byte[] Headers => [Header]以上的Header格式为
headerKeyLength: varint headerKey: String headerValueLength: varint Value: byte[]我们使用了和 Protobuf 编码格式相同的 varint 编码. 更多后者相关的信息 在这里. Record 中 headers 的数量也被编码为 varint .
2.6.4 日志
命名为 “my_topic” 的主题日志有两个分区,包含两个目录 (命名为 my_topic_0 和 my_topic_1) ,目录中分布着包含该 topic 消息的日志文件.日志文件的格式是 “log entries” 的序列; 每个日志对象是由4位的数字N存储日志长度,后跟 N 字节的消息.每个消息使用64位的整数作为 offset 唯一标记, offset 即为发送到该 topic partition 中所有流数据的起始位置.每个消息的磁盘格式如下. 每个日志文件使用它包含的第一个日志的 offset 来命名.所以创建的第一个文件是 00000000000.kafka, 并且每个附件文件会有大概 S 字节前一个文件的整数名称,其中 S 是配置给出的最大文件大小.
记录的精确二进制格式是版本化的,并且按照标准接口进行维护,所以批量的记录可以在 producer, broker 和客户端之间传输,而不需要在使用时进行重新复制或转化.前一章包含了记录的磁盘格式的详情.
消息的偏移量用作消息 id 是不常见的.我们最开始的想法是使用 producer 自增的 GUID ,并维护从 GUID 到每个 broker 的 offset 的映射.这样的话每个消费者需要为每个服务端维护一个 ID,提供全球唯一的 GUID 没有意义.而且,维护一个从随机 ID 到偏移量映射的复杂度需要一个重度的索引结构,它需要与磁盘进行同步,本质上需要一个完整的持久随机访问数据结构.因此为了简化查找结构,我们决定针对每个分区使用一个原子计数器,它可以利用分区id和节点id唯一标识一条消息.虽然这使得查找结构足够简单,但每个消费者的多个查询请求依然是相似的.一旦我们决定使用计数器,直接跳转到对应的偏移量显得更加自然-毕竟对于每个分区来说它们都是一个单调递增的整数.由于消费者API隐藏了偏移量,所以这个决定最终是一个实现细节,我们采用了更高效的方法。
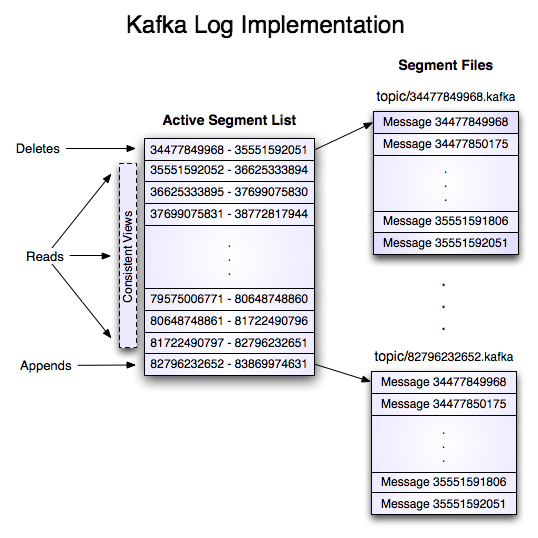
Writes
日志允许序列化的追加到最后一个文件中.当文件大小达到配置的大小(默认 1G)时,会生成一个新的文件.日志中有两个配置参数: M 是在 OS 强制写文件到磁盘之前的消息条数, S 是强制写盘的秒数.这提供了一个在系统崩溃时最多丢失 M 条或者 S 秒消息的保证.
Reads
通过提供消息的64位逻辑偏移量和 S 位的 max chunk size 完成读请求.这会返回一个包含 S位的消息缓存迭代器. S 必须大于任何单条的数据,但是在异常的大消息情况下,读取操作可以重试多次,每次会加倍缓冲的大小,直到消息被读取成功.可以指定最大消息大小和缓存大小使服务器拒绝接收超过其大小的消息,并为客户端设置消息的最大限度,它需要尝试读取多次获得完整的消息.读取缓冲区可能以部分消息结束,这很容易通过大小分界来检测.
按照偏移量读取的实际操作需要在数据存储目录中找到第一个日志分片的位置,在全局的偏移量中计算指定文件的偏移量,然后读取文件偏移量.搜索是使用二分查找法查找在内存中保存的每个文件的偏移量来完成的.
日志提供了将消息写入到当前的能力,以允许客户端从’当前开始订阅.在消费者未能在其SLA指定的天数内消费其数据的情况下,这也是有用的.在这种情况下,客户端会尝试消费不存在的偏移量的数据,这会抛出 OutOfRangeException 异常,并且也会重置 offset 或者失败.
以下是发送给消费者的结果格式.
单个消息
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
多个消息(即一个消息内包含了上述多个MessageSetSend消息)
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
Deletes
在一个时点下只有一个 log segment 的数据能被删除。日志管理器允许使用可插拔的删除策略来选择哪些文件符合删除条件.当前的删除策略会删除 N 天之前改动的日志,尽管保留最后的 N GB 数据可能有用.为了避免锁定读,同时允许删除修改 segment 列表,我们使用 copy-on-write 形式的 segment 列表实现,在删除的同时它提供了一致的视图允许在多个 segment 列表视图上执行二进制的搜索。
Guarantees
日志提供了配置项 M ,它控制了在强制刷盘之前的最大消息数。启动时,日志恢复线程会运行,对最新的日志片段进行迭代,验证每条消息是否合法。如果消息对象的总数和偏移量小于文件的长度并且 消息数据包的 CRC32 校验值与存储在消息中的 CRC 校验值相匹配的话,说明这个消息对象是合法的。如果检测到损坏,日志会在最后一个合法 offset 处截断。
请注意,有两种损坏必须处理:由于崩溃导致的未写入的数据块的丢失和将无意义已损坏的数据块添加到文件。原因是:通常系统不能保证文件索引节点和实际数据快之间的写入顺序,除此之外,如果在块数据被写入之前,文件索引已更新为新的大小,若此时系统崩溃,文件不会的到有意义的数据,则会导致数据丢失。
2.6.5 分布式
Consumer Offset Tracking(消费者offset跟踪)
高级别的consumer跟踪每个分区已消费的offset,并定期提交,以便在重启的情况下可以从这些offset中恢复。Kafka提供了一个选项在指定的broker中来存储所有给定的consumer组的offset,称为offset manager。例如,该consumer组的所有consumer实例向offset manager(broker)发送提交和获取offset请求。高级别的consumer将会自动处理这些过程。如果你使用低级别的consumer,你将需要手动管理offset。目前在低级别的java consumer中不支持,只能在Zookeeper中提交或获取offset。如果你使用简单的Scala consumer,将可拿到offset manager,并显式的提交或获取offset。对于包含offset manager的consumer可以通过发送GroupCoordinatorRequest到任意kafka broker,并接受GroupCoordinatorResponse响应,consumer可以继续向offset manager broker提交或获取offset。如果offset manager位置变动,consumer需要重新发现offset manager。如果你想手动管理你的offset,你可以看看OffsetCommitRequest 和 OffsetFetchRequest的源码是如何实现的。
当offset manager接收到一个OffsetCommitRequest,它将追加请求到一个特定的压缩名为__consumer_offsets的kafka topic中,当offset topic的所有副本接收offset之后,offset manager将发送一个提交offset成功的响应给consumer。万一offset无法在规定的时间内复制,offset将提交失败,consumer在回退之后可重试该提交(高级别consumer自动进行)。broker会定期压缩offset topic,因为只需要保存每个分区最近的offset。offset manager会缓存offset在内存表中,以便offset快速获取。
当offset manager接收一个offset的获取请求,将从offset缓存中返回最新的的offset。如果offset manager刚启动或新的consumer组刚成为offset manager(成为offset topic分区的leader),则需要加载offset topic的分区到缓存中,在这种情况下,offset将获取失败,并报出OffsetsLoadInProgress异常,consumer回滚后,重试OffsetFetchRequest`s(高级别consumer自动进行这些操作)。
从ZooKeeper迁移offset到Kafka
Kafka consumers在早先的版本中offset默认存储在ZooKeeper中。可以通过下面的步骤迁移这些consumer到Kafka:
1.在consumer配置中设置offsets.storage=kafka 和 dual.commit.enabled=true。
2.consumer做滚动消费,验证你的consumer是健康正常的。
3.在你的consumer配置中设置dual.commit.enabled=false。
4.consumer做滚动消费,验证你的consumer是健康正常的。
回滚(就是从kafka回到Zookeeper)也可以使用上面的步骤,通过设置 offsets.storage=zookeeper。
ZooKeeper 目录
下面给出了Zookeeper的结构和算法,用于协调consumer和broker。
-
Notation
当一个path中的元素表示为
[XYZ],这意味着xyz的值不是固定的,实际上每个xyz的值可能是Zookeeper的znode,例如/topic/[topic]是一个目录,/topic包含一个子目录(每个topic名称)。数字的范围如[0...5]来表示子目录0,1,2,3,4。箭头->用于表示znode的内容,例如:/hello->world表示znode/hello包含值”world”。 -
Broker节点注册
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)这是当前所有broker的节点列表,其中每个提供了一个唯一的逻辑broker的id标识它的consumer(必须作为配置的一部分)。在启动时,broker节点通过在
/brokers/ids/下用逻辑broker id创建一个znode来注册它自己。逻辑broker id的目的是当broker移动到不同的物理机器时,而不会影响消费者。尝试注册一个已存在的broker id时将返回错误(因为2个server配置了相同的broker id)。由于broker在Zookeeper中用的是临时znode来注册,因此这个注册是动态的,如果broker关闭或宕机,节点将消失(通知consumer不再可用)。
-
Broker Topic 注册
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)每个broker在它自己的topic下注册,维护和存储该topic分区的数据。
-
Consumer和Consumer组
topic的consumer也在zookeeper中注册自己,以便相互协调和平衡数据的消耗。consumer也可以通过设置
offsets.storage = zookeeper将他们的偏移量存储在zookeeper中。但是,这个偏移存储机制将在未来的版本中被弃用。因此,建议将数据迁移到kafka中。多个consumer可组成一组,共同消费一个topic,在同一组中的每个consumer共享一个group_id。例如,如果一个consumer是foobar,在三台机器上运行,你可能分配这个这个consumer的ID是“foobar”。这个组id是在consumer的配置文件中配置的。
每个分区正好被一个consumer组的consumer所消费,一组中的consumer尽可能公平地分配分区。
-
Consumer offset
如果
offset.storage=zookeeper,consumer跟踪每个分区的最大offset,最大offset存储在zookeeper。 -
Consumer 用户登录
每个broker的分区被单个consumer组消费,consumer必须用户登录,
/consumers/[group_id]/owners/[topic]/[partition_id] --> consumer_node_id (ephemeral node) -
集群ID
集群ID唯一且不变。集群ID可以有最多22个特性,可以通过正则表达式
[a-zA-Z0-9_\-]+来定义。broker启动时,会尝试从
/cluster/idznode获取集群ID。如果znode(zookeeper node?)不存在,则broker生成一个新的集群ID并为该ID创建一个znode。 -
Consumer登录算法
当一个consumer启动时,进行以下步骤:
1.在他的consumer组中登录consumer id
2.注册一个consuemer id登录的监视器(consumer登录或者退出,每一次登录或者退出都会触发平衡该consumer组)
3.注册一个broker id登录的监视器(broker的加入或者退出,每一次加入或者推出都会触发平衡所有consumer组内的consumer)
4.如果consumer通过topic过滤器创建了一个信息流,也会注册一个broker topic的监视器(新的topic加入,每一次加入都会触发重新评估可用topics,进而决定哪个topic过滤器关联哪些topics)
5.强制consumer自身在此consumer 组内的平衡
什么是重平衡?当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。重平衡是Kafka一个很重要的性质,这个性质保证了高可用和水平扩展。
-
Consumer重平衡算法
consumer重平衡算法可以使得一个consumer组内的所有consumer达成哪个consumer消费哪个partition的共识。consumer重平衡由每次增加或者移除broker节点或者同组内其他的consumer。一个partition总是被单个consumer消费(解释:kafka确保每个partition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费)。此设计简化了应用。如果我们允许多个使用者同时使用分区,则会在分区上产生争用,并且需要某种锁定。如果消费者多于分区,则一些消费者根本不会获得任何数据。在重新平衡期间,我们尝试以减少每个消费者必须连接的代理节点数量的方式为消费者分配分区。
算法:
1. For each topic T that C<sub>i</sub> subscribes to 2. let P<sub>T</sub> be all partitions producing topic T 3. let C<sub>G</sub> be all consumers in the same group as C<sub>i</sub> that consume topic T 4. sort P<sub>T</sub> (so partitions on the same broker are clustered together) 5. sort C<sub>G</sub> 6. let i be the index position of C<sub>i</sub> in C<sub>G</sub> and let N = size(P<sub>T</sub>)/size(C<sub>G</sub>) 7. assign partitions from i*N to (i+1)*N - 1 to consumer C<sub>i</sub> 8. remove current entries owned by C<sub>i</sub> from the partition owner registry 9. add newly assigned partitions to the partition owner registry (we may need to re-try this until the original partition owner releases its ownership)如果一个consumer重平衡,则同组内其他consumer也需要重平衡。
3.Kafka使用
3.1 基本的Kafka操作
3.1.1 Quick Start
启动zookeeper和kafka服务器
Kafka 使用 ZooKeeper 如果你还没有ZooKeeper服务器,你需要先启动一个ZooKeeper服务器。 您可以通过与kafka打包在一起的便捷脚本来快速简单地创建一个单节点ZooKeeper实例。
# zookeeper服务器启动
$ bin/zookeeper-server-start.sh config/zookeeper.properties
修改server的properties
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9091
log.dirs=/tmp/kafka-logs-1
# kafka服务器启动
$ bin/kafka-server-start.sh config/server-1.properties
创建一个topic
# 创建一个名为test的topic,有一个分区和一个副本
# 此处--zookeeper定义zookeeper或者--boostrap-server定义kafka server均可
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
可以运行list(列表)命令来查看这个topic:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181
发送一些消息
Kafka自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为message(消息)发送到Kafka集群。默认情况下,每行将作为单独的message发送。
运行 producer,然后在控制台输入一些消息以发送到服务器。
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
启动一个 consumer
Kafka 还有一个命令行consumer(消费者),将消息转储到标准输出。
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
设置多代理集群
# 拷贝设置文件
$ cp config/server.properties config/server-2.properties
$ cp config/server.properties config/server-3.properties
然后修改属性文件
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-2
config/server-3.properties:
broker.id=3
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-3
运行
$ bin/kafka-server-start.sh config/server-2.properties &
...
$ bin/kafka-server-start.sh config/server-3.properties &
...
创建复制因子为3的topic
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
查看信息
$ bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
“leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions. “replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive. “isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
节点2是topic唯一的分区Leader
验证(待验证,发现PID一直变动)
# 消息生成
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
# 消费消息
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
# 容错验证
## 关闭Leader节点
$ ps aux | grep server-1.properties
$ sudo kill -9 [PID]
# 查看topic信息
$ bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
3.1.2 基本操作
添加和删除topics
您可以选择手动添加 topic ,或者在数据首次发布到不存在的 topic 时自动创建 topic 。如果 topic 是自动创建的,那么您可能需要调整用于自动创建 topic 的默认 topic 配置。
使用 topic 工具来添加和修改 topic:
$ bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic my_topic_name --partitions 20 --replication-factor 3 --config x=y
replication-factor 控制有多少服务器将复制每个写入的消息。如果您设置了3个复制因子,那么只能最多2个相关的服务器能出问题,否则您将无法访问数据。我们建议您使用2或3个复制因子,以便在不中断数据消费的情况下透明的调整集群。
partitions 参数控制 topic 将被分片到多少个日志里。partitions 会产生几个影响。首先,每个分区只属于一个台服务器,所以如果有20个分区,那么全部数据(包含读写负载)将由不超过20个服务器(不包含副本)处理。最后 partitions 还会影响 consumer 的最大并行度。这在概念部分中有更详细的讨论。
每个分区日志都放在自己的Kafka日志目录下的文件夹中。这些文件夹的名称由主题名称,破折号( - )和分区ID组成。由于典型的文件夹名称长度不能超过255个字符,所以主题名称的长度会受到限制。我们假设分区的数量不会超过10万。因此,主题名称不能超过249个字符。这在文件夹名称中留下了足够的空间以显示短划线和可能的5位长的分区ID。
在命令行上添加的配置会覆盖服务器的默认设置,例如数据应该保留的时间长度。此处记录了完整的每个 topic 配置。
删除一个 topic :
$ bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name
当前,Kafka 不支持减少一个 topic 的分区数。
修改topics
使用相同的 topic 工具,您可以修改 topic 的配置或分区。
要添加分区,你可以做如下操作:
$ bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --partitions 40
请注意,分区的一个用处是对数据进行语义分区,并且添加分区不会更改现有数据的分区,因此如果依赖该分区,则可能会影响消费者。也就是说,如果数据是通过 hash(key)%number_of_partitions 进行分区的,那么这个分区可能会通过添加分区进行混洗,但Kafka不会尝试以任何方式自动重新分配数据。
增加一个配置项:
--add-config
$ bin/kafka-configs.sh --zookeeper zk_host:port/chroot --entity-type topics --entity-name my_topic_name --alter --add-config x=y
删除一个配置项:
--delete-config
$ bin/kafka-configs.sh --zookeeper zk_host:port/chroot --entity-type topics --entity-name my_topic_name --alter --delete-config x
优雅地关机
Kafka集群将自动检测到任何 broker 关机或故障,并为该机器上的分区选择新的 leader。无论服务器出现故障还是因为维护或配置更改而故意停机,都会发生这种情况。 对于后一种情况,Kafka支持更优雅的停止服务器的机制,而不仅仅是杀死它。 当一个服务器正常停止时,它将采取两种优化措施:
- 它将所有日志同步到磁盘,以避免在重新启动时需要进行任何日志恢复活动(即验证日志尾部的所有消息的校验和)。由于日志恢复需要时间,所以从侧面加速了重新启动操作。
- 它将在关闭之前将以该服务器为 leader 的任何分区迁移到其他副本。这将使 leader 角色传递更快,并将每个分区不可用的时间缩短到几毫秒。
只要服务器的停止不是通过直接杀死,同步日志就会自动发生,但控制 leader 迁移需要使用特殊的设置:
controlled.shutdown.enable=true
请注意,只有当 broker 托管的分区具有副本(即,复制因子大于1 且至少其中一个副本处于活动状态)时,对关闭的控制才会成功。 这通常是你想要的,因为关闭最后一个副本会使 topic 分区不可用。
Leader平衡
每当一个 borker 停止或崩溃时,该 borker 上的分区的leader 会转移到其他副本。这意味着,在 broker 重新启动时,默认情况下,它将只是所有分区的跟随者,这意味着它不会用于客户端的读取和写入。为了避免这种不平衡,Kafka有一个首选副本的概念。如果分区的副本列表为1,5,9,则节点1首选为节点5或9的 leader ,因为它在副本列表中较早。您可以通过运行以下命令让Kafka集群尝试恢复已恢复副本的领导地位:
$ bin/kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
由于运行此命令可能很乏味,您也可以通过以下配置来自动配置Kafka:
auto.leader.rebalance.enable=true
垮机架均衡副本
机架感知功能可以跨不同机架传播相同分区的副本。这扩展了 Kafka 为 broker 故障提供的容错担保,弥补了机架故障,如果机架上的所有 broker 都失败,则可以限制数据丢失的风险。该功能也可以应用于其他 broker 分组,例如EC2中的可用区域。
您可以通过向 broker 配置添加属性来指定 broker 属于的特定机架:
broker.rack=my-rack-id
当 topic 创建,修改或副本重新分配时, 机架约束将得到保证,确保副本跨越尽可能多的机架(一个分区将跨越 min(#racks,replication-factor) 个不同的机架)。 用于向 broker 分配副本的算法可确保每个 broker 的 leader 数量将保持不变,而不管 broker 在机架之间如何分布。这确保了均衡的吞吐量。 但是,如果 broker 在机架间分布不均 ,副本的分配将不均匀。具有较少 broker 的机架将获得更多复制副本,这意味着他们将使用更多存储并将更多资源投入复制。因此,每个机架配置相同数量的 broker 是明智的。
集群之间镜像数据
指的是通过“镜像”复制Kafka集群之间的数据的过程,以避免与在单个集群中的节点之间发生的复制混淆。Kafka附带了一个在Kafka集群之间镜像数据的工具 mirror-maker。该工具从源集群中消费数据并产生数据到目标集群。 这种镜像的常见用例是在另一个数据中心提供副本。
您可以运行许多这样的镜像进程来提高吞吐量和容错能力(如果一个进程死亡,其他进程将承担额外的负载)。
从源群集中的 topic 中读取数据,并将其写入目标群集中具有相同名称的 topic。事实上,镜像只不过是把一个 Kafka 的 consumer 和 producer 联合在一起了。
源和目标集群是完全独立的实体:它们可以有不同数量的分区,偏移量也不会相同。由于这个原因,镜像集群并不是真正意义上的容错机制(因为 consumer 的偏移量将会不同)。为此,我们建议使用正常的群集内复制。然而,镜像制作进程将保留并使用消息 key 进行分区,所以在每个 key 的基础上保存顺序。
以下示例显示如何从输入群集中镜像单个 topic(名为 my-topic ):
$ bin/kafka-mirror-maker.sh
--consumer.config consumer.properties
--producer.config producer.properties --whitelist my-topic
请注意,我们使用 --whitelist 选项指定 topic 列表。此选项允许使用任何 Java风格的正则表达式 因此,您可以使用--whitelist 'A|B'来镜像名为A 和 B 的两个 topic 。 或者您可以使用--whitelist '*'来镜像全部 topic。确保引用的任何正则表达式不会被 shell 尝试将其展开为文件路径。为了方便起见,我们允许使用','而不是'|' 指定 topic 列表。
有时,说出你不想要的东西比较容易。与使用–whitelist 来表示你想要的相反,通过镜像您可以使用 --blacklist 来表示要排除的内容。 这也需要一个正则表达式的参数。但是,当启用新的 consumer 时,不支持 --blacklist(即 bootstrap.servers )已在 consumer 配置中定义)。
将镜像与配置项 auto.create.topics.enable = true 结合使用,可以创建一个副本群集,即使添加了新的 topic,也可以自动创建和复制源群集中的所有数据。
检查consumer位置
有时观察到消费者的位置是有用的。我们有一个工具,可以显示 consumer 群体中所有 consumer 的位置,以及他们所在日志的结尾。要在名为my-group的 consumer 组上运行此工具,消费一个名为my-topic的 topic 将如下所示:
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group
输出:
注意:这将仅显示使用Java consumer API(基于非ZooKeeper的 consumer)的 consumer 的信息。
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
my-topic 0 2 4 2 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1
my-topic 1 2 3 1 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1
my-topic 2 2 3 1 consumer-2-42c1abd4-e3b2-425d-a8bb-e1ea49b29bb2 /127.0.0.1 consumer-2
这个工具也适用于基于ZooKeeper的 consumer:
$ bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --describe --group my-group
输出:
注意:这只会显示关于使用ZooKeeper的 consumer 的信息(不是那些使用Java consumer API的消费者)。
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID
my-topic 0 2 4 2 my-group_consumer-1
my-topic 1 2 3 1 my-group_consumer-1
my-topic 2 2 3 1 my-group_consumer-2
管理consumer组
通过 ConsumerGroupCommand 工具,我们可以列出,描述或删除 consumer 组。请注意,删除仅在组元数据存储在ZooKeeper中时可用。当使用新的 consumer API ( broker 协调分区处理和重新平衡)时, 当该组的最后一个提交偏移量过期时,该组将被删除。 例如,要列出所有 topic 中的所有 consumer 组:
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
如前所述,为了查看偏移量,我们这样“describe”consumer 组:
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-consumer-group
输出
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test-foo 0 1 3 2 consumer-1-a5d61779-4d04-4c50-a6d6-fb35d942642d /127.0.0.1 consumer-1
如果您正在使用老的高级 consumer 并在ZooKeeper中存储组元数据(即 offsets.storage = zookeeper ),则传递 --zookeeper 而不是bootstrap-server:
$ bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
拓展集群
将服务器添加到Kafka集群非常简单,只需为其分配唯一的 broker ID并在您的新服务器上启动Kafka即可。但是,这些新的服务器不会自动分配到任何数据分区,除非将分区移动到这些分区,否则直到创建新 topic 时才会提供服务。所以通常当您将机器添加到群集中时,您会希望将一些现有数据迁移到这些机器上。
迁移数据的过程是手动启动的,但是完全自动化。在迁移数据时,Kafka会将新服务器添加为正在迁移的分区的 follower,并允许它完全复制该分区中的现有数据。当新服务器完全复制了此分区的内容并加入了同步副本时,其中一个现有副本将删除其分区的数据。
分区重新分配工具可用于跨 broker 移动分区。理想的分区分布将确保所有 broker 的数据负载和分区大小比较均衡。分区重新分配工具不具备自动分析Kafka集群中的数据分布并移动分区以获得均匀负载的功能。因此,管理员必须找出哪些 topic 或分区应该移动。
区重新分配工具可以以3种互斥方式运行:
--generate: 在此模式下,给定一个 topic 列表和一个 broker 列表,该工具会生成一个候选重新分配,以将指定的 topic 的所有分区移动到新的broker。此选项仅提供了一种便捷的方式,可以根据 tpoc 和目标 broker 列表生成分区重新分配计划。--execute: 在此模式下,该工具基于用户提供的重新分配计划启动分区重新分配。(使用--reassignment-json-file选项)。这可以是由管理员制作的自定义重新分配计划,也可以是使用–generate选项提供的自定义重新分配计划。--verify: 在此模式下,该工具将验证最近用--execute模式执行间的所有分区的重新分配状态。状态可以是成功完成,失败或正在进行
自动将数据迁移到新机器
分区重新分配工具可用于将当前一组 broker 的一些 topic 移至新增的topic。这在扩展现有群集时通常很有用,因为将整个 topic 移动到新 broker 集比移动一个分区更容易。当这样做的时候,用户应该提供需要移动到新的 broker 集合的 topic 列表和新的目标broker列表。该工具然后会均匀分配新 broker 集中 topic 的所有分区。在此过程中,topic 的复制因子保持不变。实际上,所有输入 topic 的所有分区副本都将从旧的broker 组转移到新 broker中。
例如,以下示例将把名叫foo1,foo2的 topic 的所有分区移动到新的 broker 集5,6。最后,foo1和foo2的所有分区将只在<5,6> broker 上存在。
由于该工具接受由 topic 组成的输入列表作为json文件,因此首先需要确定要移动的 topic 并创建 json 文件,如下所示:
$ cat topics-to-move.json
输出
{"topics": [{"topic": "foo1"},
{"topic": "foo2"}],
"version":1
}
一旦json文件准备就绪,就可以使用分区重新分配工具来生成候选分配(而不是已经完成分配):
$ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
输出
当前分区副本分配
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]},
{"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]},
{"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}]
}
建议的分区重新分配配置
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}]
}
该工具会生成一个候选分配,将所有分区从topic foo1,foo2移动到brokers 5,6。但是,请注意,这个时候(上面的一步),分区操作还没有开始,它只是告诉你当前的任务和建议的新任务。应该保存当前的分配,以防您想要回滚到它。新的任务应该保存在一个json文件(例如expand-cluster-reassignment.json)中,并用--execute选项输入到工具中,如下所示:
$ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
输出
当前分区副本分配
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]},
{"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]},
{"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}]
}
保存这个以在回滚期间用作--reassignment-json-file选项
成功开始重新分配分区
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}]
}
最后,可以使用--verify选项来检查分区重新分配的状态。请注意,相同的expand-cluster-reassignment.json(与--execute选项一起使用)应与--verify选项一起使用:
$ bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
输出
Status of partition reassignment:
Reassignment of partition [foo1,0] completed successfully
Reassignment of partition [foo1,1] is in progress
Reassignment of partition [foo1,2] is in progress
Reassignment of partition [foo2,0] completed successfully
Reassignment of partition [foo2,1] completed successfully
Reassignment of partition [foo2,2] completed successfully
欢迎关注我的微信公众号
互联网矿工
