1、命令
1.1 数据库
创建数据库
如果数据库不存在,则创建数据库
use DATABASE_NAME
删除数据库
删除当前数据库
db.dropDatabase()
显示所有数据库列表
show dbs
显示当前数据库对象或者集合
db
1.2 集合
创建集合
db.createCollection(name, options)
option格式: [option名称:参数]
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | (可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
eg.
db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
创建capped collections
固定大小的colletion
db.createCollection("mycoll", {capped:true, size:100000})
删除集合
db.collection.drop()
返回:true:删除成功;false:删除失败。
查看集合
show collections
1.3 文档document
相当于SQL中的行row。
文档数据结构和json基本一样。所有存储在集合中的数据都是BSON格式。BSON是一种类json的二进制形式的存储格式,简称Binary Json。
插入文档
- insert
db.COLLECTION_NAME.insert(document)
eg.col为一个集合名。如果col不在数据库中,则自动创建。
db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
- insertMany
插入多条文档
db.col.insertMany([{"b":3},{"c":4}])
更新文档
- update
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
WriteConcern.NONE:没有异常抛出
WriteConcern.NORMAL:仅抛出网络错误异常,没有服务器错误异常
WriteConcern.SAFE:抛出网络错误异常、服务器错误异常;并等待服务器完成写操作。
WriteConcern.MAJORITY: 抛出网络错误异常、服务器错误异常;并等待一个主服务器完成写操作。
WriteConcern.FSYNC_SAFE: 抛出网络错误异常、服务器错误异常;写操作等待服务器将数据刷新到磁盘。
WriteConcern.JOURNAL_SAFE:抛出网络错误异常、服务器错误异常;写操作等待服务器提交到磁盘的日志文件。
WriteConcern.REPLICAS_SAFE:抛出网络错误异常、服务器错误异常;等待至少2台服务器完成写操作。
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
以上{‘title’:’MongoDB 教程’}是query(查询部分);{$set:{‘title’:’MongoDB’}}为update部分;{multi:true}为可以找到多个匹配的记录。
其他,
db.collection.updateOne() 向指定集合更新单个文档
db.collection.updateMany() 向指定集合更新多个文档
- save
通过传入的文档来替换已有文档。
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
document : 文档数据。
writeConcern :可选,抛出异常的级别。
在document中指定_id字段,则可以更新该_id的数据。
db.col.save(document)
如果不提供_id字段,则save和insert一样新生成一个文档。
删除文档
官方推荐delete
- delete
删除集合下的所有文档
db.col.deleteMany({})
删除 status 等于 A 的全部文档
db.col.deleteMany({ status : “A” })
删除 status 等于 D 的一个文档
db.col.deleteOne( { status: “D” } )
- remove
已经过时。
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
query :(可选)删除的文档的条件。
justOne: (可选)如果设为 true 或 1,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
查询文档
- DBQuery.shellBatchSize
DBQuery.shellBatchSize
设置查询到的doc个数。
- find
# 查询带数字的集合
db["COLNAME"].find()
# 查询(不带数字)
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
protection的使用:
db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键(title和by),不返回其他键
db.collection.find(query, {title: 0, by: 0}) // exclusion模式 指定不返回的键(title和by),返回其他键
- fineOne
findOne():只返回一个文档
- pretty
以易读的方式查询,pretty()
db.col.find().pretty()
- 查询语句
和RDBMS的where比较
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | { |
db.col.find({“by”:”菜鸟教程”}).pretty() | where by = ‘菜鸟教程’ |
| 小于 | { |
db.col.find({“likes”:{$lt:50}}).pretty() | where likes < 50 |
| 小于或等于 | { |
db.col.find({“likes”:{$lte:50}}).pretty() | where likes <= 50 |
| 大于 | { |
db.col.find({“likes”:{$gt:50}}).pretty() | where likes > 50 |
| 大于或等于 | { |
db.col.find({“likes”:{$gte:50}}).pretty() | where likes >= 50 |
| 不等于 | { |
db.col.find({“likes”:{$ne:50}}).pretty() | where likes != 50 |
操作符简写
$gt -------- greater than >
$gte --------- gt equal >=
$lt -------- less than <
$lte --------- lt equal <=
$ne ----------- not equal !=
$eq -------- equal =
模糊查询
查询 title 包含"教"字的文档:
db.col.find({title:/教/})
查询 title 字段以"教"字开头的文档:
db.col.find({title:/^教/})
查询 titl e字段以"教"字结尾的文档:
db.col.find({title:/教$/})
AND条件用逗号
db.col.find({key1:value1, key2:value2}).pretty()
OR条件用$or
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
OR和AND连用
db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
- $type
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
db.col.find({"title" : {$type : 2}})
或
db.col.find({"title" : {$type : 'string'}})
Double 1
String 2
Object 3
Array 4
Binary data 5
Undefined 6 已废弃。
Object id 7
Boolean 8
Date 9
Null 10
Regular Expression 11
JavaScript 13
Symbol 14
JavaScript (with scope) 15
32-bit integer 16
Timestamp 17
64-bit integer 18
Min key 255 Query with -1.
Max key 127
- limit和skip
limit:在MongoDB中读取指定数量的数据记录
skip:在MongoDB中跳过指定数量的数据
1、读取前NUMBER个数据
db.COLLECTION_NAME.find().limit(NUMBER)
2、读取第NUMBER1条数据后的NUMBER1条
db.COLLECTION_NAME.find().skip(NUMBER1).limit(NUMBER1)
说明:当查询时同时使用sort,skip,limit,无论位置先后,最先执行顺序 sort再skip再limit
- distinct
查找文档中的不同内容。
eg.
{ "_id": 1, "dept": "A", "item": { "sku": "111", "color": "red" }, "sizes": [ "S", "M" ] }
{ "_id": 2, "dept": "A", "item": { "sku": "111", "color": "blue" }, "sizes": [ "M", "L" ] }
{ "_id": 3, "dept": "B", "item": { "sku": "222", "color": "blue" }, "sizes": "S" }
{ "_id": 4, "dept": "A", "item": { "sku": "333", "color": "black" }, "sizes": [ "S" ] }
# 查询满足dept: "A",的不同内容的sku
db.inventory.distinct( "item.sku", { dept: "A" } )
结果
[ "111", "333" ]
1.5 正则表达式
介绍
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
MongoDB使用**PCRE (Perl Compatible Regular Expression) **作为正则表达式语言。
不同于全文检索,我们使用正则表达式不需要做任何配置。
考虑以下 posts 集合的文档结构,该文档包含了文章内容和标签:
{
"post_text": "enjoy the mongodb articles on runoob",
"tags": [
"mongodb",
"runoob"
]
}
基本查询
# 查找包含 runoob 字符串的文章
$ db.posts.find({post_text:{$regex:"runoob"}})
or
$ db.posts.find({post_text:/runoob/})
# 不区分大小写,设置 $options 为 $i
$ db.posts.find({post_text:{$regex:"runoob",$options:"$i"}})
# 在数组字段中使用正则表达式来查找内容,查找run开头的标签数据
$ db.posts.find({tags:{$regex:"run"}})
优化正则表达式查询
- 如果你的文档中字段设置了索引,那么使用索引相比于正则表达式匹配查找所有的数据查询速度更快。(正则表达式查询不会使用索引,故尽量不使用正则表达式)
- 如果正则表达式是前缀表达式,所有匹配的数据将以指定的前缀字符串为开始。例如: 如果正则表达式为
^tut,查询语句将查找以 tut 为开头的字符串。
# 正则表达式中使用变量。一定要使用eval将组合的字符串进行转换,不能直接将字符串拼接后传入给表达式。否则没有报错信息,只是结果为空!
var name=eval("/" + 变量值key +"/i");
# 模糊查询包含title关键词, 且不区分大小写
title:eval("/"+title+"/i") # 等同于 title:{$regex:title,$Option:"$i"}
如果正则表达式是前缀表达式,所有匹配的数据将以指定的前缀字符串为开始。例如: 如果正则表达式为^tut ,查询语句将查找以 tut 为开头的字符串。
regex操作符使用
$regex操作符的使用
$regex操作符中的option选项可以改变正则匹配的默认行为,它包括i, m, x以及S四个选项,其含义如下
i忽略大小写,{<field>{$regex/pattern/i}},设置i选项后,模式中的字母会进行大小写不敏感匹配。m多行匹配模式,{<field>{$regex/pattern/,$options:'m'},m选项会更改^和$元字符的默认行为,分别使用与行的开头和结尾匹配,而不是与输入字符串的开头和结尾匹配。x忽略非转义的空白字符,{<field>:{$regex:/pattern/,$options:'m'},设置x选项后,正则表达式中的非转义的空白字符将被忽略,同时井号(#)被解释为注释的开头注,只能显式位于option选项中。s单行匹配模式{<field>:{$regex:/pattern/,$options:'s'},设置s选项后,会改变模式中的点号(.)元字符的默认行为,它会匹配所有字符,包括换行符(\n),只能显式位于option选项中。
使用$regex操作符时,需要注意下面几个问题:
- i,m,x,s可以组合使用,例如:
{name:{$regex:/j*k/,$options:"si"}} - 在设置索弓}的字段上进行正则匹配可以提高查询速度,而且当正则表达式使用的是前缀表达式时,查询速度会进一步提高,例如:
{name:{$regex: /^joe/}
1.4 索引
介绍
当你往某各个集合插入多个文档后,每个文档在经过底层的存储引擎持久化后,会有一个位置信息,通过这个位置信息pos,就能从存储引擎里读出该文档。如下面的person文档,
| 位置信息 | 文档 |
|---|---|
| pos1 | {“name” : “jack”, “age” : 19 } |
| pos2 | {“name” : “rose”, “age” : 20 } |
| pos3 | {“name” : “jack”, “age” : 18 } |
| pos4 | {“name” : “tony”, “age” : 21} |
| pos5 | {“name” : “adam”, “age” : 18} |
假设现在有个查询 db.person.find( {age: 18} ), 查询所有年龄为18岁的人,这时需要遍历所有的文档(『全表扫描』),根据位置信息读出文档,对比age字段是否为18。如果想加速 db.person.find( {age: 18} ),就可以考虑对person表的age字段建立索引。
# 按age字段创建升序索引
$ db.person.createIndex( {age: 1} )
建立索引后,MongoDB会额外存储一份按age字段升序排序的索引数据,索引结构类似如下,索引通常采用类似btree的结构持久化存储,以保证从索引里快速(O(logN)的时间复杂度)找出某个age值对应的位置信息,然后根据位置信息就能读取出对应的文档。
| AGE | 位置信息 |
|---|---|
| 18 | pos3 |
| 18 | pos5 |
| 19 | pos1 |
| 20 | pos2 |
| 21 | pos4 |
众所周知,MongoDB默认会为插入的文档生成_id字段(如果应用本身没有指定该字段),_id是文档唯一的标识,为了保证能根据文档id快递查询文档,MongoDB默认会为集合创建_id字段的索引。
mongo-9552:PRIMARY> db.person.getIndexes() // 查询集合的索引信息
[
{
"ns" : "test.person", // 集合名
"v" : 1, // 索引版本
"key" : { // 索引的字段及排序方向
"_id" : 1 // 根据_id字段升序索引
},
"name" : "_id_" // 索引的名称
}
]
索引类型
1.单字段索引 (Single Field Index)
# 创建一个"age"字段的索引
$ db.person.createIndex( {age: 1} )
# 删除指定索引
$ db.person.dropIndex("age")
# 删除所有索引
$ db.person.dropIndexes()
# 查看总索引记录大小
$ db.userInfo.totalIndexSize()
# 读取当前集合的所有index信息
$ db.users.reIndex()
{age: 1} 代表升序索引,也可以通过{age: -1}来指定降序索引,对于单字段索引,升序/降序效果是一样的。
注意
_id是默认的索引,不能删除。
java实现
if(this.getIndexName().equals("")) {
collection.createIndex(Indexes.descending(this.indexName), new SingleResultCallback<String>() {
@Override
public void onResult(String result, Throwable t) {
logger.info(String.format("db.col create index by \"%s\"(indexName_-1)", result));
}
});
}
2.复合索引 (Compound Index)
$ db.person.createIndex( {age: 1, name: 1} )
当age字段相同时,在根据name字段进行排序。
3.多key索引 (Multikey Index)
当索引的字段为数组时,创建出的索引称为多key索引,多key索引会为数组的每个元素建立一条索引,比如person表加入一个habbit字段(数组)用于描述兴趣爱好,需要查询有相同兴趣爱好的人就可以利用habbit字段的多key索引。
{"name" : "jack", "age" : 19, habbit: ["football, runnning"]}
db.person.createIndex( {habbit: 1} ) // 自动创建多key索引
db.person.find( {habbit: "football"} )
4.其他索引
哈希索引(Hashed Index)是指按照某个字段的hash值来建立索引,目前主要用于MongoDB Sharded Cluster的Hash分片,hash索引只能满足字段完全匹配的查询,不能满足范围查询等。
地理位置索引(Geospatial Index)能很好的解决O2O的应用场景,比如『查找附近的美食』、『查找某个区域内的车站』等。
文本索引(Text Index)能解决快速文本查找的需求,比如有一个博客文章集合,需要根据博客的内容来快速查找,则可以针对博客内容建立文本索引。
索引属性
- 唯一索引 (unique index):保证索引对应的字段不会出现相同的值,比如_id索引就是唯一索引
- TTL索引:可以针对某个时间字段,指定文档的过期时间(经过指定时间后过期 或 在某个时间点过期)
- 部分索引 (partial index): 只针对符合某个特定条件的文档建立索引,3.2版本才支持该特性
- 稀疏索引(sparse index): 只针对存在索引字段的文档建立索引,可看做是部分索引的一种特殊情况
1.6 数据处理
插入数据
db是一个目录,用于存放所有数据库。
db.DATABASE_NAME.insert({x:10})
格林尼治时间
var mydate1 = new Date()
或者
var mydate1 = ISODate()
排序
db.COLLECTION_NAME.find().sort({KEY:1})
其中,KEY是某一个字段,1:升序;-1:降序。
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
db.collection.createIndex(keys:val, options)
eg.
db.values.createIndex({open: 1, close: 1}, {background: true})
keys为要创建的索引字段,val为1:按照升序创建索引;val为-1:按照降序来创建索引。可以设置使用多个字段创建索引。
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。类似于SQL中的count(*)
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
eg.
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
其中$group是管道,$sum是聚合的表达式。
- 管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
管道实例:
$project只留下_id、title和author:
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
$match过滤数据:
获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$skip跳过文档
跳过前五个。
db.article.aggregate(
{ $skip : 5 });
- 聚合表达式
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}]) | |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}]) |
1.7 MongoDB复制
MongoDB复制是将数据同步在多个服务器的过程。
1、关闭正在运行的MongoDB服务器
2、启动MongoDB
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
eg.会启动一个名为rs0的MongoDB实例,其端口号为27017。
mongod --port 27017 --dbpath "\data\db" --replSet rs0
3、打开命令提示框并连接上mongoDB服务。
mongo
4、使用命令rs.initiate()来启动一个新的副本集
rs.initiate()
查看配置:
rs.conf()
查看副本集状态:
rs.status()
5、副本集添加成员
需要多台服务器启动MongoDB服务。进入Mongo客户端,使用rs.add()方法来添加副本集的成员。
rs.add(HOST_NAME:PORT)
eg.
rs.add("mongod1.net:27017")
MongoDB的副本集于常见的主从有所不同,主从在主机死掉后所有服务停止,而副本集在主机死后,副本会接管主节点成为主节点。
2、分片技术
分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
2.1 意义
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
2.2 分片技术
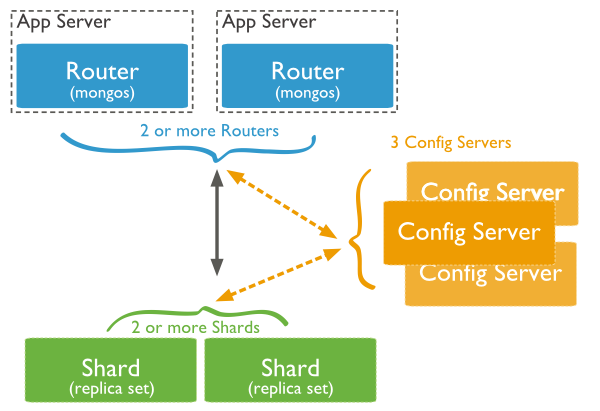
-
Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
-
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
-
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
3、备份与恢复
3.1 备份
mongodump -h dbhost -d dbname -o dbdirectory
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:
需要备份的数据库实例,例如:test
-o:
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
3.2 数据恢复
mongorestore -h <hostname><:port> -d dbname <path>
--host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017
--db,-d:
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
<path>:
mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。
你不能同时指定
--dir:
指定备份的目录
你不能同时指定
4、监控
4.1 mongostat
mongostat是mongodb自带的状态检测工具,在命令行下使用。
它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
启动方法:
1、启动你的Mongod服务
2、进入到你安装的MongoDB目录下的bin目录, 然后输入mongostat命令
4.2 mongotop
mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。
启动方法:
1、启动你的Mongod服务
2、进入到你安装的MongoDB目录下的bin目录, 然后输入mongotop命令
mongotop --locks
使用mongotop - 锁,这将产生以下输出
ns: 包含数据库命名空间,后者结合了数据库名称和集合。
db:
包含数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库。
total:
mongod花费的时间工作在这个命名空间提供总额。
read:
提供了大量的时间,这mongod花费在执行读操作,在此命名空间。
write:
提供这个命名空间进行写操作,这mongod花了大量的时间。
5、设置
启动服务
目录/mongod
开始shell
目录/mongo
元数据
<dbname>.system.*
是包含多种系统信息的特殊集合
dbname.system.namespaces 列出所有名字空间。
dbname.system.indexes 列出所有索引。
dbname.system.profile 包含数据库概要(profile)信息。
dbname.system.users 列出所有可访问数据库的用户。
dbname.local.sources 包含复制对端(slave)的服务器信息和状态。
MongoDB连接
启动MongoDB服务
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
- 打开远程连接
服务器端
1、打开27017防火墙
# 打开
$ sudo iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 27017 -j ACCEPT
# 查看所有防火墙规则
sudo iptables -L
# 比如27017在第1条规则,删除规则实现方法如下
sudo iptable -D INPUT 1
2、打开mongod并对所有ip开放
$ mongod --bind_ip 0.0.0.0
客户端
连接
$ mongo <远程IP>
MongoDB连接命令
使用用户名和密码连接到 MongoDB 服务器,你必须使用 ‘username:password@hostname/dbname’ 格式,’username’为用户名,’password’ 为密码。
1、使用用户名和密码连接登陆到默认数据库
./mongo
2、使用用户admin和密码123456连接到本地MongoDB服务
mongodb://admin:123456@localhost/
3、使用用户名和密码连接登陆到指定数据库
mongodb://admin:123456@localhost/test
4、连接 replica pair, 服务器1为example1.com服务器2为example2
mongodb://example1.com:27017,example2.com:27017
6、MongoDB性能优化
(1)文档中的_id键推荐使用默认值,禁止向_id中保存自定义的值。
MongoDB文档中都会有一个“_id”键,默认是个ObjectID对象(标识符中包含时间戳、机器ID、进程ID和计数器)。MongoDB在指定_id与不指定_id插入时 速度相差很大,指定_id会减慢插入的速率。
(2)推荐使用短字段名
与关系型数据库不同,MongoDB集合中的每一个文档都需要存储字段名,长字段名会需要更多的存储空间。
(3)MongoDB索引可以提高文档的查询、更新、删除、排序操作,所以结合业务需求,适当创建索引。
# 按age字段创建升序索引
$ db.person.createIndex( {age: 1} )
(4)每个索引都会占用一些空间,并且导致插入操作的资源消耗,因此,建议每个集合的索引数尽量控制在5个以内。
(5)对于包含多个键的查询,创建包含这些键的复合索引是个不错的解决方案。复合索引的键值顺序很重要,理解索引最左前缀原则。
例如在test集合上创建组合索引{a:1,b:1,c:1}。执行以下7个查询语句:
db.test.find({a:”hello”}) // 1
db.test.find({b:”sogo”, a:”hello”}) // 2
db.test.find({a:”hello”,b:”sogo”, c:”666”}) // 3
db.test.find({c:”666”, a:”hello”}) // 4
db.test.find({b:”sogo”, c:”666”}) // 5
db.test.find({b:”sogo” }) // 6
db.test.find({c:”666”}) // 7
- 以上查询语句可能走索引的是1、2、3、4
- 查询应包含最左索引字段,以索引创建顺序为准,与查询字段顺序无关。
- 最少索引覆盖最多查询。
(6)TTL索引(time-to-live index,具有生命周期的索引),使用TTL索引可以将超时时间的文档老化,一个文档到达老化的程度之后就会被删除。
创建TTL的索引必须是日期类型。TTL索引是一种单字段索引,不能是复合索引。TTL删除文档后台线程每60s移除失效文档。不支持定长集合。
(7)需要在集合中某字段创建索引,但集合中大量的文档不包含此键值时,建议创建稀疏索引。
索引默认是密集型的,这意味着,即使文档的索引字段缺失,在索引中也存在着一个对应关系。在稀疏索引中,只有包含了索引键值的文档才会出现。
(8)创建文本索引时字段指定text,而不是1或者-1。每个集合只有一个文本索引,但是它可以为任意多个字段建立索引。
文本索引??
(9)使用findOne在数据库中查询匹配多个项目,它就会在自然排序文件集合中返回第一个项目。如果需要返回多个文档,则使用find方法。
(10)如果查询无需返回整个文档或只是用来判断键值是否存在,可以通过投影(映射)来限制返回字段,减少网络流量和客户端的内存使用。
既可以通过设置{key:1}来显式指定返回的字段,也可以设置{key:0}指定需要排除的字段。
(11)除了前缀样式查询,正则表达式查询不能使用索引,执行的时间比大多数选择器更长,应节制性地使用它们。
(12)在聚合运算中,$要在match要在$group前面,通过$前置,可以减少match前置,可以减少$ group 操作符要处理的文档数量。
(13)通过操作符对文档进行修改,通常可以获得更好的性能,因为,不需要往返服务器来获取并修改文档数据,可以在序列化和传输数据上花费更少的时间。
(14)批量插入(batchInsert)可以减少数据向服务器的提交次数,提高性能。但是批量提交的BSON Size不超过48MB。
(15)禁止一次取出太多的数据进行排序,MongoDB目前支持对32M以内的结果集进行排序。如果需要排序,请尽量限制结果集中的数据量。
(16)查询中的某些$操作符可能会导致性能低下,如操作符可能会导致性能低下,如$ne,$not,$exists,$nin,$or尽量在业务中不要使用。
- a)
$exist:因为松散的文档结构导致查询必须遍历每一个文档; - b)
$ne:如果当取反的值为大多数,则会扫描整个索引; - c)
$not:可能会导致查询优化器不知道应当使用哪个索引,所以会经常退化为全表扫描; - d)
$nin:全表扫描; - e)
\$有多个条件就会查询多少次,最后合并结果集,应该考虑装换为or:有多个条件就会查询多少次,最后合并结果集,应该考虑装换为$in。??
(17)固定集合可以用于记录日志,其插入数据更快,可以实现在插入数据时,淘汰最早的数据。需求分析和设计时,可考虑此特性,即提高了性能,有省去了删除动作。
crapped collections固定集合需要显式创建,指定Size的大小,还能够指定文档的数量。集合不管先达到哪一个限制,之后插入的新文档都会把最老的文档移出。
(18)集合中文档的数据量会影响查询性能,为保持适量,需要定期归档。
7、MongoDB数据库Java异步驱动指南
来自于MongoDB Async Driver Quick Tour
mongodb-java-driver 从3.0版本开始同时支持同步、异步方式(分别是不同的驱动应用)。异步的好处,众所周知,就是支持快速、非阻塞式的IO操作,可以提高处理速度。
注:MongoDB 异步驱动需要依赖Netty 或 Java 7。
7.1 执行异步回调
MongoDB异步驱动利用Netty或Java7的AsynchronousSocketChannel 来提供一个支持异步的API,以支持快速的、非阻塞式的IO操作。
该API形式和MongoDB同步驱动的新API保持一致,但是任何会导致网络IO的方法都会有一个SingleResponseCallback并且会立即返回,其中T是响应对于该文档的类型的任何方法。
SingleResponseCallback 回调接口需要实现一个简单方法onResult(T result, Throwable t) ,这个方法在操作完成时被调用。其中,如果操作成功, result参数包含着操作结果;如果操作失败,t中包含着抛出的异常信息。
7.2 创建一个连接
// 直接连接默认服务host和端口,即 localhost:27017
MongoClient mongoClient = MongoClients.create();
// 使用一个字符串
MongoClient mongoClient = MongoClients.create("mongodb://localhost");
// 使用一个ConnectionString
MongoClient mongoClient = MongoClients.create(new ConnectionString("mongodb://localhost"));
// 使用MongoClientSettings
ClusterSettings clusterSettings = ClusterSettings.builder().hosts(asList(new ServerAddress("localhost"))).build();
MongoClientSettings settings = MongoClientSettings.builder().clusterSettings(clusterSettings).build();
MongoClient mongoClient = MongoClients.create(settings);
// database 对象是一个MongoDB 服务器中指定数据库的连接。
MongoDatabase database = mongoClient.getDatabase("mydb");
注意:getDatabase("mydb") 方法并没有回调,因为它没有涉及网络IO操作。一个 MongoDatabase 实例提供了与数据库进行交互的方法,若数据库不存在,它会在插入数据时创建一个新的数据库。例如,创建一个 collection 或插入 document(这些确实需要回调,因为需要涉及网络IO)。
MongoClient:MongoClient 实例实际上代表了一个数据库的连接池;即使要并发执行异步操作,你也仅仅需要一个 MongoClient 实例。
重要:
一般情况下,在一个指定的数据库集群中仅需要创建一个MongoClient实例,并通过你的应用使用它。
当创建多个实例时:
- 所有的资源使用限制(例如最大连接数)适用于每个
MongoClient实例 - 销毁实例时,请确保调用
MongoClient.close()清理资源
7.3 获得一个collection
// 指定collection名称
MongoCollection<Document> collection = database.getCollection("test");
7.4 插入document
插入单个document
比如插入如下的文档内容,
{
"name" : "MongoDB",
"type" : "database",
"count" : 1,
"info" : {
x : 203,
y : 102
}
}
需要创建一个Document类,
Document doc = new Document("name", "MongoDB")
.append("type", "database")
.append("count", 1)
.append("info", new Document("x", 203).append("y", 102));
插入到数据库,
collection.insertOne(doc, new SingleResultCallback<Void>() {
@Override
public void onResult(final Void result, final Throwable t) {
System.out.println("Inserted!");
}
});
SingleResponseCallback 是一个 函数式接口 并且它可以以lambda方式实现(前提是你的APP工作在JDK8):
collection.insertOne(doc, (Void result, final Throwable t) -> System.out.println("Inserted!"));
一旦document成功插入,onResult 回调方法会被调用并打印“Inserted!”。记住,在一个普通应用中,你应该总是检查 t 变量中是否有错误信息。
添加多个document
要添加多个 documents,你可以使用 insertMany() 方法。
首先,循环创建多个Document
List<Document> documents = new ArrayList<Document>();
for (int i = 0; i < 100; i++) {
documents.add(new Document("i", i));
}
要插入多个 document 到 collection,传递 documents 列表到 insertMany() 方法.
collection.insertMany(documents, new SingleResultCallback<Void>() {
@Override
public void onResult(final Void result, final Throwable t) {
System.out.println("Documents inserted!");
}
});
7.5 document计数
collection.count(
new SingleResultCallback<Long>() {
@Override
public void onResult(final Long count, final Throwable t) {
System.out.println(count);
}
});
7.6 document查询
使用 find() 方法来查询 collection。
查询第一个document
collection.find().first(new SingleResultCallback<Document>() {
@Override
public void onResult(final Document document, final Throwable t) {
System.out.println(document.toJson());
}
});
注意:“_” 和 “$”开头的域是MongoDB 预留给内部使用的。
查询所有document
Block<Document> printDocumentBlock = new Block<Document>() {
@Override
public void apply(final Document document) {
System.out.println(document.toJson());
}
};
SingleResultCallback<Void> callbackWhenFinished = new SingleResultCallback<Void>() {
@Override
public void onResult(final Void result, final Throwable t) {
System.out.println("Operation Finished!");
}
};
collection.find().forEach(printDocumentBlock, callbackWhenFinished);
条件查询
import static com.mongodb.client.model.Filters.*;
collection.find(eq("i", 71)).first(printDocument);
重要:
使用 Filters、Sorts、Projections 和 Updates API手册来找到简单、清晰的方法构建查询。
查询一组document
import static com.mongodb.client.model.Filters.*;
// 使用范围查询获取子集
// 如果我们想获得所有 key 为“i”,value 大于50 的 document
collection.find(gt("i", 50)).forEach(printDocumentBlock, callbackWhenFinished);
//50 < i <= 100
collection.find(and(gt("i", 50), lte("i", 100))).forEach(printDocumentBlock, callbackWhenFinished);
document排序
通过在 FindIterable 上调用 sort() 方法,我们可以在一个查询上进行一次排序。
使用 exists() 和 降序排序 descending("i") 来为我们的 document 排序。
// FindIterable的sort方法
collection.find(exists("i")).sort(descending("i")).first(printDocument);
投射域
有时我们不需要将所有的数据都存在一个 document 中。Projections 可以用来为查询操作构建投射参数并限制返回的字段。
下面的例子中,我们会对collection进行排序,排除 _id 字段,并输出第一个匹配的 document。
// projection设置,需要包含"i"字段,不包含"_id"
BasicDBObject projections = new BasicDBObject();
projections.append("i", 1).append("_id", 0);
FindIterable<Document> findIter = collection.find().projection(projections);
聚合
有时,我们需要将存储在 MongoDB 中的数据聚合。 Aggregate 支持对每种类型的聚合阶段进行构建。
下面的例子,我们执行一个两步骤的转换来计算 i * 10 的值。首先我们使用 Aggregates.match 查找所有 i > 0 的document 。接着,我们使用 Aggregates.project 结合 $multiply 操作来计算 “i * 10” 的值。
collection.aggregate(asList(
match(gt("i", 0)),
project(Document.parse("{ITimes10: {$multiply: ['$i', 10]}}")))
).forEach(printDocumentBlock, callbackWhenFinished);
注意:
当前,还没有专门用于 聚合表达式 的工具类。可以使用 Document.parse() 来快速构建来自于JSON的聚合表达式。
对于 $group 操作使用 Accumulators 来处理任何 累加操作 。
下面的例子中,我们使用 Aggregates.group 结合 Accumulators.sum 来累加所有 i 的和。
collection.aggregate(singletonList(group(null, sum("total", "$i")))).first(printDocument);
7.7 更新document
更新一个document
import static com.mongodb.client.model.Filters.*;
//字段"i"的数值为10的document,设置"i"字段的数值为110
collection.updateOne(eq("i", 10), set("i", 110),
new SingleResultCallback<UpdateResult>() {
@Override
public void onResult(final UpdateResult result, final Throwable t) {
System.out.println(result.getModifiedCount());
}
});
更新多个document
import static com.mongodb.client.model.Filters.*;
// 使用 Updates.inc 来为所有 i 小于 100 的document 增加 100 。
collection.updateMany(lt("i", 100), inc("i", 100),
// UpdateResult 对象中包含了操作的信息(被修改的 document 的数量)
new SingleResultCallback<UpdateResult>() {
@Override
public void onResult(final UpdateResult result, final Throwable t) {
System.out.println(result.getModifiedCount());
}
});
7.8 删除document
删除一个document
// eq:等于
collection.deleteOne(eq("i", 110), new SingleResultCallback<DeleteResult>() {
@Override
public void onResult(final DeleteResult result, final Throwable t) {
System.out.println(result.getDeletedCount());
}
});
删除多个document
// gte:大于等于
collection.deleteMany(gte("i", 100), new SingleResultCallback<DeleteResult>() {
// DeleteResult对象包含了操作的信息(被删除的 document 的数量)
@Override
public void onResult(final DeleteResult result, final Throwable t) {
System.out.println(result.getDeletedCount());
}
});
7.9 批量操作
批量操作允许批量的执行 插入、更新、删除操作。
SingleResultCallback<BulkWriteResult> printBatchResult = new SingleResultCallback<BulkWriteResult>() {
@Override
public void onResult(final BulkWriteResult result, final Throwable t) {
System.out.println(result);
}
};
1.有序的批量操作
有序的执行所有操作并在第一个写操作的错误处报告错误。
// 有序批量操作
collection.bulkWrite(
Arrays.asList(new InsertOneModel<>(new Document("_id", 4)),
new InsertOneModel<>(new Document("_id", 5)),
new InsertOneModel<>(new Document("_id", 6)),
new UpdateOneModel<>(new Document("_id", 1),
new Document("$set", new Document("x", 2))),
new DeleteOneModel<>(new Document("_id", 2)),
new ReplaceOneModel<>(new Document("_id", 3),
new Document("_id", 3).append("x", 4))),
printBatchResult
);
2.无序的批量操作
执行所有的操作并报告任何错误。无序的批量操作不保证执行顺序。
// 无序批量操作
collection.bulkWrite(
Arrays.asList(new InsertOneModel<>(new Document("_id", 4)),
new InsertOneModel<>(new Document("_id", 5)),
new InsertOneModel<>(new Document("_id", 6)),
new UpdateOneModel<>(new Document("_id", 1),
new Document("$set", new Document("x", 2))),
new DeleteOneModel<>(new Document("_id", 2)),
new ReplaceOneModel<>(new Document("_id", 3),
new Document("_id", 3).append("x", 4))),
//无序设置
new BulkWriteOptions().ordered(false),
printBatchResult
);
重要:
不推荐在pre-2.6的MongoDB 服务器上使用 bulkWrite 方法。因为这是第一个支持批量写操作(插入、更新、删除)的服务器版本,它允许驱动去实现 BulkWriteResult 和 BulkWriteException 的语义。这个方法虽然仍然可以在pre-2.6服务器上工作,但是性能不好,一次只能执行一个写操作
7.10 事务操作
从MongoDB 4.0开始支持事务操作。只支持集群和分片模式
同步
try (ClientSession session = client.startSession()) {
//start
session.startTransaction();
try {
//操作
collection.insertOne(session, documentOne);
collection.insertOne(session, documentTwo);
//commit
session.commitTransaction();
} catch (Exception e) {
//抛弃该session
session.abortTransaction();
}
}
异步(待测试)
//开始一个session,会异步得到一个ClientSession
generalMgdInterface.getClient().startSession(new SingleResultCallback<ClientSession>() {
@Override
public void onResult(final ClientSession sess, final Throwable t) {
if(t != null) {
logger.warn("StartSession Throwable is not null",t);
}
//如果支持事务,则不开启
if(sess != null) {
//start
sess.startTransaction();
}
try {
//数据库操作
//.....
//commit
if(sess != null) {
sess.commitTransaction(new SingleResultCallback<Void>() {
@Override
public void onResult(final Void result, final Throwable t) {
}
});
}
}catch(Exception e) {
logger.error("",e);
if(sess != null) {
//抛弃 该 session
sess.abortTransaction(new SingleResultCallback<Void>() {
@Override
public void onResult(final Void result, final Throwable t) {
}
});
}
}
}
});
X、概念
SQL和MongoDB
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | - | 表连接,MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
MongoDB的格式
| id | user_name | age | city | |
|---|---|---|---|---|
| 1 | Mark Hanks | mark@abc.com | 25 | Los Angles |
{
"_id":ObjectId("5146bb52d8524270060001f3"),
"age":25,
"city":"Los Angeles",
"email":"mark@abc.com",
"user_name":"Mark Hanks"
}
注:ObjectId数据类型包括12bytes,前4个时间戳(格林尼治时间UTC),下面3个字节是机器识别码,下面2个字节是进程id组成PID,最后3个字节是随机数。
数据库命名
1、不能是空字符串(””)。
2、不得含有’ ‘(空格)、.、$、/、\和\0 (空字符)。
3、应全部小写。
4、最多64字节。
MongoDB保留的数据库
admin: 从权限的角度来看,这是”root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档
文档是一组键值(key-value)对(即BSON)。
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
MongoDB的数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
- ObjectId
前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
接下来的 3 个字节是机器标识码
紧接的两个字节由进程 id 组成 PID
最后三个字节是随机数

var newObject = ObjectId()
newObject.getTimestamp()
newObject.str
- 时间戳
BSON有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。
64bits:[0:31],time_t,与Unix新纪元相差的秒数;[32:63],某秒中操作的一个递增的序数。
连接池
关系型数据库(如MySQL)中,我们做连接池无非就是事先建立好N个连接(connection),并构建成一个连接池(connection pool),提供去连接和归还连接等操作。
MongoDB实例其实已经是一个现成的连接池了,而且线程安全。这个内置的连接池默认初始了10个连接,每一个操作(增删改查等)都会获取一个连接,执行操作后释放连接。
MongoDB的连接池参数
- connectionsPerHost:每个主机的连接数
- threadsAllowedToBlockForConnectionMultiplier:线程队列数,它以上面connectionsPerHost值相乘的结果就是线程队列最大值。如果连接线程排满了队列就会抛出“Out of semaphores to get db”错误。
- maxWaitTime:最大等待连接的线程阻塞时间
- connectTimeout:连接超时的毫秒。0是默认和无限
- socketTimeout:socket超时。0是默认和无限
- autoConnectRetry:这个控制是否在一个连接时,系统会自动重试
MongoOptions opt = mongo.getMongoOptions();
opt.connectionsPerHost = 10 ;//poolsize
opt.threadsAllowedToBlockForConnectionMultiplier = 10;
欢迎关注我的微信公众号
互联网矿工
