1.操作系统结构
1.1 操作系统的定位
graph TB;
软件 --> 应用软件
软件 --> 系统软件
系统软件 --> 系统应用
系统软件 --> 操作系统
操作系统 --> 命令行
操作系统 --> 内核
其中操作系统分为命令行和内核,
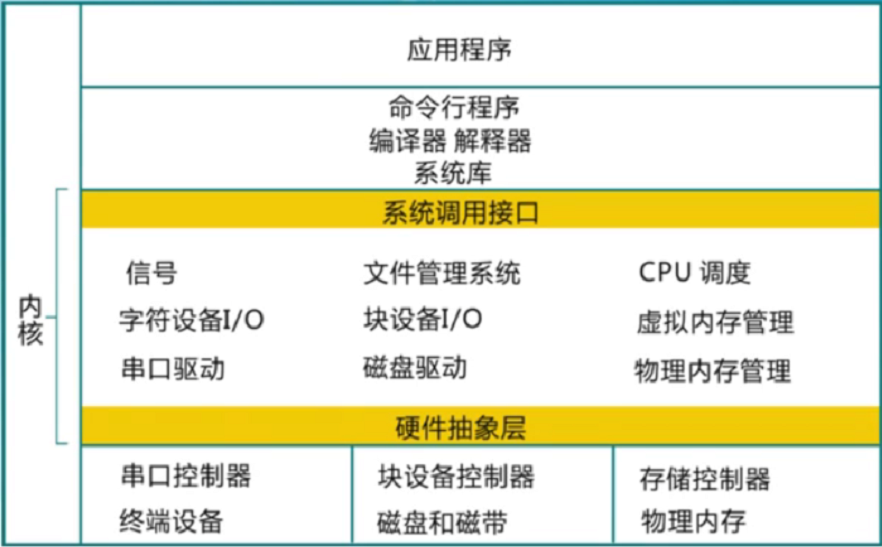
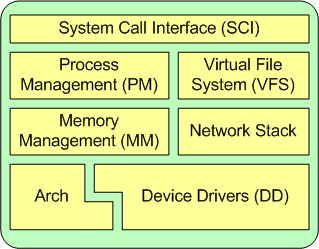
其中内核包括系统调用接口、进程管理、内存管理、虚拟文件系统、网络堆栈、设备驱动代码、依赖体系结构的代码等。
1.2 操作系统演变
(1)单用户系统
程序只能一段一段执行。
(2)批处理系统
打印等IO操作会占用大量的时间,而CPU利用率会因为IO操作大大降低。
CPU利用率=执行时间/(执行时间+IO操作时间)
为了提高CPU利用率,批处理系统一次执行多个代码,这些代码的打印操作一块进行,减小打印时间,即提高CPU利用率。
(3)多道程序
多道程序利用一段程序等待IO操作完成的时间,进行另外一段程序的执行,实现了CPU复用。
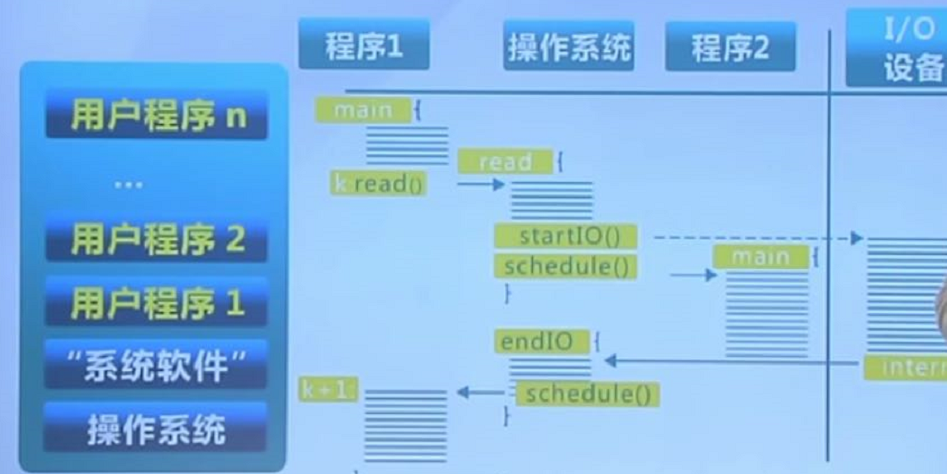
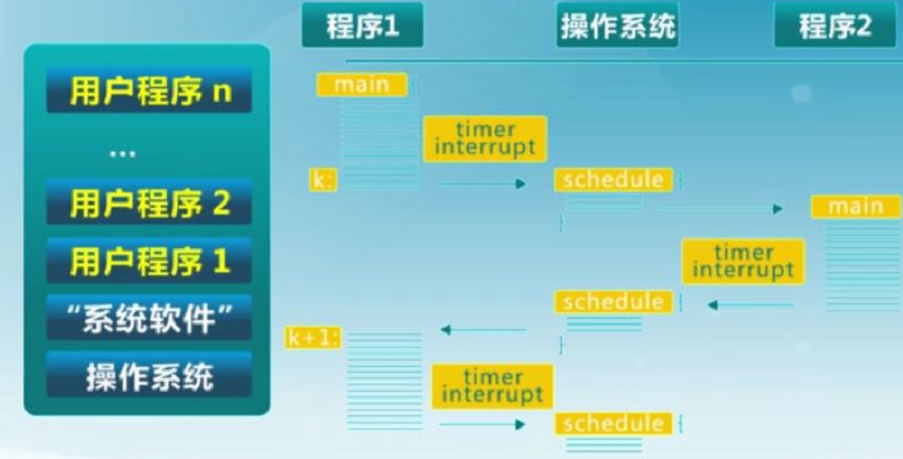
(4)分时
通过定时中断,实现CPU复用。分时没有提升CPU利用率,甚至降低了CPU利用率,但是减小了小段(执行时间短)程序的执行等待时间,让用户体验到并行执行的感觉,而不是要等待前面的任务执行完毕。
(5)个人计算机
每个用户一个系统。
(6)分布式计算机
每个用户多个系统。
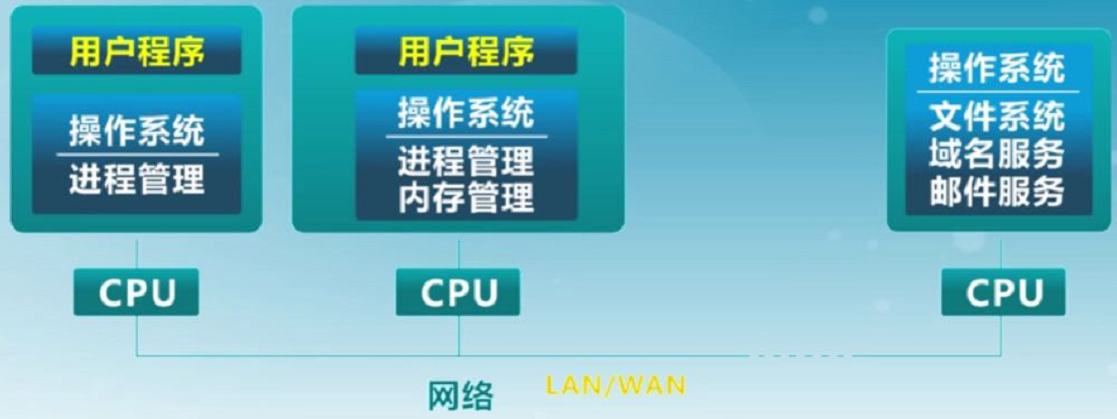
2.3 操作系统结构
-
分层结构
-
微内核结构
由于分层结构中内核包含功能太多,造成效率下降。微内核为解决分层结构的效率问题,将一些功能放到用户态(用户空间),内核中只保留进程间通信和硬件抽象层。用户模块间的通信通过内核,使用消息传递。
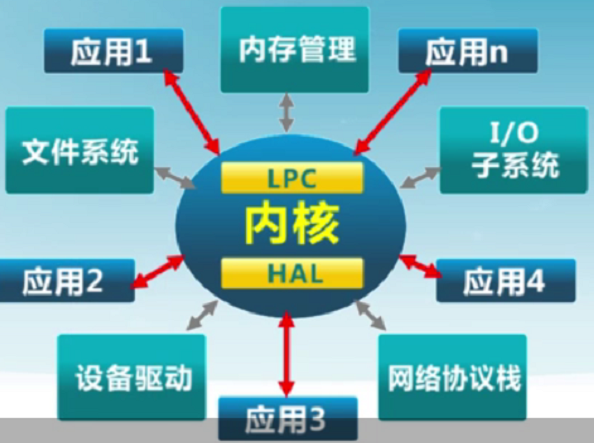
内核空间里存放的是整个内核代码和所有内核模块,以及内核所维护的数据。当用户运行一个程序时,该程序所创建的进程一开始是运行在用户空间的,当它要执行网络发送数据等动作时,必须通过调用write、send等系统函数来完成,这些系统调用会去调用内核中的代码来完成用户的请求操作,这时CPU必须从ring3切换到ring0,然后进入内核地址空间去执行这些代码完成操作,完成后又切换回ring3,回到用户态。
-
外核结构
外核只负责资源的分配 。让外核分配机器的物理资源给多个应用程序,并每个程序决定如何处理这些资源。
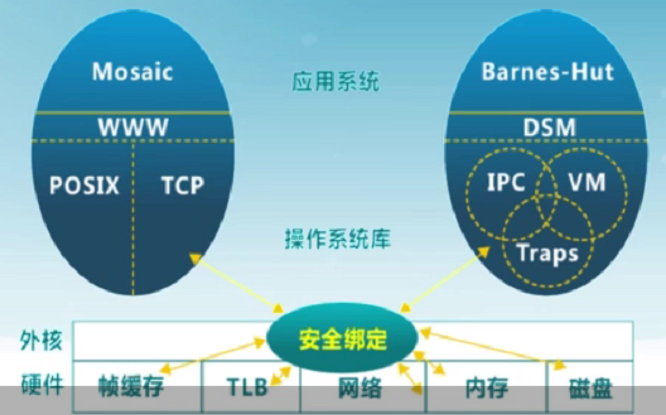
-
虚拟机管理器VMM
虚拟机管理器负责将真实硬件映射成多个虚拟硬件。VMM决定虚拟机可以使用具体的资源。
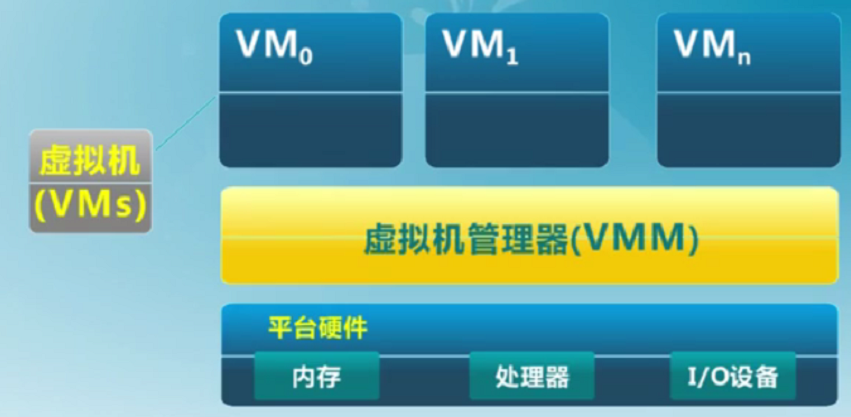
2.中断及系统调用
2.1 BIOS
2.1.1 加载程序

实模式下最多访问1MB空间。BIOS(启动)固件的功能:
-
基本输入输出的程序
完成从磁盘读数据、从键盘读输入
-
系统设置信息
设置系统从哪里启动,如网络、磁盘等
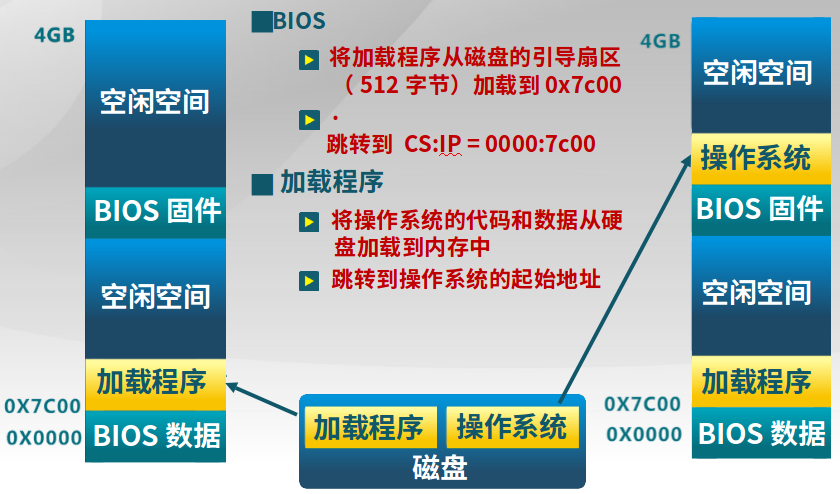
具体的加载过程如下:
-
BIOS固件
1.将磁盘中的引导扇区(引导扇区的文件系统格式固定,使得BIOS认识)的加载程序加载到的内存的0x7c00
2.跳转到CS:IP = 0000:7c00
-
加载程序
3.将操作系统的代码和数据从硬盘(文件系统为加载程序认识)加载到内存
4.跳转到内存中的操作系统起始地址开始执行
2.1.2 BIOS系统调用
只能在实模式下工作。
BIOS以中断调用的方式,提供了基本的IO功能:
- INT 10h:字符显示
- INT 13h:磁盘扇区读写
- INT 15h:检测内存大小
- INT 16h:键盘输入
为什么不是直接从文件系统中加载代码,还要一个加载程序?
磁盘文件系统多种多样,机器出厂时不可能在BIOS中加入认识所有文件系统的代码。所以在有一个基本的约定,可以读取加载程序,将代码和数据从硬盘加载到内存中。
2.2 系统启动流程
2.2.1 系统启动流程
在现有计算机中,可能有多个磁盘、系统,所以需要一个主引导分区,再由主引导分区指向特定的活动分区。
BIOS -> 主引导记录(主引导扇区代码) -> 活动分区的引导扇区代码 -> 加载程序 -> 启动菜单(可选的操作系统内核列表和加载参数) -> 根据配置加载指定内核并跳转到内核执行
-
1.CPU初始化
1.1 CPU加电稳定后从0XFFFF0读第一条指令
CS:IP=0xF000:FFF0第一条指令是跳转指令
1.2 CPU初始化为16位实模式
CS:IP都是16位寄存器,但是IP只用了4位。
指令指针
PC = 16*CS+IP最大地址空间是1MB(20位)
-
2.BIOS初始化
2.1 硬件自检POST
2.2 检测系统中内存和显卡等关键部件的存在和工作状态
比如内存有问题,系统不会工作
2.3 查找并执行显卡等接口卡BIOS,进行设备初始化
2.4 执行系统BIOS,进行系统检测
检测和设置系统中安装的即插即用设备
2.5 更新CMOS中的拓展系统设置数据ESCD
ESCD里面保存了拓展设备的信息,比如USB等
2.6 按指定顺序从软盘、硬盘或者光驱启动
-
3.主引导分区MBR(Master Boot Record)

-
启动代码:446字节
检查分区表正确性
加载并跳转到磁盘上对应活动分区的引导程序
-
硬盘分区表:64字节
描述分区状态和位置
每个分区描述信息占据16字节,最多4个
-
结束标准
-
-
4.分区引导扇区

-
跳转指令JMP
与平台相关的代码
-
文件卷头
文件系统描述信息
-
启动代码
跳转到加载程序bootloader
-
结束标志
-
2.3.1 系统启动规范
-
BIOS
-
固化到计算机主板上的程序
- 包括系统设置、自检程序和系统自启动程序
- BIOS-MBR(主引导记录,为了满足从几个分区中选择一个启动,最多4个,见上面解释)、BIOS-GPT(全局唯一标识表,在分区表中描述更多的分区结构)、PXE(满足从网络上加载内核,BIOS中需要加入通信栈)
-
-
UEFI
- 接口标准
- 在所有平台上一致的操作系统启动服务,只有可信的才会加载
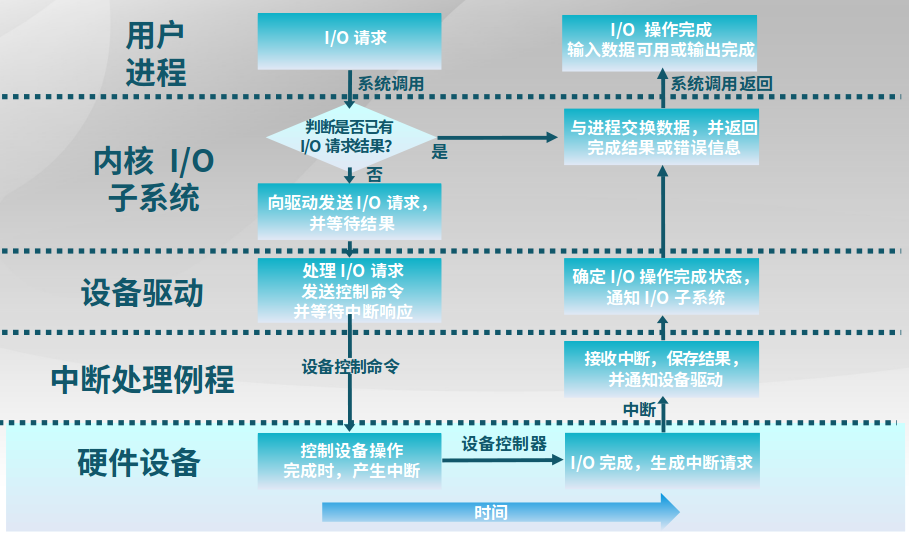
2.3 中断、异常和系统调用
2.3.1 介绍
和内核 打交道的方法包括中断(来自硬件设备的处理请求)、异常(非法指令或者其他原因导致当前指令执行失败后的处理请求)、系统调用(应用程序主动向操作系统发出的服务请求),具体信息流见下图。
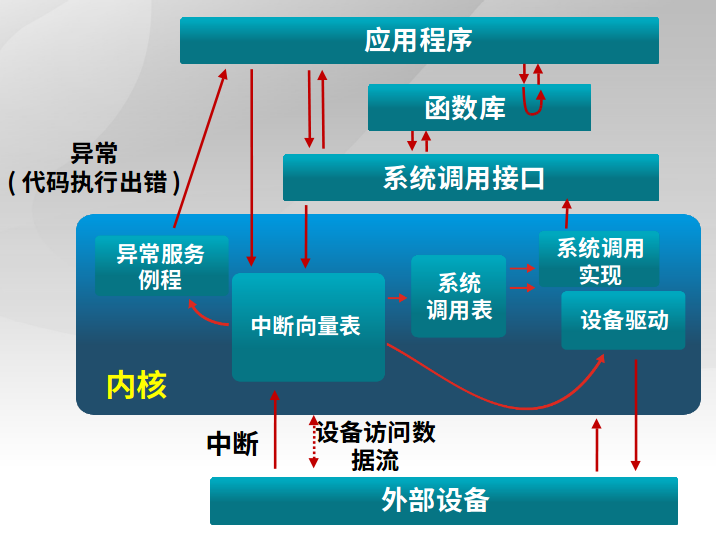
异常处理可嵌套,就像中断可嵌套一样。
2.3.2 中断描述符表的作用
(1)中断描述符表
中断向量和中断服务例程的对应关系主要是由IDT(中断描述符表)负责。操作系统在IDT中设置好各种中断向量对应的中断描述符,留待CPU在产生中断后查询对应中断服务例程的起始地址。而IDT本身的起始地址保存在IDTR寄存器中。同GDT一样,IDT是一个8字节的描述符数组,但IDT的第一项可以包含一个描述符。
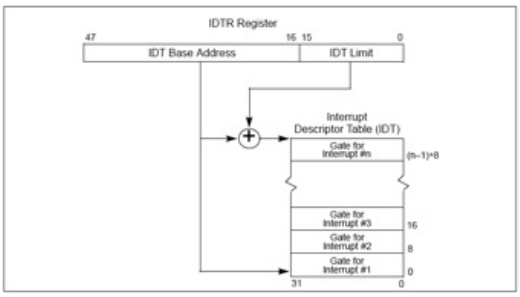
LIDT和SIDT两条指令用于操作IDTR寄存器(一个6字节)。
-
LIDT(Load IDT Register)指令
使用一个包含线性地址基址和界限的内存操作数来加载IDT。
-
SIDT(Store IDT Register)指令
拷贝IDTR的基址和界限部分到一个内存地址。这条指令可以在任意特权级执行。
在保护模式下,最多会存在256个Interrupt/Exception Vectors。范围[0,31]内的32个向量被异常Exception和NMI使用,但当前并非所有这32个向量都已经被使用,有几个当前没有被使用的,请不要擅自使用它们,它们被保留,以备将来可能增加新的Exception。
(2)IDT gate descriptors
Interrupts/Exceptions应该使用Interrupt Gate和Trap Gate,它们之间的唯一区别就是:当调用Interrupt Gate时,Interrupt会被CPU自动禁止;而调用Trap Gate时,CPU则不会去禁止或打开中断,而是保留它原来的样子。下面是三种门的结构,任务门没有使用。
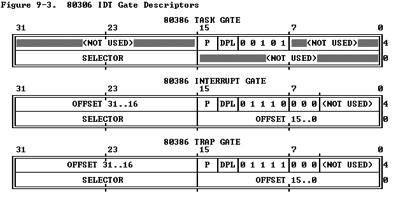
(3)中断处理中硬件负责完成的工作
-
起始
从CPU收到中断事件后,打断当前程序或任务的执行,根据某种机制跳转到中断服务例程去执行的过程。
(1)CPU每次执行完一条指令,都会检查有无中断,如果有则会读取总线上的中断向量
(2)CPU根据得到的中断向量,到IDT中找到该中断向量的段选择子
(3)根据段选择子和GDTR寄存器中保存的段描述符起始地址,找到了相应的段描述符中,保存了中断服务函数的段基址和属性信息,基地址加上IDT中的Offset就得到了中断服务函数的地址。以下是IDT找到相应中断服务程序的过程:
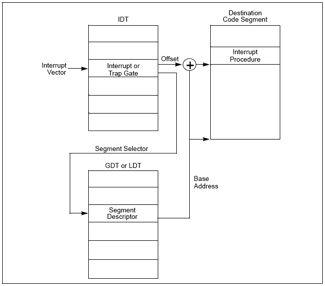
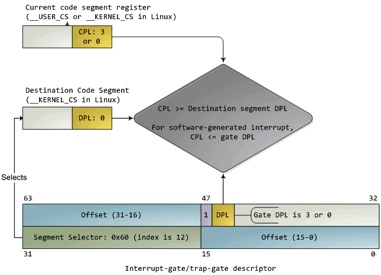
(4)CPU根据IDT的段选择子中的CPL和中断服务函数的GDT(段描述符)中的DPL确认是否发生了特权级的改变。比如当前程序处于用户态(ring3),而中断程序运行在内核态(ring0),意味着发生了特权级的转换。CPU会从当前的程序的TSS信息(该信息在内存中的起始地址存在TR寄存器中)里取得该程序的内核栈地址,即包括内核态的SS(堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值)和ESP寄存器(堆叠指标暂存器,存放栈的偏移地址,指向栈顶)。CPU切换到相应的内核栈。
(5)CPU保存被打断程序的现场(一些寄存器的值),比如用户态切换到了内核态,需要保存EFLAGS、CS、EIP、ERROR CODE(如果是有错误码的异常)信息
(6)CPU加载第一条指令
-
结束
每个中断服务例程在有中断处理工作完成后需要通过IRET(或IRETD)指令恢复被打断的程序的执行。
(1)IRET指令执行,从内核栈弹出先前保存的被打断的程序的现场信息,如EFLAGS、CS、EIP
(2)如果存在特权级转换(内核态到用户态),则还需要从内核栈弹出用户态栈的SS和ESP,回到用户态的栈
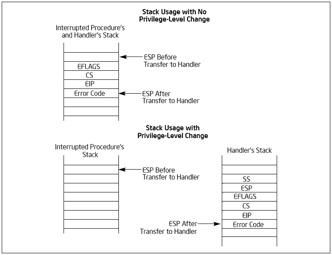
(3)如果此次处理的是带有错误码的异常,CPU恢复先前程序的现场时,不会弹出错误码。这一步需要软件完成,相应的中断服务函数在掉用IRET返回之前,添加出栈代码主动弹出错误码。
以下是优先级未切换和切换时的栈变换,
2.4 系统调用
2.4.1 系统调用举例
-
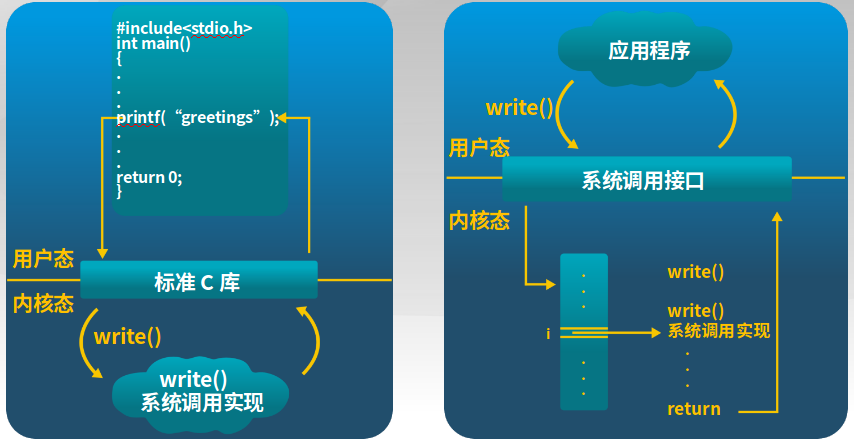
printf函数的系统调用过程
printf为标准C库,其实C库是调用的内核的write(),并且有多个不同的write函数,实现指向文件等。
-
三种常用的应用程序变成接口
- win32 API用于windows
- POSIX API用于POSIX-based systems(Unix、Linux、Mac OS X的所有版本)
- Java API用于Java虚拟机
2.4.2 系统调用的实现
系统调用接口根据系统调用号来维护表的索引,具体为应用程序调用系统调用接口,系统调用接口通过软中断来选择系统调用表的功能(每个功能对应一个编号)。
系统调用和函数调用的区别?
-
系统调用
INT和IRET(Int RETurn)指令用于系统调用。函数调用时,堆栈切换(内核态和用户态使用不同的堆栈)和特权级的转换。
-
函数调用
CALL和RET用于常规调用,没有堆栈切换。
2.5 系统调用实例
1. kern/trap/trapentry.S: alltraps()
2. kern/trap/trap.c: trap()
tf->trapno == T_SYSCALL // 发现是系统调用
3. kern/syscall/syscall.c: syscall()
tf->tf_regs.reg_eax ==SYS_read // 发现是系统调用的读取函数
4. kern/syscall/syscall.c: sys_read()
从 tf->sp 获取 fd, buf, length //参数
5. kern/fs/sysfile.c: sysfile_read()
读取文件
6. kern/trap/trapentry.S: trapret() //返回
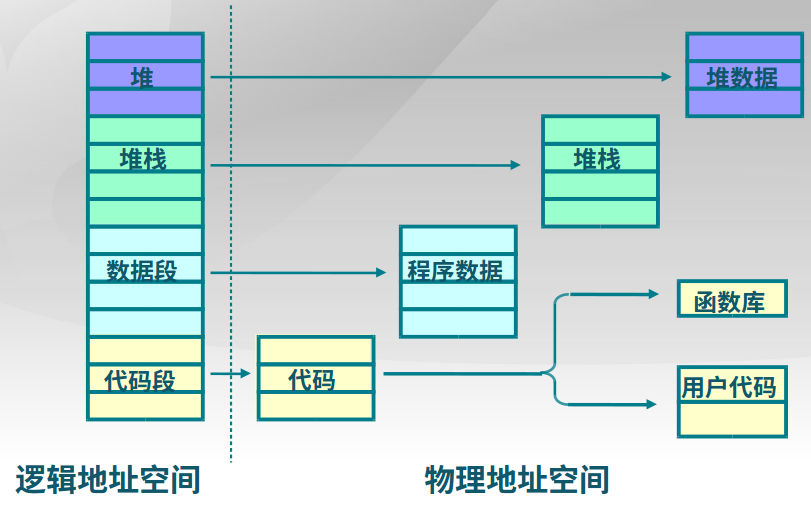
3.内存管理
3.1 计算机体系结构和内存层次
-
内存管理的功能和概念
计算机内存管理需要MMU实现从逻辑地址空间的抽象,地址空间的保护,内存空间的共享和虚拟化实现最大的地址空间。
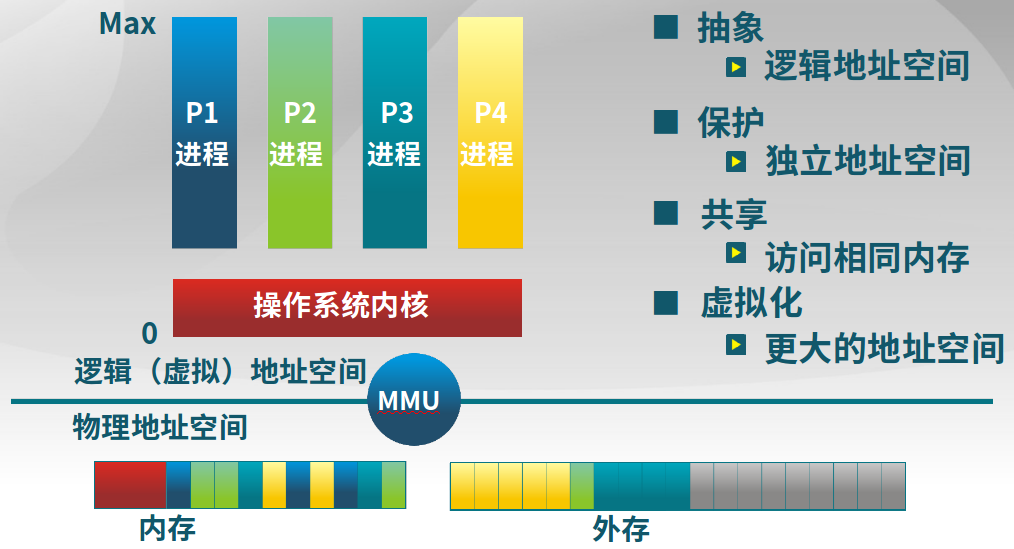
-
内存管理方式
与计算机存储架构紧耦合、MMU(内存管理单元)处理CPU处理访问请求的硬件
-
重定位(relocation)
比如通过段地址+偏移的方式将代码、数据进行整体偏移。
-
分段(segmentation)
分成代码、数据和堆栈
-
分页(paging)
将内存分成最基本的单位
-
虚拟存储(virtual memory)
可以实现比物理地址空间更大的虚拟地址空间
目前多数系统(如Linux)采用按需页式虚拟存储
-
3.2 地址空间和地址生成
-
物理地址
-
逻辑地址
CPU运行的进程看到的地址
3.2.1 地址生成
计算机先进性编译,然后汇编,汇编生成的文件(如.o文件)需要有明确的地址(如下面的jmp 75),而不是以函数符号代替地址(如jmp _foo)。包括后面要做的链接(如模块A需要调用模块B的函数),将模块和用到的模块、库函数放在一起,排成一个线性的序列,这个时候要生成对应的链接地址(如下面的jmp 175,这个175是在)。程序加载表示,程序真实运行的时候,不是从0开始,需要重定位到物理地址。
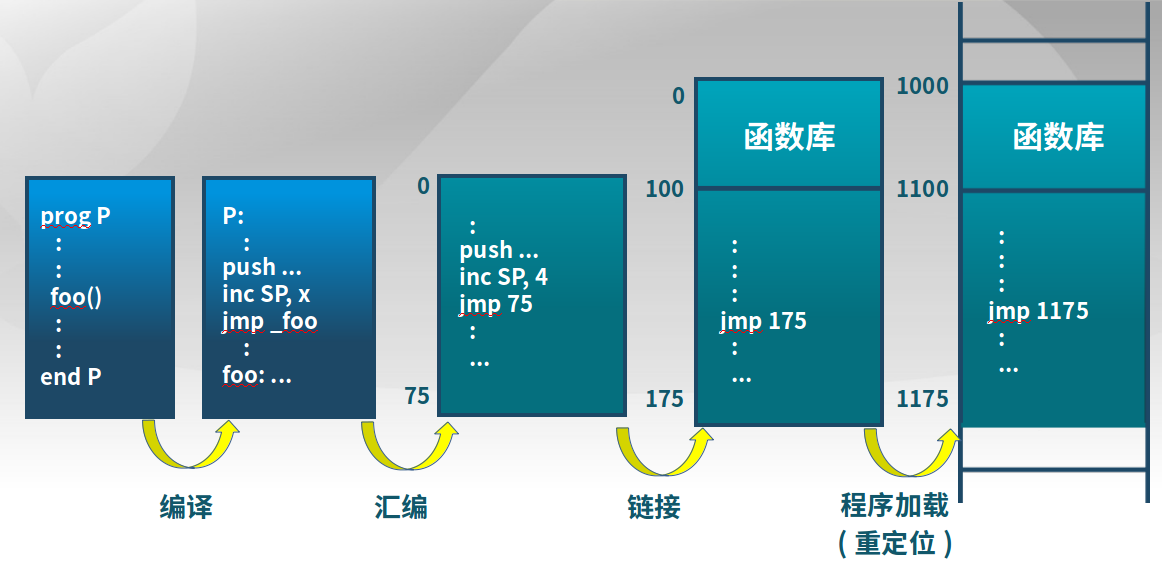
所以说,地址生成包含几个时机:
-
编译时
假设起始地址已知
如果起始地址改变,需要重新编译
-
加载时
编译时起始地址未知,编译器需要生成可重定位的代码
加载时,生成绝对地址,此后地址难以改变
-
执行时
执行时代码可移动
需要地址转换(映射)硬件支持
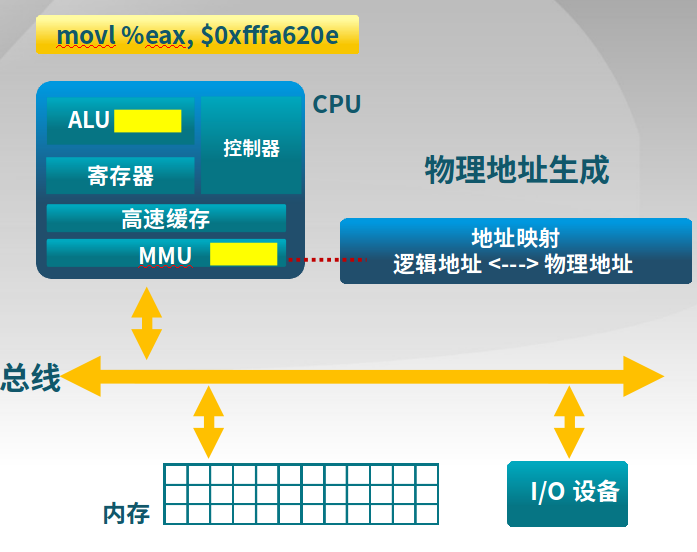
详细的逻辑地址到物理地址的转换
- CPU
- ALU:需要逻辑地址的内存内容
- MMU:进行逻辑地址和物理地址的转换
- CPU控制逻辑:给总线发送物理地址请求
- 内存
- 发送物理地址给CPU
- 或者接收CPU数据到物理地址
- 操作系统
- 建立逻辑地址LA和物理地址PA的映射,供MMU实现逻辑地址和物理地址的转换。
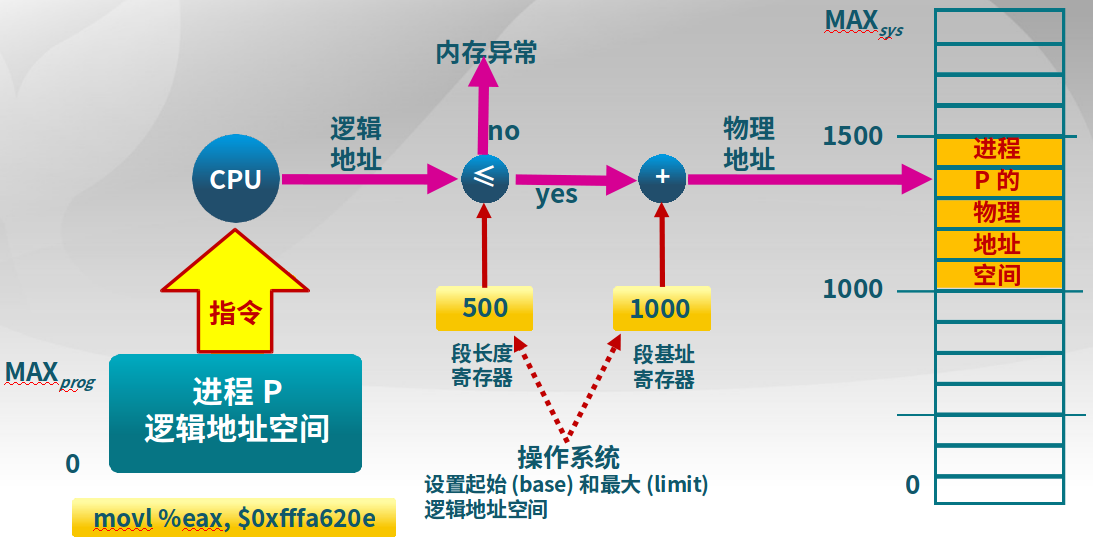
3.2.1 地址检查
操作系统可以设置最大逻辑地址空间,如果逻辑地址过多,会超出,出现内存异常。
3.3 连续内存分配
3.3.1 内存碎片的概念
给进程分配一块不小于指定大小的连续的物理地址区域
-
内存碎片
进程结束后,空闲出来的内存不能被利用
-
外部碎片
分配单元之间的未被使用内存
-
内部碎片(2的整数幂空间被占用了一部分,剩下的部分不能被利用)
分配单元内部的未被使用内存
取决于分配单元大小是否要取整
3.3.2 动态分区分配
-
动态分区分配
当程序被加载执行时,分配一个进程指定大小可变的分区(块、内存块),分区的地址是连续的。
-
操作系统维护的数据结构
- 所有进程的已分配分区
- 空闲分区(Empty-blocks)
-
动态分区分配策略
-
最先匹配
原理和实现
-
空闲分区列表按地址顺序排序
- 分配过程中,搜索第一个合适的分区
- 释放分区时,检查是否可与临近的空闲分区合并
优点
- 简单
- 在高地址空间有大块的空闲分区
缺点
- 产生较多外部碎片
- 分配大块时较慢,需要搜索到较为后面
-
-
最优匹配(找最小适配的)
原理和实现
- 空闲分区列表按照大小排序
- 分配时,查找一个合适的分区
- 释放时,查找并且合并临近的空闲分区(如果能找到)
优点
- 大部分分配的尺寸较小时,效果较好
- 避免大的空闲分区被拆分,可减小外部碎片的大小,并且相对简单
缺点
- 外部碎片太小,无法使用
- 维护空闲分区开销较大
-
最差匹配(找最大的)
原理和实现
- 空闲分区列表按由大到小排序
- 分配时,选最大的分区
- 释放时,检查是否可与临近的空闲分区合并,进行可能的合并,并调整空闲分区列表顺序
优点
- 中等大小的分配较多时,效果最好
- 避免出现太多的小碎片
缺点
- 释放分区较慢
- 容易破坏大的空闲分区,因此后续难以分配大的分区
-
3.3.3 碎片整理
调整进程占用的分区位置,来减少或者避免分区碎片
-
碎片紧凑
要求所有的应用程序可动态重定位
-
分区对换
通过抢占并回收处于等待状态进程的分区,以增大可用内存空间
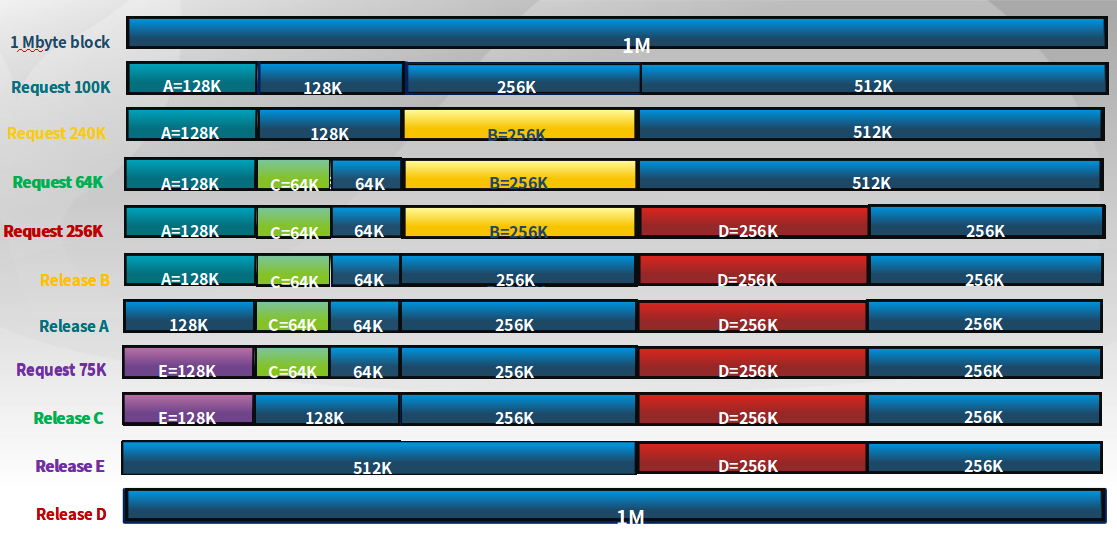
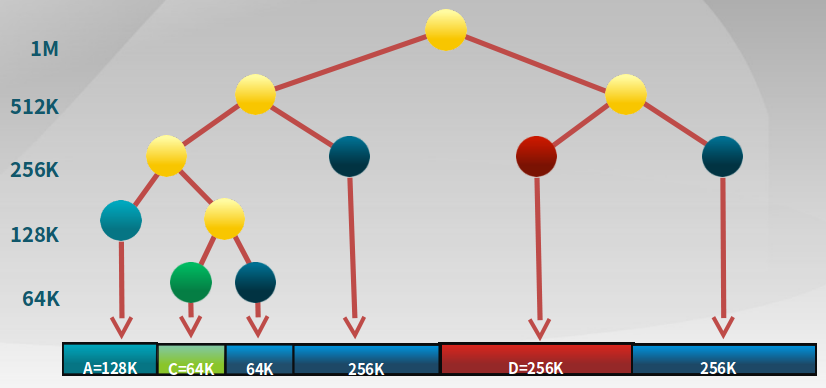
3.3.5 伙伴系统(Buddy System)
一种连续空间分配的方法,整个可分配的分区大小为2^u。
-
数据结构
-
按照大小和起始地址组织成二维数组
-
初始状态,只有一个大小为
2^u的空闲块
-
-
分配过程
- 如
s ≤2^i-1,将大小为2^i的当前空闲分区划分成两个大小为2^i-1的空闲分区 - 重复划分过程,直到
2^i-1 < s ≤ 2^i,并把一个空闲分区分配给该进程 - 在进程内存回收时,连续空闲空间是否能够合并,也要满足合并后可分配的分区大小为
2^u,而不是连续就能合并的。
- 如
以下是一个伙伴系统内存分配举例:
以下是一个树,也是一种存放空闲块大小和起始地址的结构:
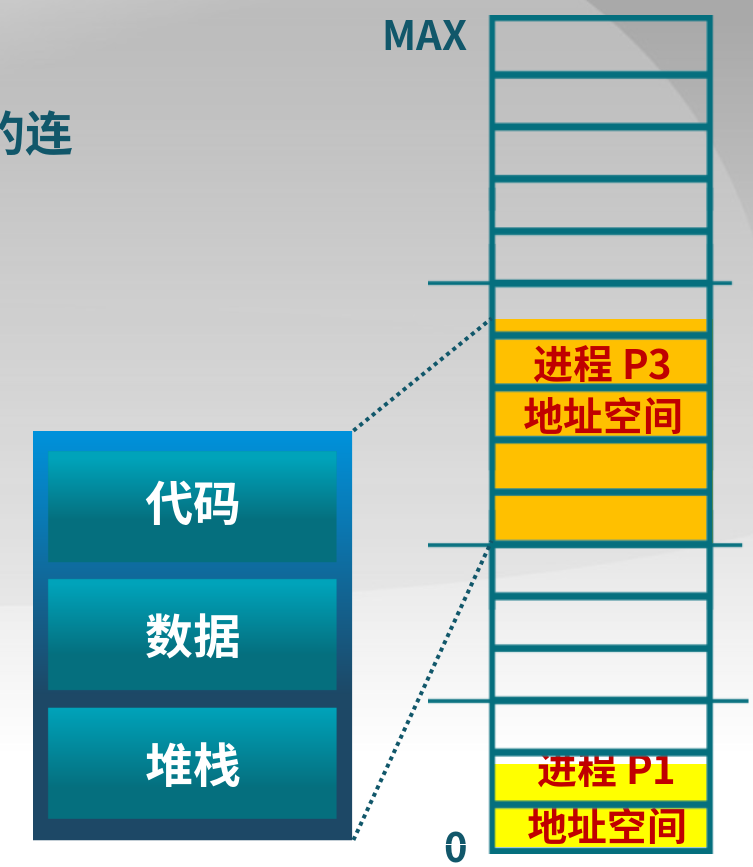
3.4 非连续内存分配
允许一个程序使用非连续的物理地址空间;允许共享代码与数据;支持动态加载和动态链接。
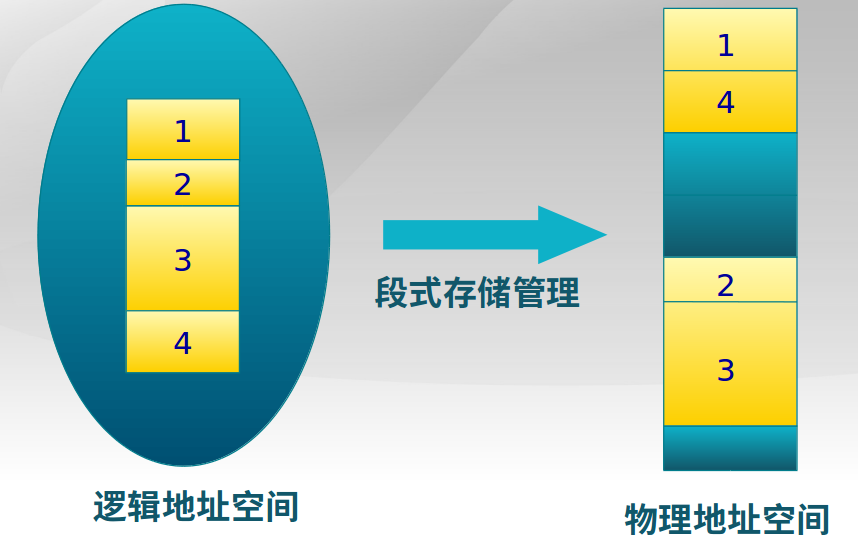
3.4.1 段式存储管理
以段为最小连续单位,段必须连续,不同段之间可以不连续。段的大小很有可能是不一样的。
-
逻辑地址和物理地址
进程段地址空间由多个段组成:
- 主代码段
- 子模块代码段
- 共用库代码段
- 堆栈段(stack)
- 堆数据(heap)
- 初始化数据段
- 符号表
-
段访问机制
段表示访问方式和存储数据等属性相同的一段地址空间,对应一个连续的内存块,若干个段组成进程逻辑地址空间
-
段访问
逻辑地址由二元组
(段号, 段内偏移)表示。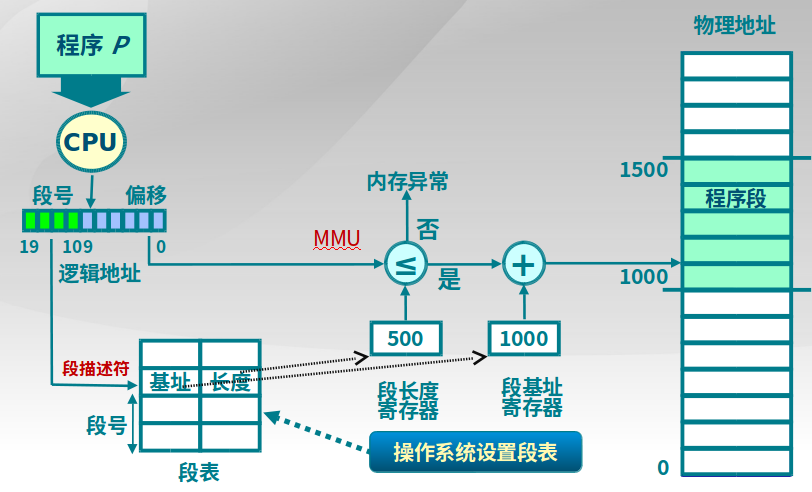
-
3.4.2 页式存储管理
用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。
-
页帧(帧、物理页面,Frame,Page Frame)
以页为单位来分配,页与页之间可以不连续。页帧把物理地址空间划分为大小相同的基本分配单位,
2^n字节。 -
页面(页、逻辑页面,Page)
把逻辑地址空间也划分为相同大小的基本分配单位,页帧和页面的大小必须相同
-
地址空间描述方式
二元组
(页号, 页内偏移)来表示地址空间,页帧和页面的表达方式相同,只是页号会经过转换。 -
页表
描述了页面到页帧的转换关系(逻辑页号到物理页号),而MMU(存储管理单元)和TLB(快表)实现了转换。下面是逻辑地址(页面)到物理地址(页帧)的转换:
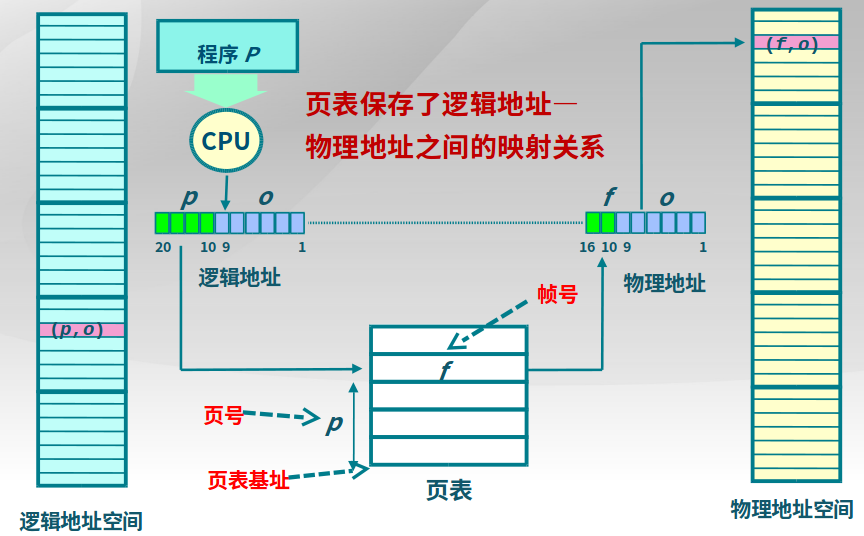
- 每个进程都有一个页表,每个页面对应一个页表项
- 随着进程运行,页表动态变换,也就是会给进程动态分配空间
- 页表基址寄存器(PTBR, Page Table Base Register)保存了页表的基址。
页表项除了包含物理页面页号,也包含存在位、修改位、引用位。

3.4.3 快表和多级页表
-
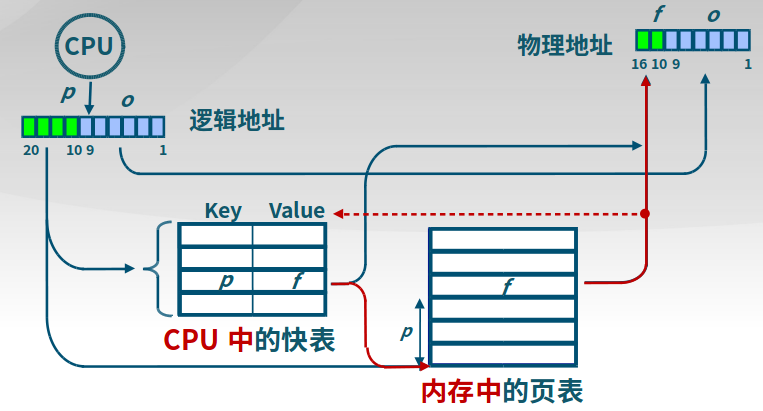
快表
快表(Translation Look-aside Buffer, TLB),用于缓存近期访问的页表项。
- TLB 使用关联存储(associative memory)实现,具备快速访问性能
- 如果TLB命中,物理页号可以很快被获取
- 如果TLB未命中,对应的表项被更新到TLB中
-
多级页表
通过间接引用将页号分成k级
- 建立页表“树”
- 减少每级页表的长度
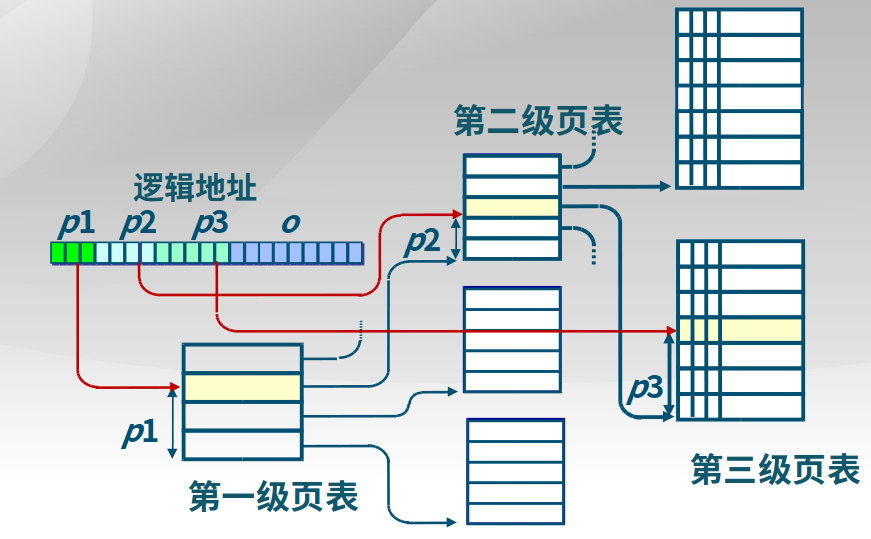
下面是一个简单的二级页表实例,因特尔芯片的CR3寄存器中存储起始位置PTBR。
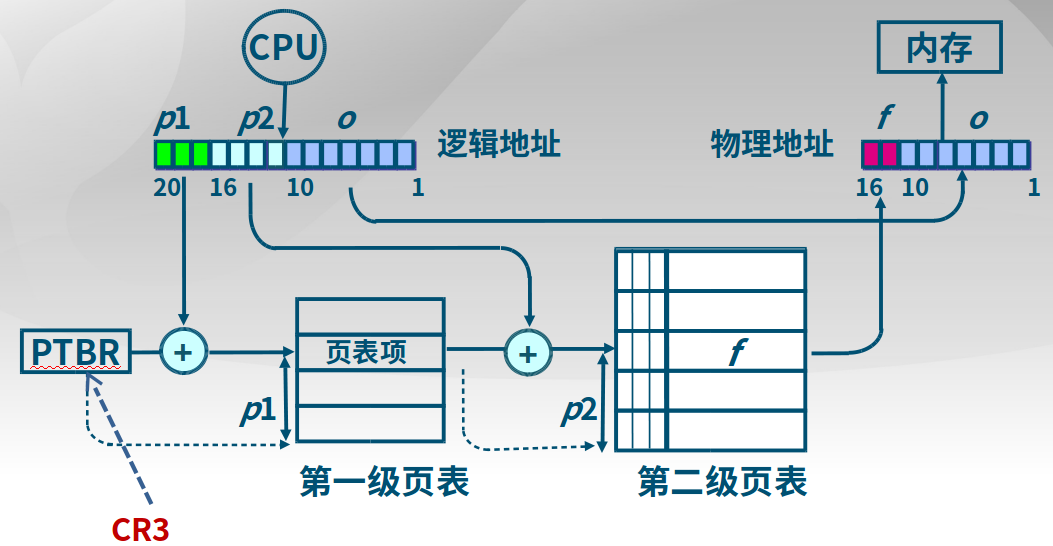
3.4.4 反置页表
对于大地址空间(64bits)系统,多级页表变得繁琐,因为需要多次访问地址空间。和多级页表的区别:
多级页表相当于给某一块区域设置了搜索方式,而反置页表是一个页表项对应一个帧。
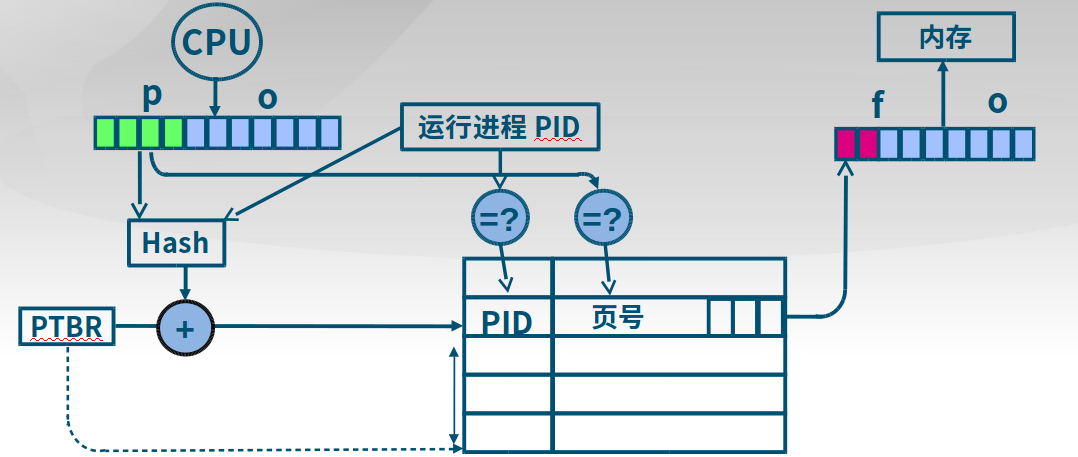
下面是反置页表查询过程,通过hash实现,如果发生冲突,则查找链表中的下一个。
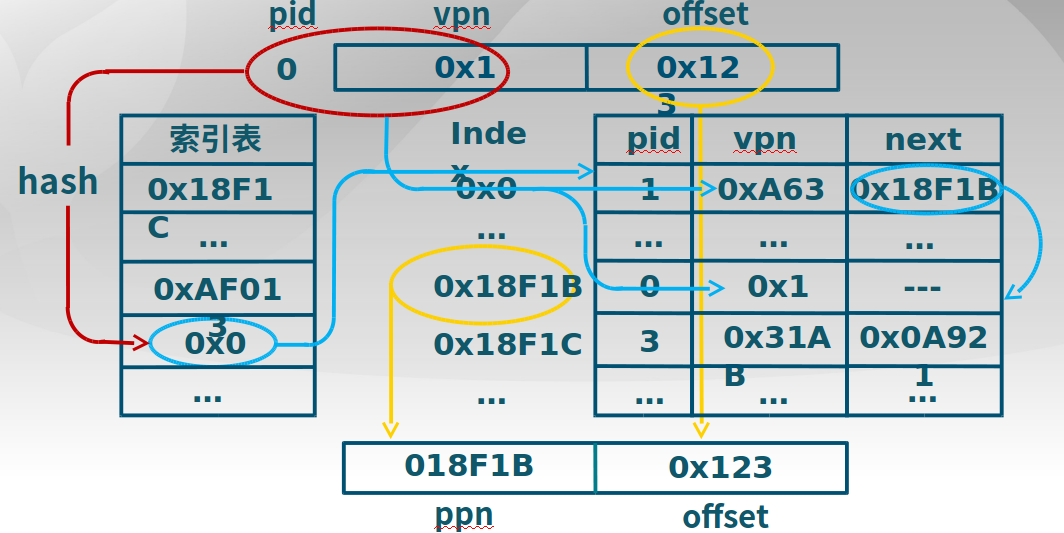
冲突解决:hash后找到了一个pid为1的页表项,但是不正确,此时查找链表的下一个页表项,可以验证是正确的。见下图。
几种页表的总结
-
快表
通过缓存机制,减少对页表的访问
-
多级页表
多级减少页表的大小,但是页表过多可能造成越来越多的浪费。
-
反置页表
也是为了减小页表,但是不像多级页表,反置页表占用空间少。
比如,
物理内存大小:
4096*4096=4K*4KB=16 MB页面大小:
4096 bytes = 4KB页帧数:
4096 = 4K页寄存器使用的空间 (假设每个页寄存器占8字节):
8*4096=32 Kbytes页寄存器带来的额外开销:
32K/16M = 0.2%(大约)虚拟内存的大小: 任意
3.5 段页式存储管理
段式存储在内存保护方面有优势,页式存储在内存利用和优化转移到后备存储方面有优势。
-
段页式存储管理
在段式存储管理基础上,给每个段加一级页表,具体访问过程如下:
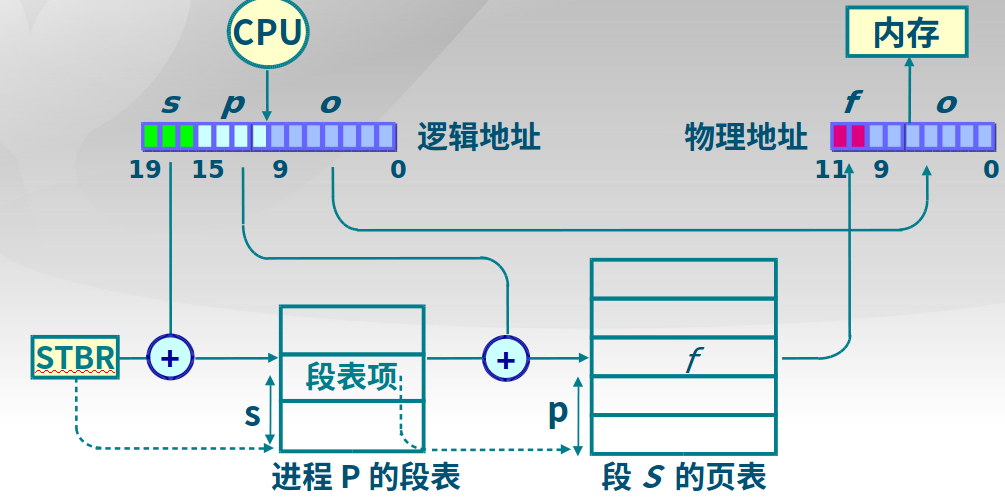
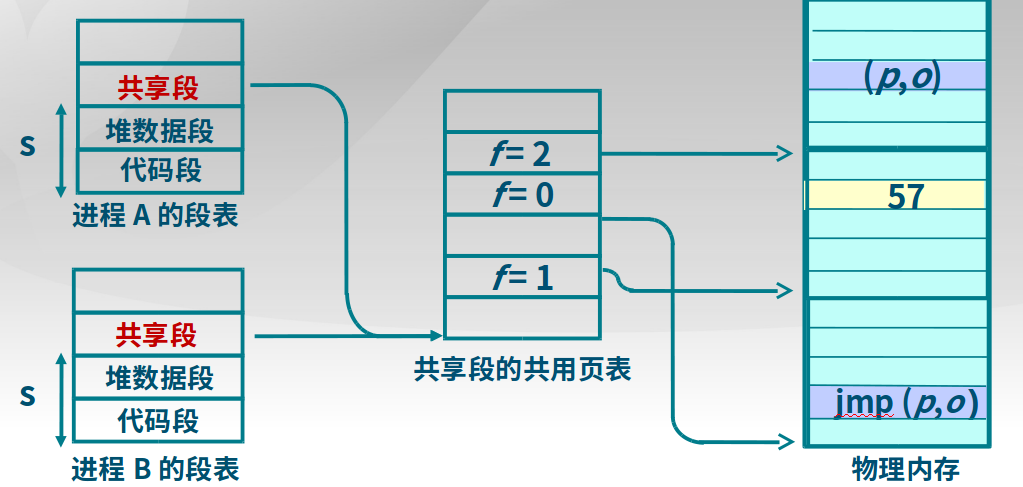
可以将段表指向相同的页表基址,则实现进程间的段分享,如下图:
具体参考实验课程设计的实验二。
3.6 虚拟存储
可以把一部分内存中的内容放到外存,以让正在运行的程序有更多的内存空间可以利用。
3.6.1 覆盖技术和交换技术
-
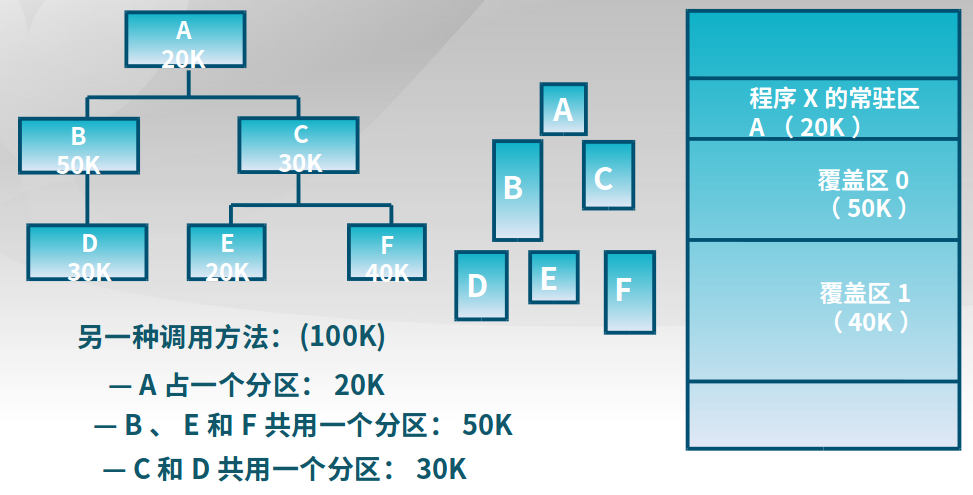
覆盖技术
在较小的可用内存中运行较大的程序(对于一个程序/进程而言)
实现方法:依据程序逻辑结构,将程序划分为若干功能相对独立的模块;将不会同时执行的模块共享同一块内存区域,下面是覆盖技术的使用实例:
-
交换技术
增加正在运行或需要运行的程序的内存(对于多个程序/进程而言)。
实现方法:可将暂时不能运行的程序放到外存。
-
局部性原理(Principle of Locality)
程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限与一定区域
-
时间局限性
一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时期内
-
空间局限性
当前指令和邻近的几条指令,当前访问的数据和邻近的几个数据都集中在一个较小区域内
-
分支局部性
一条跳转指令的两次执行,很可能跳到相同的内存位置。
下面是一个只有1K内存,但是需要访问4K数组的实例,如果按照一行一行搜索出现缺页的次数大约是1024次,而按照一列一列搜索出现的缺页次数大约是
1024*1024次
-
3.6.2 虚拟存储
将不常用的部分内存块暂存到外存
-
虚拟存储原理
装载程序:只将当前指令执行所需要的部分页面或段装入内存
指令执行需要的指令或数据不在内存(称为缺页或缺段):处理器通知操作系统将相应的页面或者段装入内存
操作系统将内存中暂时不用的页面或段保存到外存:置换算法
-
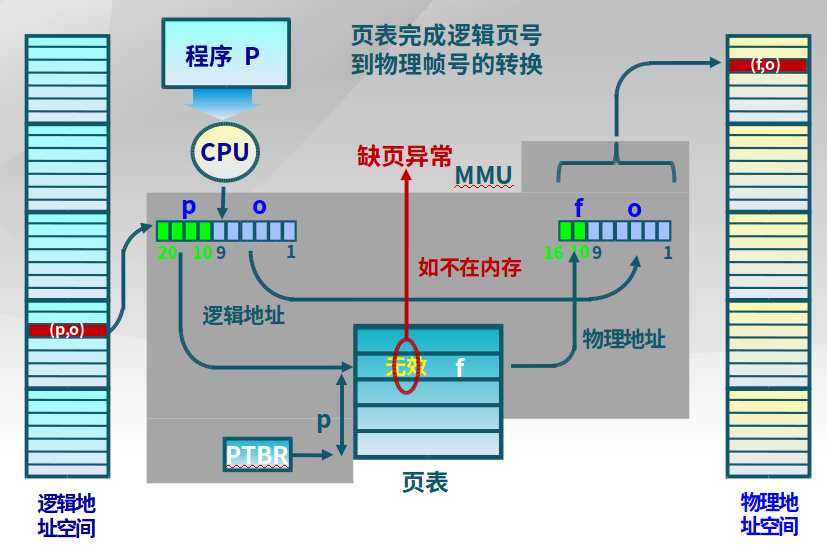
虚拟页式存储管理
在页式存储管理的基础上,增加请求调页和页面置换
- 当用户程序要装载到内存运行时,只装入部分页面,就启动程序运行
- 进程在运行中发现有需要的代码或数据不在内存时,则向系统发出缺页异常请求
- 操作系统在处理缺页异常时,将外存中相应的页面调入内存,使得进程能继续运行
下图是页式存储出现缺页的情况:
要实现虚拟存储,在页表项定义了一些标志位(实际情况标志位更多):
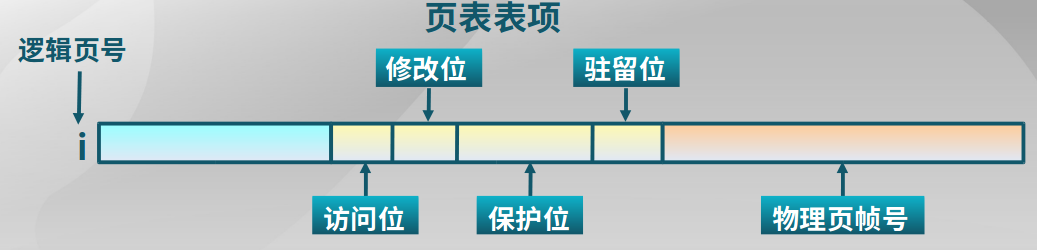
驻留位:该页是否存在于内存,1:存在于内存;0:存在于外存
修改位:在内存中该页是否被修改过,回收该物理页面时,据此判断是否要把它的内容写回外存
访问位:该页面是否被访问过(统计出使用频率),用于页面置换算法
保护位:该页的访问方式,如只读、可读写、可执行等。
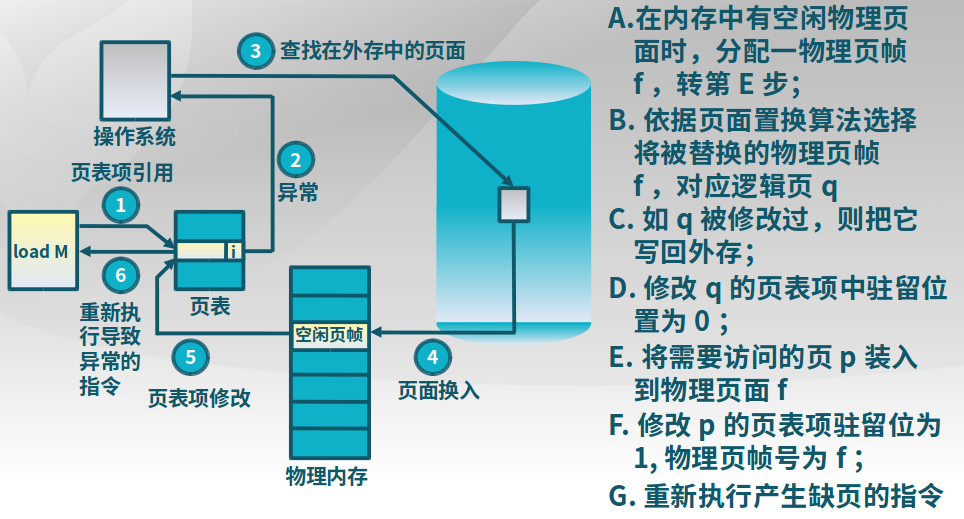
3.6.3 缺页异常
驻留位为0,说明页不在内存中,出现了缺页异常。操作系统需要进行从外存读取该页。
-
虚拟页式存储的外存选择
代码段:本身是不需要修改的可执行二进制文件,只需要指向存储代码段的位置。
动态加载的共享库程序段:本身是不需要修改的,指向动态调用的库文件
其他项:交换空间 Swap
-
有效存储访问时间
EAT = Effective memory Access Time
EAT =访存时间 * (1 - p) + 缺页异常处理时间 * 缺页率p比如访存时间:10ns,磁盘访问时间:5ms,缺页率p,页修改概率q,
EAT = 10ns(1-p) + 5ms * p * (1 + q)
3.6.4 置换算法
当出现缺页异常,需调入新页面而内存已满,置换算法选择被置换的物理页面。
-
设计目标
尽可能减少页面的调入调出次数
把未来不再访问或短期内不再访问的页面调出
-
页面锁定
锁定对象:描述必须常驻内存的逻辑页面;操作系统的关键部分;要求响应速度的代码和数据
措施:页表中的锁定标志位(lock bit),从而不会将页面放到外存
-
局部页面置换算法种类
局部页面置换算法:仅限于当前进程占用的物理页面,具体方法最优置换算法(实际无法使用,可用于其他算法的评价依据)、先进先出、最近最久未使用算法、时钟算法、最不常用算法
全局页面置换算法:所有可能换出的物理页面,具体方法工作集算法、缺页率算法
-
最优置换算法
将未来不使用时间最长的的页面置换,实际无法实现,可用于其他算法的评价依据:
- 在模拟器上运行某个程序,并记录每一次页面访问情况
- 第二次运行时使用最优置换算法
-
先进先出算法
选择在内存驻留时间最长(第一次缺页加入的时间到最近时间)的页面进行置换,可能会造成很多置换,性能缺陷大
-
最近最久未使用算法(Least Recently Used, LRU)
选择最长时间没有被引用的页面进行置换
实现:计算内存中每个逻辑页面的上一次访问时间,选择上一次使用到当前时间最长的页面
缺点:太过复杂,实施不可能
-
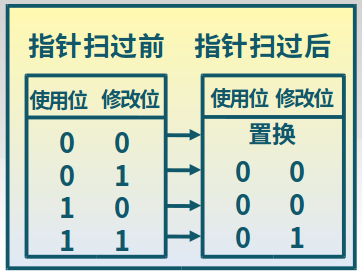
时钟页面置换算法(LRU的简化)
尽对页面的访问情况进行大致统计
实现:
-
页面装入内存时,访问位初始化为0
-
访问页面(读/写)时,访问位置1
-
缺页时,从指针当前位置顺序检查环形链表
访问位为0,则置换该页;访问位为1,则访问位置置0,并指针移动到下一个页面,直到找到可置换的页面。
改进:
在页面中增加修改位,并在访问时进行相应修改(写:将访问位和修改位都设置为1;读将访问位设置为1);缺页时,修改页面标志位,以跳过有修改的页面。
-
-
最不常用算法(Least Frequently Used, LFU)(LRU的简化)
缺页时,置换访问次数最少的页面。
实现:每个页面设置一个访问计数;访问页面时,访问计数加1;缺页时,置换计数最小的页面。
特征:一些早期较多访问的数据不会被置换,可以通过定期将计数器右移来实现计数器的衰减。
-
-
全局页面置换算法种类
进程在不同阶段的内存需求是变化的,全局置换算法为进程分配可变数目的物理页面。
-
评估不同阶段内存需求的方法
本时刻以前delta时间内的页访问情况,比如t1时刻前delta时间段内,访问了
{1,2,3,7},t2时刻前delta时间段内,访问了{1,2},所以前期分配4个页即可,后期分配2个即可。 -
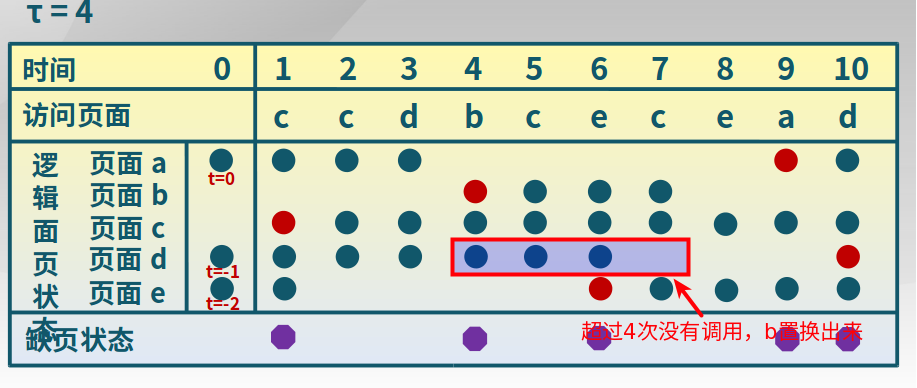
工作集置换算法
置换出不在工作集中的页面。当前时刻前delta个内存访问的页引用是工作集。
实现方法:1. 访存链表,维护窗口内的访存页面链表;2. 访存时,换出不在工作集的页面,更新访存链表;3.缺页时,换出页面,更新访存链表。下面是一个工作集置换算法的举例,以图中方块为例。b页在4次没有使用后,超过了维护窗口,所以需要置换出来。
-
缺页率置换算法
缺页率 = 缺页次数 / 内存访问次数或者是缺页时间间隔的倒数思想
通过调整常驻集,使每个进程的缺页率保持在一个合理的范围内。如果进程缺页率过高,则增加常驻集(取决于分配的物理页面多少和置换算法)以分配更多的物理页面。如果进程缺页率过低,则减少常驻集,分配更少的物理页面,进而提高CPU利用率。
实现
缺页时,计算上次缺页的时间
Tlast到现在Tcurrent的时间间隔,- 如果
Tcurrent - Tlast > T,则置换出来[Tlast,Tcurrent]时间内没有被引用的页 - 如果
Tcurrent - Tlast < T,则增加缺失页到工作集中
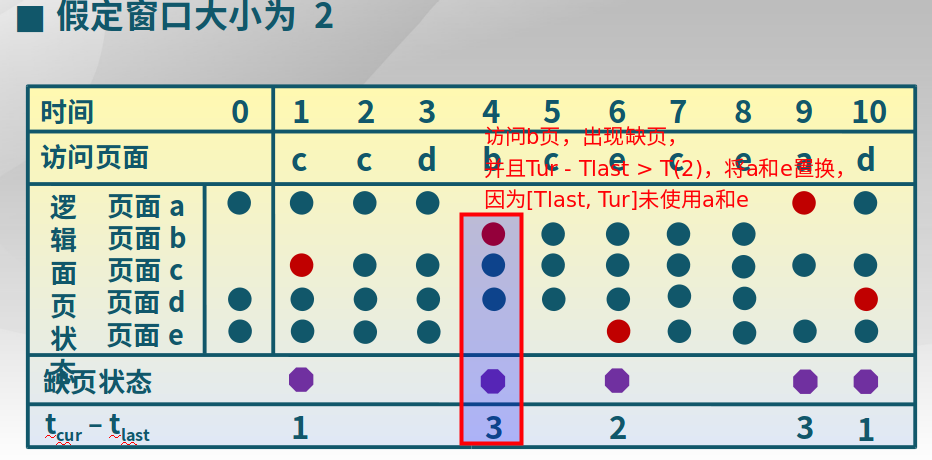
工作集置换算法和缺页率置换算法的区别?工作集置换算法是每次访问页都要执行,开销大;缺页率置换算法是在缺页处理中断时处理。
- 如果
-
-
Belady现象
采用FIFO算法时,可能出现分配的物理页面数增加(也就是原来只给这段程序3个页面,后来给了4个),缺页数(率)反而升高的异常
FIFO算法有Belady现象,LRU没有Belady现象。
时钟和改进的时钟页面置换算法是否有Belady现象?
-
抖动和负载控制
-
抖动(thrashing)
- 进程物理页面太少,不能包含工作集
- 造成大量缺页,频繁置换
- 进程运行速度变慢
-
负载控制
通过调节并发进程数(MPL)来进行系统负载控制
MTBF = 平均缺页间隔时间;PFST = 缺页异常处理时间,
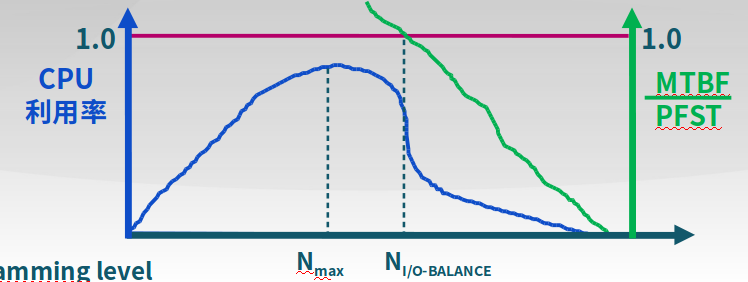
-
4.进程及线程
4.1 进程
4.1.1 进程的概念
程序源代码会在内存中以进程的形式存在,程序是静态的(文件),而进程是动态的,是程序+状态。

4.1.2 进程控制块(PCB, Process Control Block)
进程创建时,生成该进程的PCB;通过对PCB的组织管理来实现进程的管理;进程终止时,回收PCB。
PCB包含的内容
-
进程标识信息
-
处理机现场保存
-
进程控制信息
-
调度和状态信息
进程和处理机使用情况调度
-
进程间通信信息
进程间通信相关的各种标识
-
存储管理信息
指向进程映像存储空间数据结构
-
进程所用资源
进程使用的系统资源,如打开文件等
-
有关数据结构连接信息
与PCB相关的进程队列
-
PCB的组织
-
链表
同一状态的进程PCB连成一个链表,多个状态对应多个不同的链表。
-
索引表
同一状态的进程归入一个索引表
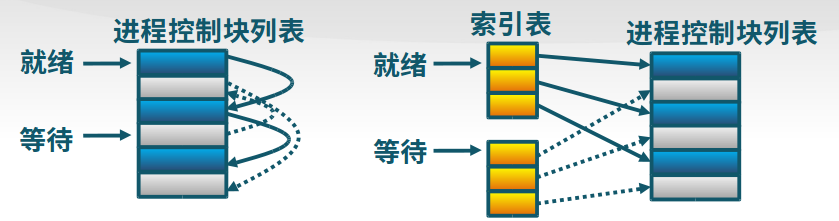
4.1.3 进程状态
-
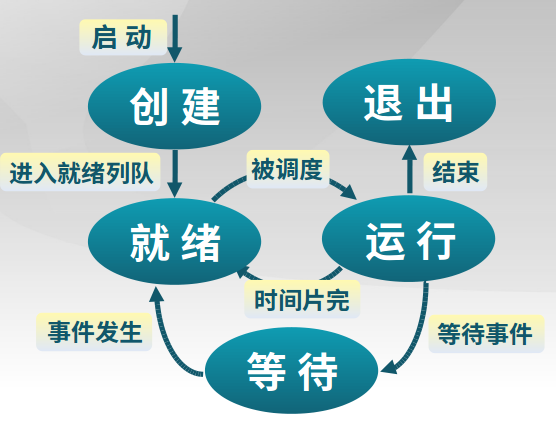
进程生命周期
进程创建、进程执行、进程等待、进程抢占、进程唤醒、进程结束
-
进程创建
-
系统初始化时
- 用户请求创建一个新进程
- 正在运行的进程执行了创建进程的系统调用
-
-
进程等待
- 请求并等待系统服务,无法马上完成
- 启动某个操作,无法马上完成,比如读磁盘
- 需要的数据没有到达
-
进程抢占
- 高优先级进程就绪
- 进程执行当前时间用完
-
进程唤醒(被别的进程或者操作系统)
- 被阻塞进程需要的资源可被满足
- 被阻塞进程等待的事件到达
-
进程结束
- 正常退出(自愿的)
- 错误退出(自愿的)
- 致命错误(强制性的)
- 被其他进程所杀(强制性的)
4.1.4 三状态进程模型
-
运行状态
进程正在处理机上运行
-
就绪状态
进程获得了除处理机之外的所需资源,得到处理机即可运行
-
等待状态(阻塞状态)
进程正在等待某一事件的出现而暂停运行
4.1.5 挂起进程模型
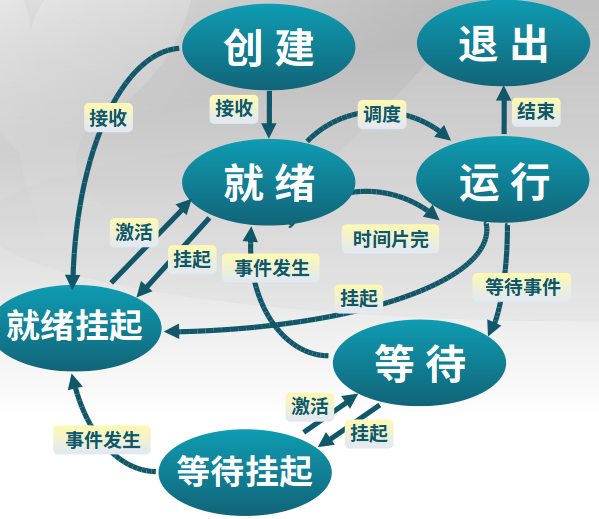
1. 挂起:内存到外存的状态转换
-
等待到等待挂起
没有进程处于就绪状态或者就绪进程需要更多内存空间
-
就绪到就绪挂起
有高优先级进程和低优先级进程处于就绪,为了让高优先级进程有足够的内存空间,所以让低优先级进程挂起。
-
运行到就绪挂起
抢先分时系统,当有高优先级抢先时,低优先级进入挂起,给高优先级足够的内存空间
2. 在外存时的状态转换
-
等待挂起到就绪挂起
等待挂起进程相关事件出现
3. 激活:把一个进程从外存转到内存
-
就绪挂起到就绪
没有就绪进程或者挂起就绪进程优先级高于就绪进程
-
等待挂起到等待
当一个进程释放足够的内存,并有高优先级等待挂起进程
4.2 线程
4.2.1 线程的概念
在进程内部增加一类实体,满足以下特性:
(1)实体之间可以并发执行;
(2)实体之间共享相同的地址空间。
1. 进程和线程之间的关系
- 进程是资源分配的单位,线程是CPU调度的单位,
线程 = 进程 - 共享资源 - 进程拥有一个完整的资源平台,而线程只独享指令流执行的必要资源,如寄存器和栈
- 线程具有就绪、等待和运行三种基本状态和状态间的转换关系
- 线程能减少并发执行的时间和空间开销
- 线程的创建时间比进程短
- 线程的终止时间比进程短
- 同一进程内的线程切换时间比进程切换时间短
- 由于同一进程的各线程间共享内存和文件资源,可不通过内核进行直接通信
-
线程的优点
- 一个进程中可以同时存在多个线程
- 各个线程之间可以并发执行
- 各个线程之间可以共享地址空间和文件等资源
-
线程的缺点
一个线程崩溃,会导致其所属进程的所有进程崩溃
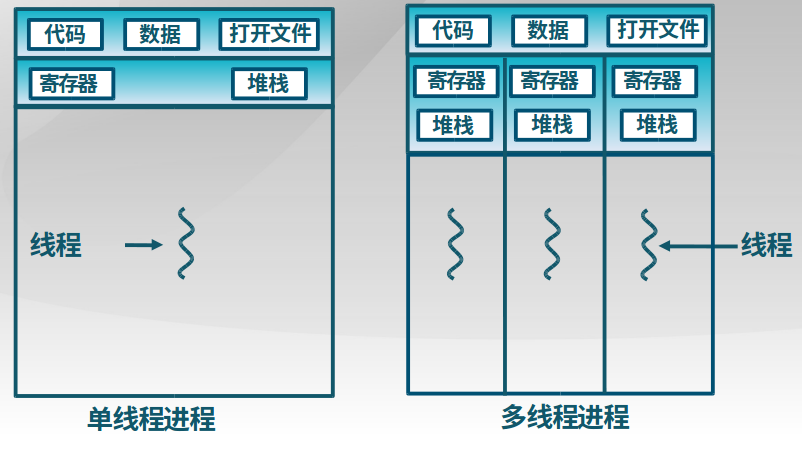
4.2.2 线程的实现
-
线程的三种实现
-
用户线程:在用户空间实现
案例:POSIX Pthreads, Mach C-threads
特征:不依赖于操作系统内核;在用户空间实现线程机制;同一进程内的用户线程切换速度快;允许每个进程拥有自己的线程调度算法。
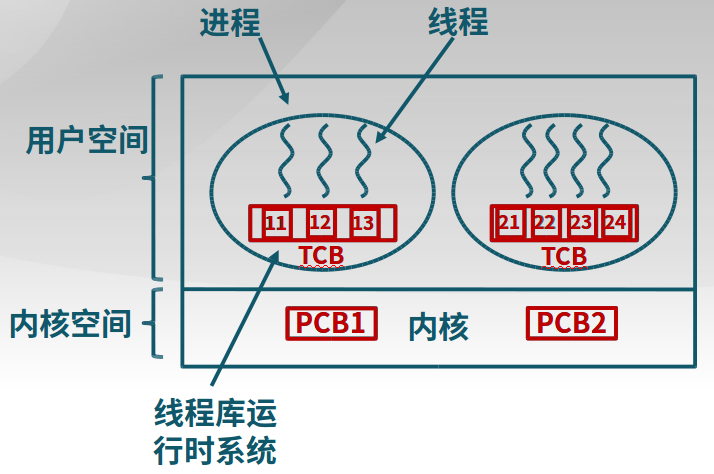
-
内核线程:在内核中实现
案例:Windows, Solaris, Linux
特征:由内核维护PCB和TCB;线程执行系统调用而被阻塞不影响其他线程;线程的创建、终止和切换相对较大(在用户空间实现会更快);以线程为单位进行CPU时间分配。
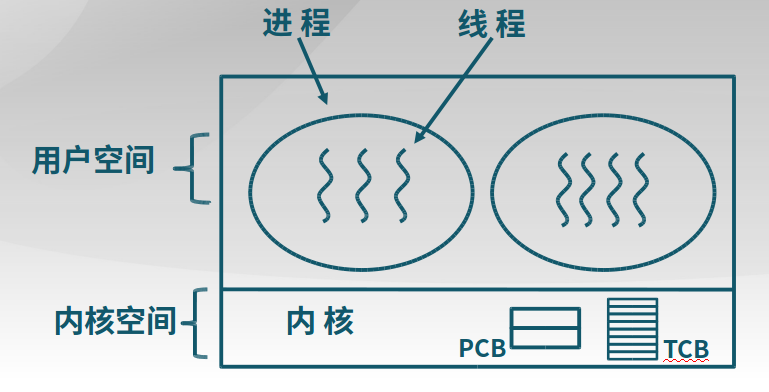
-
轻量级线程:在内核中实现,支持用户线程
Solaris
-
-
用户线程与内核线程的对应关系
1对1的关系较好。
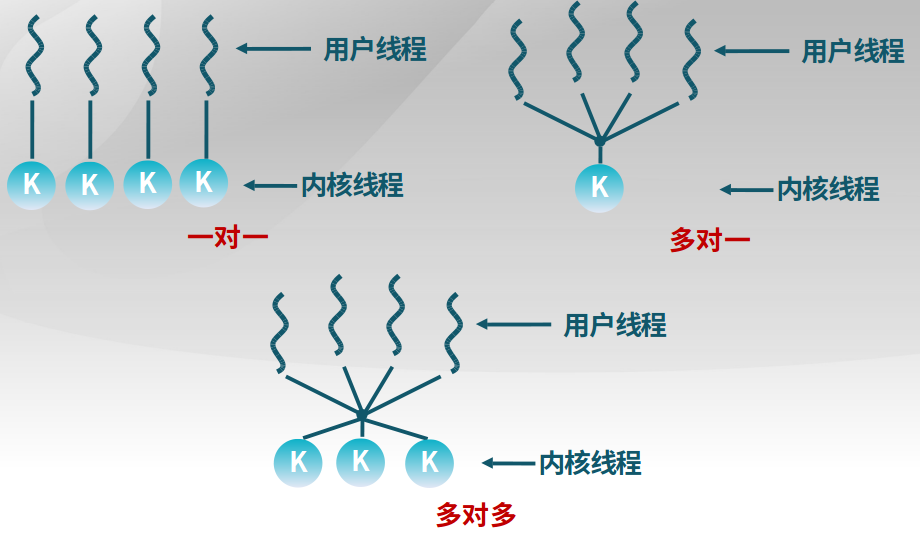
4.3 进程控制
4.3.1 进程切换
-
进程切换
- 暂停当前运行进程,从运行状态变成其他状态
- 调度另一个进程从就绪状态变成运行状态
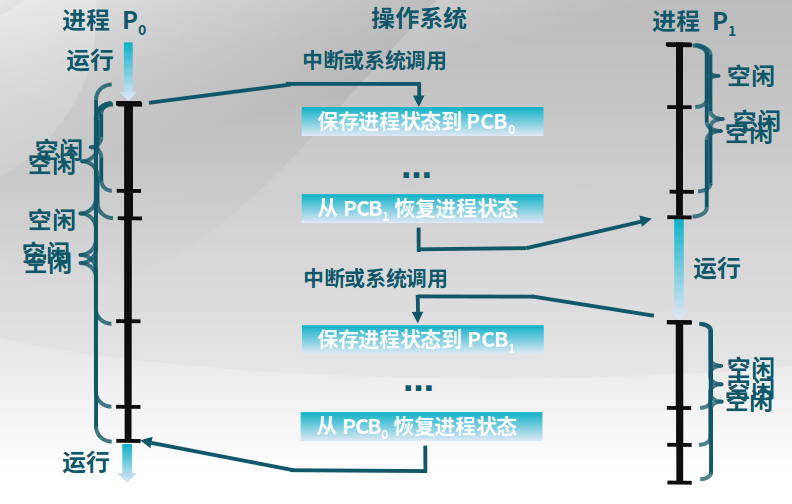
- 进程切换的要求
- 切换前,保存进程上下文
- 切换后,恢复进程上下文
- 快速切换
- 进程 生命周期的信息
- 寄存器(PC、SP、…)
- CPU状态
- 内存地址空间
-
进程控制块PCB:内核的进程状态记录
-
内核为每个进程维护了对应的进程控制块(PCB)
-
内核将相同状态的进程的PCB放置在同一队列
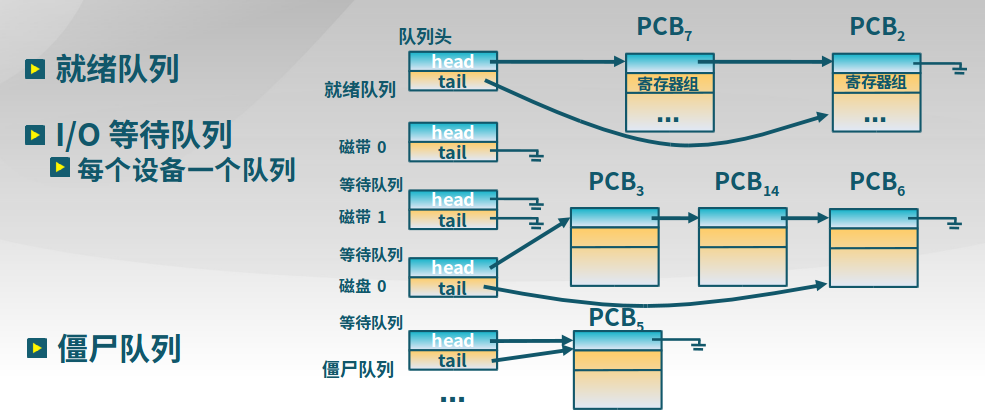
-
4.3.2 进程创建
4.3.2.1 fork和exec介绍
Unix进程创建系统调用:fork/exec
-
fork()把一个进程复制成二个进程parent(old PID),child(new PID)-
复制父进程的所有变量和内存
-
复制父进程的所有CPU寄存器(有一个寄存器例外)
-
返回值
子进程的
fork返回0父进程的
fork返回子进程标识符fork返回值可方便后续使用,子进程可使用getpid()获取PID
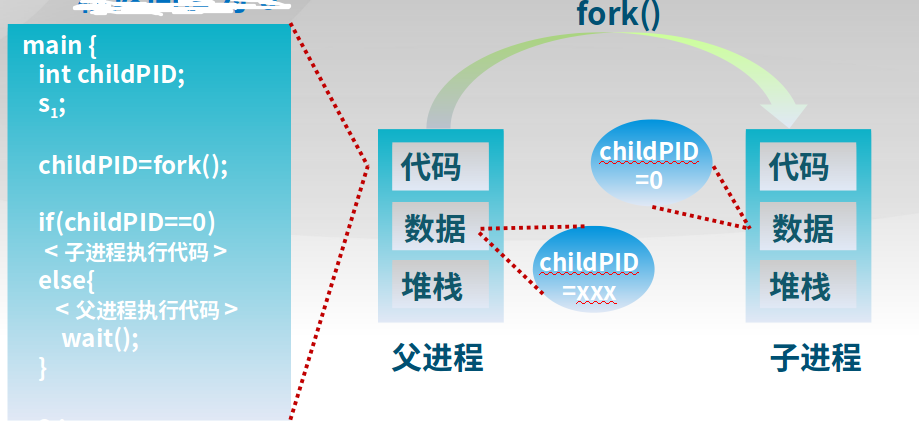
-
-
exec()用新程序来重写当前进程PID没有改变
int childPid = fork(); // 创建子进程 if(childPid == 0) { // 子进程的PID是0 exec("program", argc, argv0, ) }
以下是fork的处理过程:
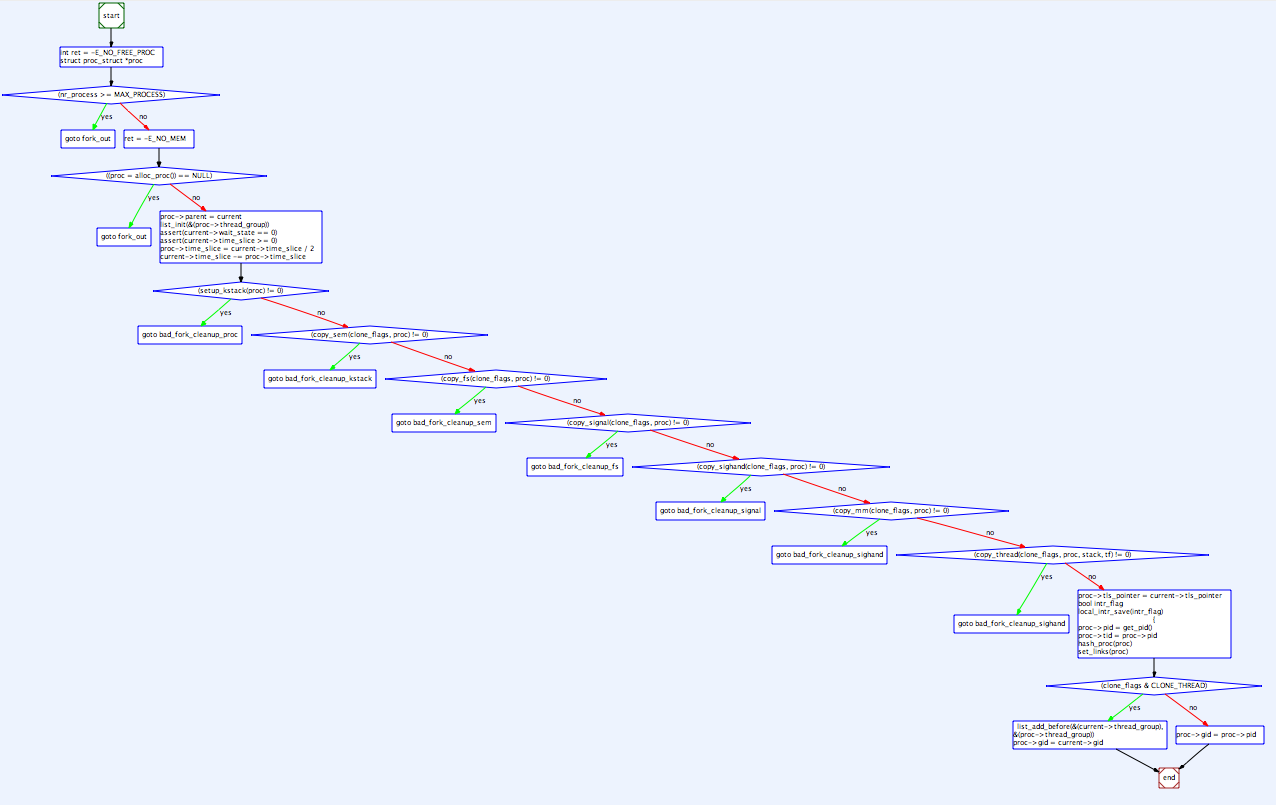
4.3.2.2 创建进程和线程举例
-
空闲进程的创建
/kern-ucore/process/proc.cidelproc proc_init() | 分配idelproc需要的资源 alloc_proc() -> kmalloc() | 初始化idelproc进程控制块 alloc_proc() | 完成idelproc的初始化 proc_init() -
创建第一个内核线程
/kern-ucore/process/proc.cinitproc proc_init() initproc proc_init() | 初始化trapframe kernel thread() (tf设置 -> do_fork()见下方 ) | 初始化initproc alloc_proc() | 初始化内核堆栈 setup_kstack() | 内存拷贝 copy_stack() | 把initproc放到就绪队列 加入到hash表、链表 | 唤醒initproc wakeup_proc()
4.3.2.3 如何减小fork开销
fork需要拷贝父进程,其实这一步后期并没有作用。
在Linux中可以使用vfork():
- 创建进程时,不再创建一个同样的内存映像
- 一些时候称为轻量级fork()
- 子进程应该几乎立即调用exec()
- 现在使用 Copy on Write (COW) 技术
4.3.3 进程加载
ucore的exec()实现
-
sys_exec获取创建进程的参数
-
do_execve -
load_icode解析可执行文件格式
4.3.4 等待和回收
-
父进程等待子进程
wait()系统调用用于父进程等待子进程的结束- 有子进程存活时,父进程进入等待状态,等待子进程的返回结果(当某子进程调用exit()时,唤醒父进程,将exit()返回值作为父进程中wait的返回值)
- 有僵尸子进程(子进程已经
exit,但是还没有被父进程处理)等待时,wait()立即返回其中一个值 - 无子进程存活时,wait()立刻返回
-
进程的有序终止
进程结束执行时调用
exit(),完成进程资源回收- 将调用参数作为进程的“结果“
- 关闭所有打开的文件等占用资源
- 释放内存
- 释放大部分进程相关的内核数据结构
- 检查是否父进程是存活着的(如存活,保留结果的值直到父进程需要它,进入僵尸(zombie/defunct)状态;如果没有,它释放所有的数据结构,进程结果)
- 清理所有等待的僵尸进程
-
其他进程控制系统调用
-
优先级控制
nice()指定进程的初始优先级Unix系统中进程优先级会随执行时间而衰减
-
进程调度等待
ptrace()允许一个进程控制另一个进程的执行设置断点和查看寄存器
-
定时
sleep()让进程在定时器的等待队列中等待指定时间
几个系统调用在状态转化图中的位置(从父进程的角度):
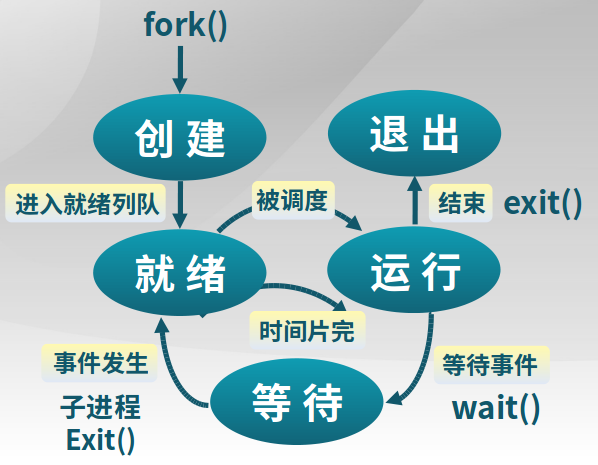
上图中的“时间片用完”箭头错误
-
5.处理机调度
5.1 介绍
两个功能:从就绪队列中挑选下一个占用CPU运行的进程,从多个可用CPU中挑选就绪进程可使用的CPU资源。
调度程序:1. 调度策略:挑选进程/线程的方法;2. 调度时机:挑选进程/线程后,什么时候调度
5.2 调度准则
-
处理机资源的使用模式
进程在CPU计算和IO操作间交替,在IO操作时,CPU处于等待状态。
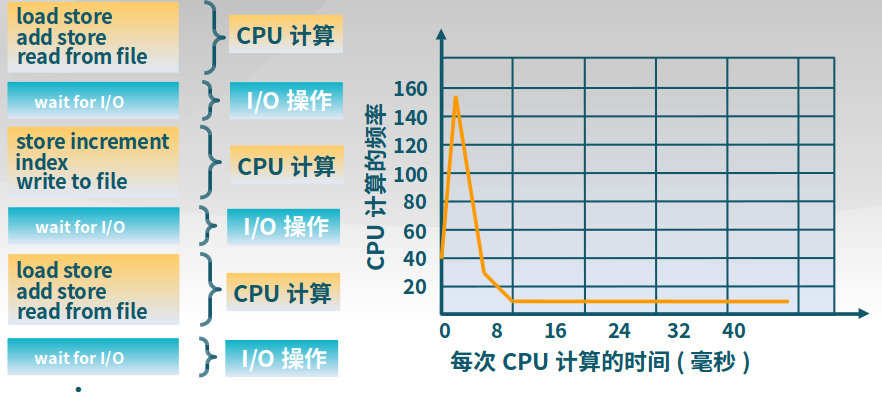
-
比较调度算法的准则
-
CPU使用率
CPU处于忙状态的时间百分比
-
吞吐量
单位时间内完成的进程数量
-
周转时间
进程从初始化到结束(包括等待)的总时间
-
等待时间
进程在就绪队列中的总时间
-
响应时间
从提交任务到执行
-
5.3 调度算法
先来先服务算法(FCFS: First Come, First Served)、短进程优先算法、最高响应比优先算法(HRRN: Highest Response Ratio Next,考虑等待时间)、时间片轮转算法(RR: Round Robin)、多级反馈队列算法(MFQ: Multilevel Feedback Queues,多个队列算法不同)、公平共享调度算法(FSS: Fair Share Scheduling,保证进程占用资源相对公平)
5.3.1 就绪队列排序
-
先来先服务算法
优点:简单
缺点:平均等待时间波动较大;I/O资源和CPU资源的利用率较低(CPU密集型进程会导致I/O设备闲置时,I/O密集型进程也等待)
-
短进程优先算法(SPN)
选择就绪队列中执行时间最短占用CPU进入运行状态
优点:具有最短平均周转时间
缺点:导致饥饿,长进程无法获得CPU资源;需要预知时间(使用历史的执行时间来预估)
-
最高响应比优先算法(HRRN)
R = (w+s)/s,其中w是等待时间,s是执行时间,改进短进程优先算法,防止出现饥饿
5.3.2 时间片轮转算法
时间片结束时,按FCFS算法切换到下一个就绪进程
5.3.3 多级队列调度算法(MQ)
就绪队列被划分成多个独立的子队列,比如前台(注意响应)、后台
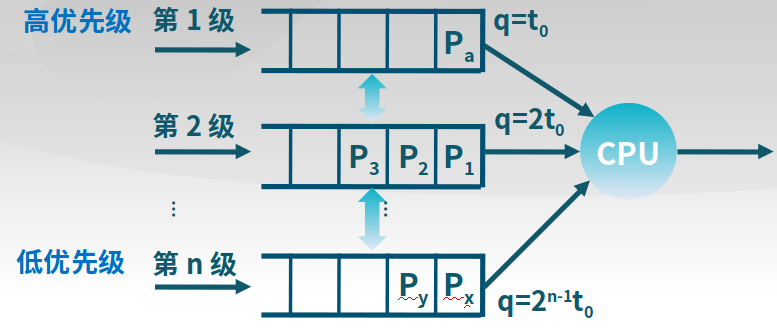
多级反馈队列算法(MLFQ)
- 时间片大小随优先级级别增加而增加
- 如进程在当前的时间片没有完成,则降到下一个优先级
- CPU密集型进程的优先级下降很快,I/O密集型进程停留在高优先级
5.4 ucore的调度时机和进程切换
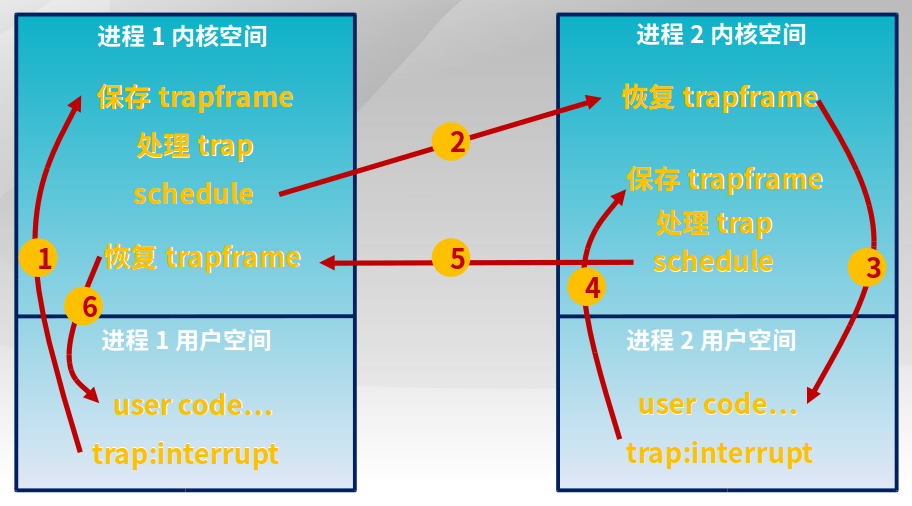
5.5 实时调度与多处理机调度
5.5.1 实时调度分类
-
硬实时
如果不能按时完成任务,会造成灾难性后果
-
软实时
尽量满足实时要求,如果无法满足,则降级完成任务
5.5.2 可调度性
可调度性表示一个操作系统能够满足任务时限要求
- 需要确定实时任务的执行顺序
- 静态优先级调度
- 动态优先级调度
-
速率单调调度算法(RM, Rate Monotonic)
通过周期安排优先级
周期越短优先级越高
执行周期最短的任务
-
最早截止时间优先算法(EDF, Earliest Deadline )
截止时间越早优先级越高
执行截止时间最早的任务
5.5.3 多处理机调度
5.5.3.1 进程分配
-
静态进程分配
进程从开始到结束都被分配到一个固定的处理机上执行
每个处理机有自己的就绪队列
调度开销小
各处理机可能负载不均
-
动态进程分配
进程在执行过程中可分配到任意空闲处理机执行
所有处理机共享一个公共的就绪队列
调度开销大
各处理机负载均衡
5.5.4 优先级反置
进程1占用了资源L1,进程2也要使用资源L1,则会等待进程1释放资源。但是进程1被其他进程打断,一直无法释放资源L1,造成了进程2一直无法使用资源L1。
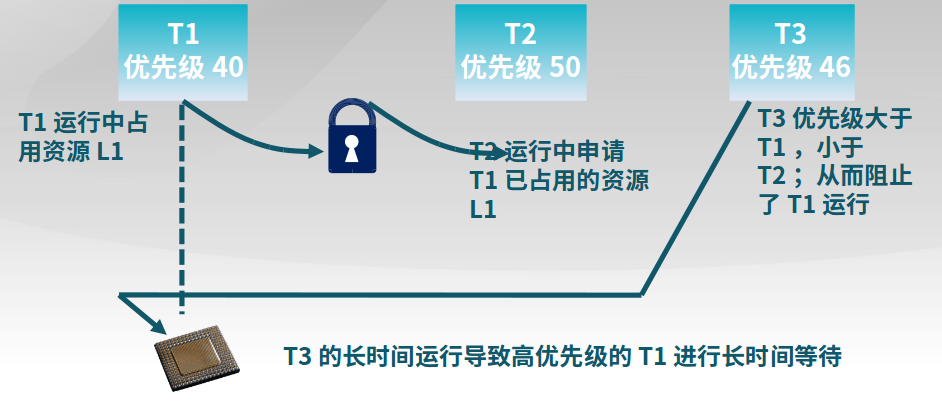
为了解决该问题,需要将进程1的优先级提高:
-
优先级继承
占用资源的低优先级进程继承申请资源的高优先级进程的优先级
-
优先级天花板协议
占用资源进程的优先级和所有可能申请该资源的进程的最高优先级相同
6.同步互斥
6.1 概念
-
并发进程的正确性
-
独立进程
不和其他进程共享资源或者状态
确定性:输入状态决定结果
可重现:能够重现起始条件
调度顺序不重要
-
并发进程
多个进程间有资源共享
不确定性
不可重现
-
-
原子操作
原子操作是值一次不存在在任何中断或者失败的操作
操作系统需要利用同步机制在并发执行的同时,保证一些操作是原子操作
-
互斥
一个进程占用资源,其它进程不能使用
-
死锁
多个进程各占用部分资源,形成循环等待
-
饥饿
其他进程可能轮流占用资源,一个进程一直得不到资源
6.2 临界区实现方法
-
禁用硬件中断
适用于单处理机
没有中断,没有上下文切换,因此没有并发
-
基于软件的同步方法
// Peterson算法 do { // 准备进入临界区 flag[i] = true; // 处于临界区,如果其他进程打断并重新设置turn,则本进程在下面的while中等待 turn = j; // 如果上面两步有一步 while ( flag[j] && turn == j); CRITICAL SECTION // 临界区代码 flag[i] = false; REMAINDER SECTION } while (true);//Dekkers算法 flag[0]:= false; flag[1]:= false; turn:= 0;//or1 do { flag[i] = true; while flag[j] == true { if turn ≠ i { flag[i] := false while turn ≠ i { } flag[i] := true } } CRITICAL SECTION turn := j flag[i] = false; EMAINDER SECTION } while (true); -
高级抽象方法
-
锁
一个二进制变量(锁定/解锁)
获取锁(Acquire)、释放锁(Release)
-
原子操作指令
使用于共享资源的多处理机
- 测试和置位(Test-and-Set)指令
-
从内存单元中读取值
-
测试该值是否为1(然后返回真或者假)
-
内存单元值设置为1
// 如果表达为C语言则是如下 boolean TestAndSet (boolean *target) { boolean rv = *target; *target = true; return rv: }-
交换指令
交换内存中的两个值
-
自旋锁Spinlock
可以使用TS(测试和置位)指令实现
class Lock { int value = 0; } Lock::Acquire() { // 1. value原值为0,则返回0,设置为1 // 2. 原值为1,则返回1,设置为1(相当于没有改动),此时说明有其他进程占用了该锁,本进程一直while等待 while (test-and-set(value)) ; //spin } Lock::Release() { value = 0; } -
无忙等待锁
class Lock { int value = 0; WaitQueue q; } Lock::Acquire() { while (test-and-set(value)) { 将本TCB加入到等待队列 schedule(); } } Lock::Release() { value = 0; 将1个进程从等待队列移除 wakeup(t); }
-
6.3 信号量
基本的同步方法:建立临界区(禁用中断、原子操作、软件同步方法)。而信号量是操作系统提供的一种协调共享资源访问的方法。
信号量和软件同步方法的区别是:1. 软件同步方法是一种进程间平等共享资源的方法;2. 信号量是OS作为提供者的资源共享方法
信号量主要包括1个整型和2个原子操作(P和V)。初始化完成后,整型sem只能通过P(减小,占用资源,可能被阻塞)和V(增加,也就是释放资源,不会阻塞)操作来修改,PV都是原子操作。而OS保证了不会受到用户进程的打断和干扰,所以可以实现原子操作PV。
class signal {
int sem;
P(); // 原子操作:减小
V(); // 原子操作:增加
}
- 信号量假定是公平的
- 线程不会被无限期阻塞在P操作
- 假定信号量等待按先进先出排队
-
数据结构
// 等待队列 classSemaphore { int sem; WaitQueue q; } // 请求资源,如果sem<0,说明资源被占用,则将该进程加入到等待队列 Semaphore::P() { sem--; if (sem < 0) { Add this thread t to q; block(p); } } // 释放资源,如果sem<=0,说明有其他进程在等待资源,所以将队列第一个进程移除执行 Semaphore::V() { sem++; if (sem<=0) { Remove a thread t from q; wakeup(t); } }为什么此时P和V操作不会被打断呢?因为操作系统作为保护,不会被打断。
-
信号量实现条件同步
条件同步设置1个信号量,初值设置为0(1才表示有资源)
condition = new Semaphore(0)我们要实现线程B的X代码先于线程A的N代码执行,则
线程A 线程B ... M ... ... X ... condition->P() condition->V() ... N ... ... Y ...- 如果A先到达
condition->P(),则会由于没有资源而等待;直到线程B调用condition->V()释放资源(也就是表示完成了X代码部分) ;而后执行N代码 - 如果B先到达
condition->V(),则释放资源(表示已经完成X代码),此时A正常执行资源申请condition->P()和N代码
- 如果A先到达
-
生产者-消费者问题
-
问题描述
- 一个或多个生产者在生成数据后放在一个缓冲区里
- 单个消费者从缓冲区取出数据处理
- 任何时刻只能有一个生产者或消费者可访问缓冲区
-
问题分析
- 任何时刻只能有一个线程操作缓冲区(互斥访问)
- 缓冲区空时,消费者必须等待生产者(条件同步)
- 缓冲区满时,生产者必须等待消费者(条件同步)
-
信号量设计
- 二进制信号量mutex,用于实现任意时刻只有一个线程操作缓冲区
- 资源信号量fullBuffers,用于实现缓冲区空时,消费者等待生产者
- 资源信号量emptyBuffers,用于实现缓冲区满时,生产者必须等待消费者
class BoundedBuffer { // 二进制信号量,用于实现任意时刻只有一个线程操作缓冲区 mutex = new Semaphore(1); // 资源信号量fullBuffers,用于实现缓冲区空时,消费者等待生产者 fullBuffers = new Semaphore(0); // 资源信号量emptyBuffers,用于实现缓冲区满时,生产者必须等待消费者 emptyBuffers = new Semaphore(n); } // 消费者写入数据 BoundedBuffer::Deposit(c) { // 请求资源信号量emptyBuffers,如果没有未使用的空间,则等待缓冲区的空间释放 emptyBuffers->P(); // 请求二进制信号量,如果是被其他进程占用则等待缓冲区释放 mutex->P(); Add c to the buffer; // 释放缓冲区 mutex->V(); // 缓冲区空间被使用的个数增加1 fullBuffers->V(); } BoundedBuffer::Remove(c) { fullBuffers->P(); mutex->P(); Remove c from buffer; mutex->V(); emptyBuffers->V(); }
-
6.4 管程
管程是一种用于多线程互斥访问共享资源的程序结构,在管程中的线程可临时放弃管程的互斥访问,等待事件出现时恢复。一个管程主要包括:1个锁(控制管程代码的互斥访问)、0或者多个条件变量(管理共享数据的并发访问)
-
条件变量
- 条件变量是管程内的等待机制
- 进入管程的线程因资源被占用而进入等待状态
- 每个条件变量表示一种等待原因,对应一个等待队列
- Wait操作
- 将自己阻塞在等待队列中
- 唤醒一个等待者或释放管程的互斥访问
- Signal操作
- 将等待队列中的一个线程唤醒
- 如果等待队列为空,则等同空操作
// 条件变量 Class Condition { int numWaiting = 0; WaitQueue q; } // 等待,将线程加入到该条件变量的等待队列 Condition::Wait(lock){ numWaiting++; Add this thread t to q; release(lock); // 释放锁 schedule(); //need mutex require(lock); } // 信号,唤醒一个等待队列中的线程 Condition::Signal(){ if (numWaiting > 0) { Remove a thread t from q; wakeup(t); //need mutex numWaiting--; } } - 条件变量是管程内的等待机制
-
解决生产者-消费者问题
classBoundedBuffer { … Lock lock; int count = 0; Condition notFull, notEmpty; } // 生产者 BoundedBuffer::Deposit(c) { // 锁 lock->Acquire(); while (count == n) notFull.Wait(&lock); // wait中会释放锁,然后调度其他进程,调度完后再锁住,具体见wait Add c to the buffer; // buffer中的数据量 count++; // 唤醒等待队列中的线程来使用资源 notEmpty.Signal(); lock->Release(); } BoundedBuffer::Remove(c) { lock->Acquire(); while (count == 0) notEmpty.Wait(&lock); Remove c from buffer; count--; notFull.Signal(); lock->Release(); }
6.5 死锁
出现死锁的必要条件:
-
互斥
任何时刻只能有一个进程使用一个资源实例
-
持有并等待
进程保持至少一个资源,并正在等待获取其他进程持有的资源
-
,
资源只能在进程使用后自愿放弃
-
循环等待
存在等待进程集合
6.6 进程间通信
-
信号
进程间的软件中断通知和处理机制,比如SIGKILL、SIGSTOP、SIGCONT
传送信息量少,只有一个信号类型
-
管道
进程间基于内存文件的通信机制
-
读管道:
read(fd, buffer, nbytes)scanf()是基于它实现的 -
写管道:
write(fd, buffer, nbytes)printf()是基于它实现 -
创建管道:
pipe(rgfd)rgfd是2个文件描述符组成的数组rgfd[0]是读文件描述符rgfd[1]是写文件描述符
管道实例:
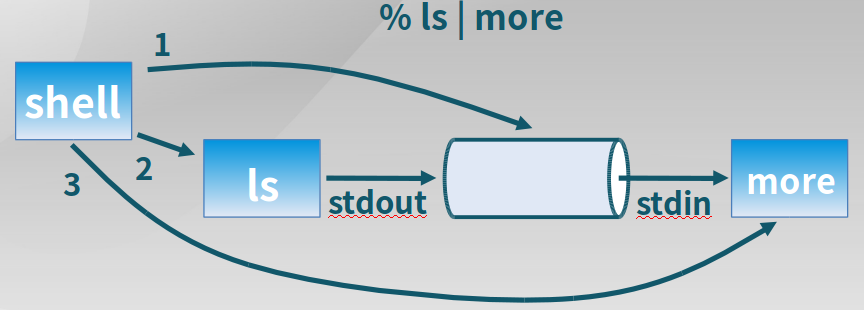
-
-
消息队列
消息队列是由操作系统维护的以字节序列为基本单位的间接通信机制,每个消息(Message)是一个字节序列,相同标识的消息组成按先进先出顺序组成一个消息队列(Message Queues)
-
msgget ( key, flags)获取消息队列标识
-
msgsnd ( QID, buf, size, flags )发送消息
-
msgrcv ( QID, buf, size, type, flags )接收消息
-
msgctl( … )消息队列控制
-
-
共享内存
共享内存是把同一个物理内存区域同时映射到多个进程的内存地址空间的通信机制
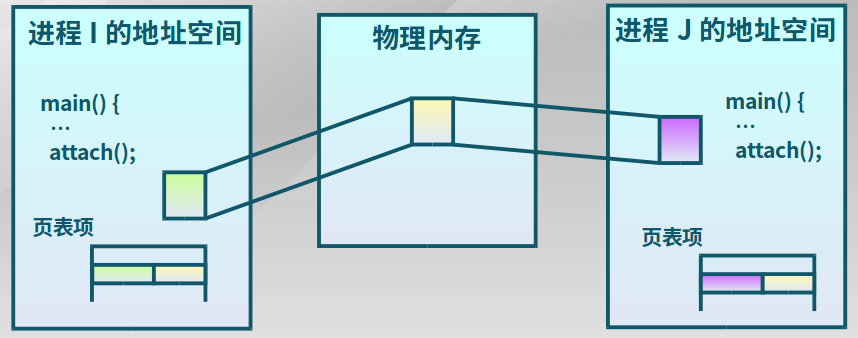
-
shmget( key, size, flags)创建共享段
-
shmat( shmid, *shmaddr, flags)把共享段映射到进程地址空间
-
shmdt( *shmaddr)取消共享段到进程地址空间的映射
-
shmctl( …)共享段控制
-
需要信号量等机制协调共享内存的访问冲突
-
7.文件系统
7.1 文件系统
文件系统是操作系统中管理持久性数据的子系统,提供数据存储和访问功能。
- 文件系统的管理
- 分配文件磁盘空间
- 管理文件块(位置和顺序)
- 管理空闲空间(位置)
- 分配算法 (策略)
- 管理文件集合
- 定位:文件及其内容
- 命名:通过名字找到文件
- 文件系统结构:文件组织格式
- 数据可靠性
- 分配文件磁盘空间
7.2 文件描述符
文件打开后在内存中的信息。内核跟踪进程打开的所有文件,操作系统为每个进程维护一个打开文件表,文件描述符是打开文件的标识。
f = open(name, flag);
…
read(f, …);
…
close(f);
-
文件描述符
-
文件指针
最近一次读写位置
每个进程分别维护自己的打开文件指针
-
文件打开计数
当前打开文件的次数
最后一个进程关闭文件时,将其从打开文件表中移除
-
文件磁盘的位置
缓存数据访问信息
-
访问权限
每个进程的文件访问模式信息
-
-
文件的用户视图和系统视图
-
用户视图
持久的数据结构
-
系统视图
数据块的集合
数据块是逻辑存储单元,扇区是物理存储单元
块大小和扇区大小无关
-
-
用户视图到系统视图的转换
- 进程读文件
- 获取字节所在的数据块
- 返回数据块内对应部分
- 进程写文件
- 获取数据块
- 修改数据块中对应部分
- 写回数据块
- 进程读文件
-
文件共享和访问控制
文件访问控制列表(ACL):
<文件实体, 权限>Unix模式下的形式:
<用户|组|所有人, 读|写|可执行>
7.3 虚拟文件系统
-
文件系统数据结构
-
卷控制块(每个文件系统一个)
当文件系统挂载时进入内存
-
目录节点(每个目录一个)
当遍历一个文件路径时进入内存
-
文件控制块(每个文件一个)
当文件被访问时进入
-
8.IO子系统
8.1 IO特点
-
常用设备接口类型
-
字符设备
以字节为单位顺序访问
举例:键盘、鼠标、串口
-
块设备
均匀的数据块访问
举例:磁盘驱动器、磁带驱动器、光驱等
-
网络设备
格式化报文交换
举例:以太网、无线、蓝牙
-
-
IO操作方法
-
阻塞IO
读数据(read)时,进程将进入等待状态,直到完成数据读出
写数据(write)时,进程将进入等待状态,直到设备完成数据写入处理
-
非阻塞IO
立即从read或write系统调用返回,返回值为成功传输字节数
read或write的传输字节数可能为不是需要传输的字节数
-
异步IO
读数据时,使用指针标记好用户缓冲区,立即返回;稍后内核将填充缓冲区并通知用户
写数据时,使用指针标记好用户缓冲区,立即返回;稍后内核将处理数据并通知用户
-
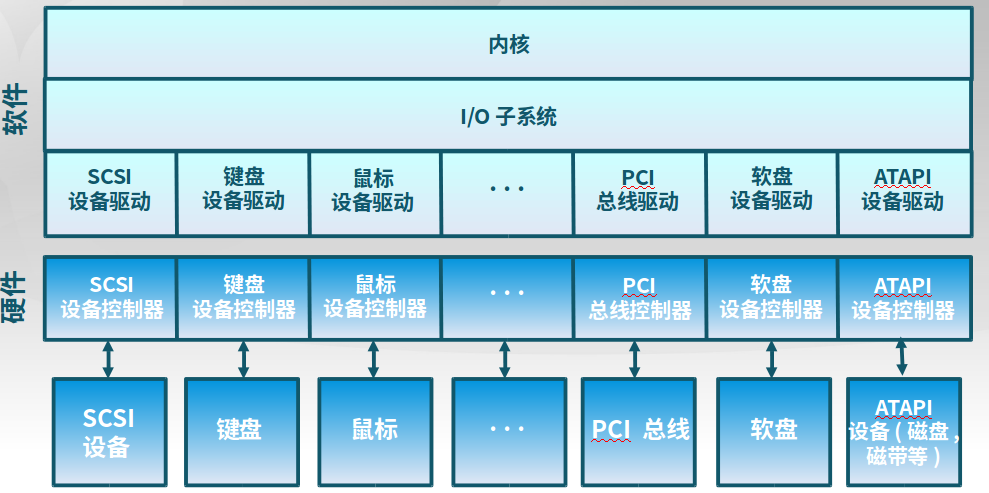
8.2 内核IO结构
下图是一个内核的IO结构。
下图是一个IO请求生命周期,
8.3 CPU和设备控制器的数据传输
-
程序控制IO
通过CPU的
in/out或者load/store来传输所有数据特点:硬件简单,编程容易;CPU消耗和数据量成正比
-
直接内存访问(DMA)
设备控制器可直接访问系统总线;控制器直接与内存互相传输数据
特点:设备传输数据不影响CPU;需要CPU参与设置
9.实验课程设计
9.1 操作系统实验环境准备
9.1.1 课程设计内容

9.1.2 X86-32硬件介绍
X86-32指的是80386这种机器,是intel的32位机器,有四种运行模式:实模式、保护模式、SMM模式和虚拟8086模式。
-
实模式
80386加电启动后处于实模式,访问物理内存空间不能超过1MB(20位)
-
保护模式
支持内存分页机制,还支持优先级机制,有4GB寻址空间(32位)。
9.1.3 X86-32硬件内存架构
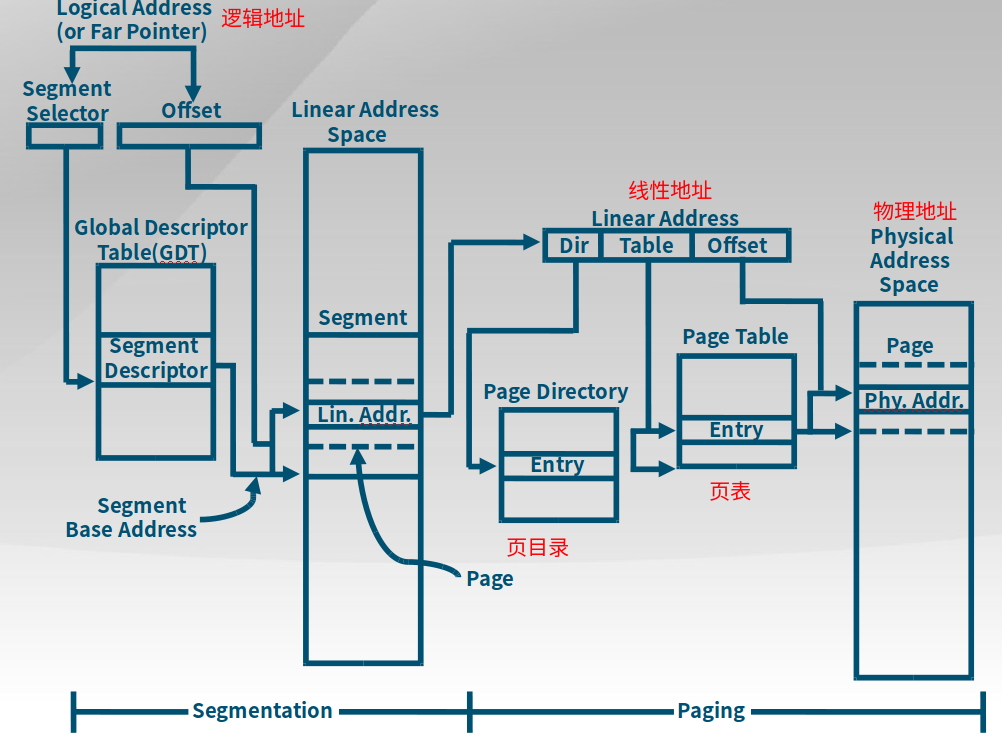
段机制启动、页机制未启动:逻辑地址 -> 段机制处理 -> 线性地址 = 物理地址
段机制和页机制都启动 :逻辑地址 -> 段机制处理 -> 线性地址 -> 页机制处理 -> 物理地址
物理地址:处理器提交到总线上用于访问计算机系统中的内存和外设的最终地址。
线性地址:在操作系统的虚存管理之下每个运行的应用程序能访问的地址空间。每个运行的应用程序都认为自己独享整个计算机系统地址空间,这样可以让多个运行的应用程序之间相互隔离。
逻辑地址:应用程序直接使用的地址空间。
段机制、页机制:地址映射关系
9.2 实验一 bootloader启动ucore os
9.2.1 X86启动顺序
启动和CS和EIP寄存器相关。
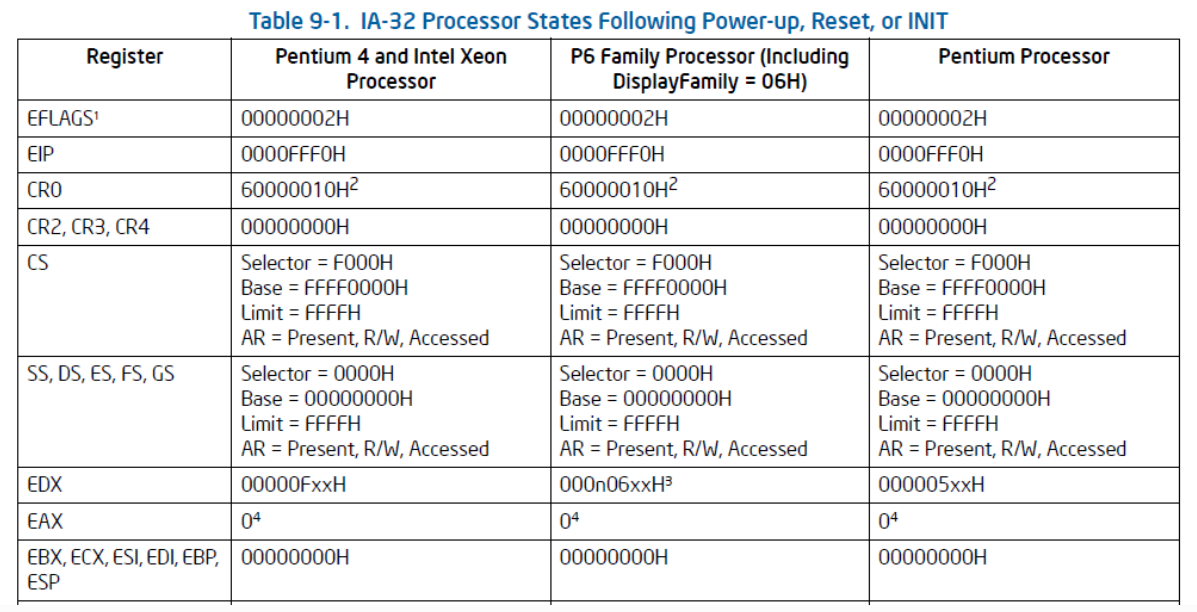
-
1.第一条指令
Base + EIP = FFFF0000H + 0000FFF0H = FFFFFFF0H这是BIOS的EPROM (Erasable Programmable Read Only Memory) 所在地,通常第一条指令是长跳转指令(CS和EIP都会更新),跳转到BIOS代码中。
-
2.BIOS
BIOS进行一些系统设置、自检程序和系统自启动程序,然后加载存储设备的第一个扇区(主引导扇区 MBR)的512个字节(Bootloader)到内存的0x7c00,CS:IP跳转到0x7c00的第一条指令开始执行。
-
3.Bootloader
- 使能保护模式(protection mode) & 段机制(segment-level protection),见下方段机制
- 从硬盘上读取kernel in ELF 格式的ucore kernel(跟在MBR后面的扇区)并放到内存中固定位置,见下方加载ELF格式的ucore kernel说明
- 跳转到ucore OS的入口点(Entry Point)执行,控制权交给ucore
段机制
只有在保护模式下才能使用分段存储管理机制。分段机制将内存划分成以起始地址和长度限制这两个二维参数表示的内存块,这些内存块就称之为段(Segment)。编译器把源程序编译成执行程序时用到的代码段、数据段、堆和栈等概念在这里可以与段联系起来,二者在含义上是一致的。
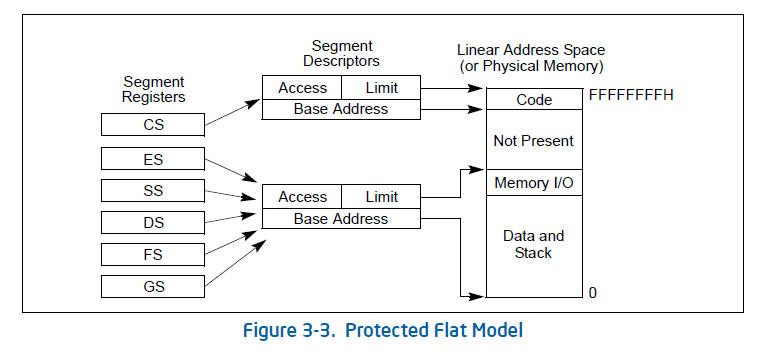
段寄存器(如CS)指向段描述符,段描述符中包含了起始地址和大小。
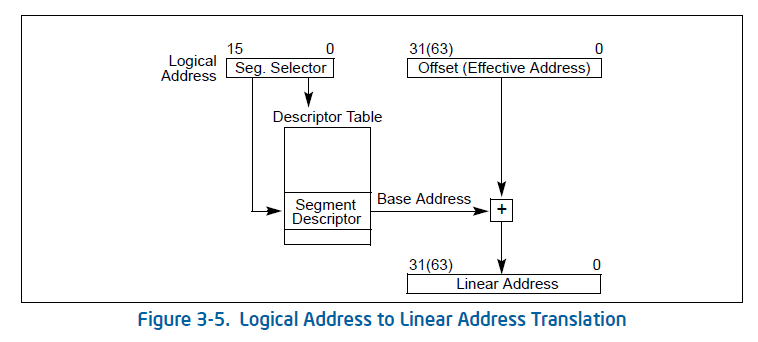
在一个段寄存器Segment Register里面,会保存一块区域叫做段选择子Segment Selector。段选择子中包含Index,用于索引段描述符表Descriptor Table中的某一个段描述符,其中段描述符表地址、大小等信息由全局描述符表确定(具体见下方)。Offset(偏移量)是EIP,而段描述符中存放了起始地址Base Addr。Base Addr是由CS或者是其他段寄存器所指出来的基址。Base Addr + Offset得到线性地址,如果没有启动页机制,则线性地址就是物理地址。
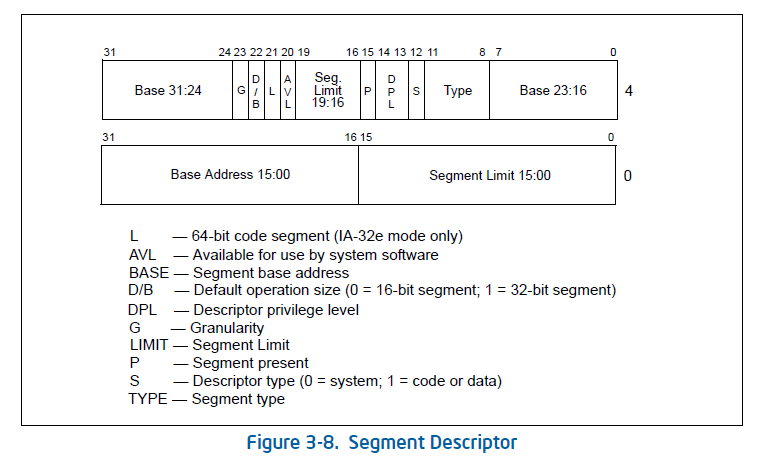
以上是段描述符细节。
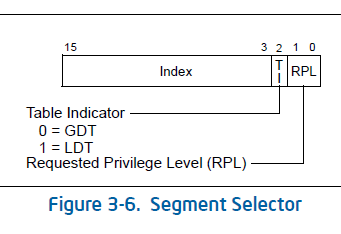
以上是段寄存器中的段选择子的内部细节,包括全局描述符表(以GDT全局描述表为例,LDT意思是本地描述表)的地址、优先级(RPL),一般内核优先级为0(最高)、用户态的优先级为3。全局描述符表GDT中包含段描述符表(包含了所有的段描述符)地址,通过加载GDT来找到段描述符的起始地址(通过系统表寄存器System Table Register来实现CS、DS等段寄存器和段描述符的对应关系,存放在GDTR,见下方)。
GDT(Global Descriptor Table)和LDT(Local Descriptor Table),每一张段表可以包含
8192 (2^13)个描述符因而最多可以同时存在2 * 2^13 = 2^14个段。虽然保护模式下可以有这么多段,逻辑地址空间看起来很大,但实际上段并不能扩展物理地址空间,很大程度上各个段的地址空间是相互重叠的。目前所谓的64TB(2^(14+32)=2^46)逻辑地址空间是一个理论值,没有实际意义。在32位保护模式下,真正的物理空间仍然只有2^32字节那么大。注:在ucore lab中只用到了GDT,没有用LDT。

为什么需要分段机制?
虽然EIP可以寻址空间有32位,但是为了安全起见,需要引入分段机制,通过段描述符(64位)的段物理首地址、段界限、段属性等描述来限制段的空间大小。
段描述符
在分段存储管理机制的保护模式下,每个段由如下三个参数进行定义:段基地址(Base Address)、段界限(Limit)和段属性(Attributes)。在ucore中的kern/mm/mmu.h中的structsegdesc数据结构中有具体的定义。
(1)段基地址
规定线性地址空间中段的起始地址。在80386保护模式下,段基地址长32位。
(2)段界限
规定段的大小。在80386保护模式下,段界限用20位表示,而且段界限可以是以字节为单位或以4K字节为单位。
(3)段属性
确定段的各种性质。
全局描述符表
全局描述符表的是一个保存多个段描述符的“数组”,其起始地址保存在全局描述符表寄存器GDTR中。GDTR长48位,其中高32位为基地址,低16位为段界限。
选择子
线性地址部分的选择子是用来选择哪个描述符表和在该表中索引一个描述符的。
索引(Index):在描述符表中从8192个描述符中选择一个描述符。处理器自动将这个索引值乘以8(描述符的长度),再加上描述符表的基址(存放在GDTR)来索引描述符表,从而选出一个合适的描述符。
表指示位(Table Indicator,TI):选择应该访问哪一个描述符表。0代表应该访问全局描述符表(GDT),1代表应该访问局部描述符表(LDT)。
请求特权级(Requested Privilege Level,RPL):保护机制,说明如下:
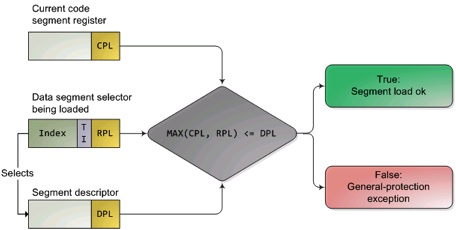
数值越大,特权级越低,图中MAX找出了CPL(当前活动代码段特权级,Current Privilege Level)和RPL(请求特权级,RPL保存在选择子的最低两位,Request Privilege Level)特权最低的一个,并与描述符特权级(描述符特权,描述对应段所属的特权等级,段本身能被访问的真正特权级,Descriptor Privilege Level)比较,优先级高于描述符特权级,则可以实现访问。绿色,说明被调用的函数优先级(DPL)低于调用者的优先级(MAX(CPL, RPL));红色,说明优先级过低,需要输入密码?
加载ELF格式的ucore kernel
// EFL头信息
struct elfhdr {
uint magic; // must equal ELF_MAGIC
uchar elf[12];
ushort type;
ushort machine;
uint version;
uint entry; // program entry point (in va)
uint phoff; // offset of the program header tables ,用于查找下下面结构体proghdr
uint shoff;
uint flags;
ushort ehsize;
ushort phentsize;
ushort phnum; // number of program header tables ,用于查找下下面结构体proghdr
ushort shentsize;
ushort shnum;
ushort shstrndx;
};
struct proghdr {
uint type; // segment type
uint offset; // beginning of the segment in the file,从哪个位置将代码段、数据段读取出来
uint va; // where this segment should be placed at
uint pa;
uint filesz;
uint memsz; // size of the segment in byte
uint flags;
uint align;
};
9.2.2 C函数调用的实现
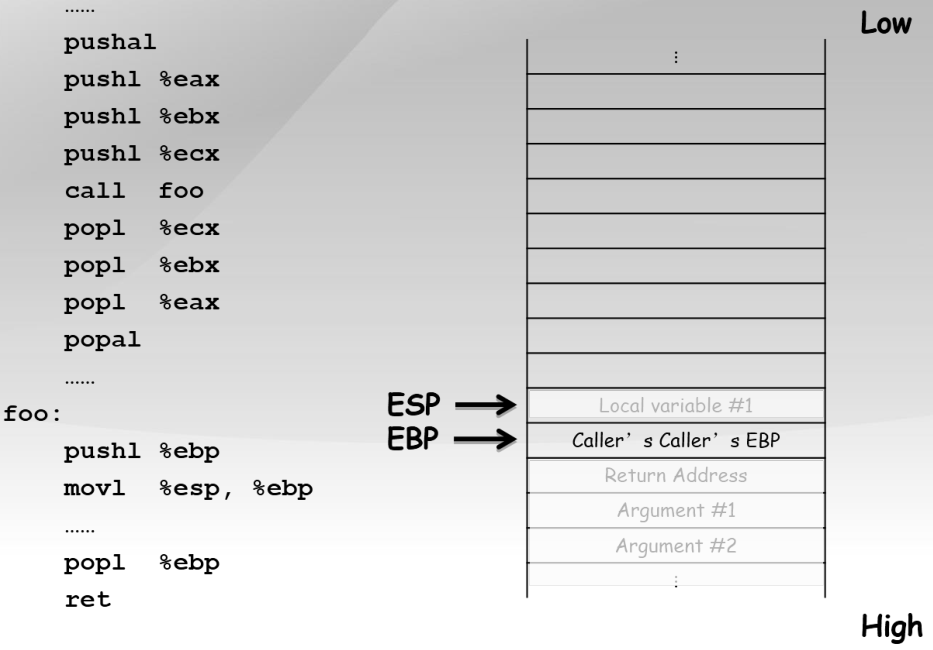
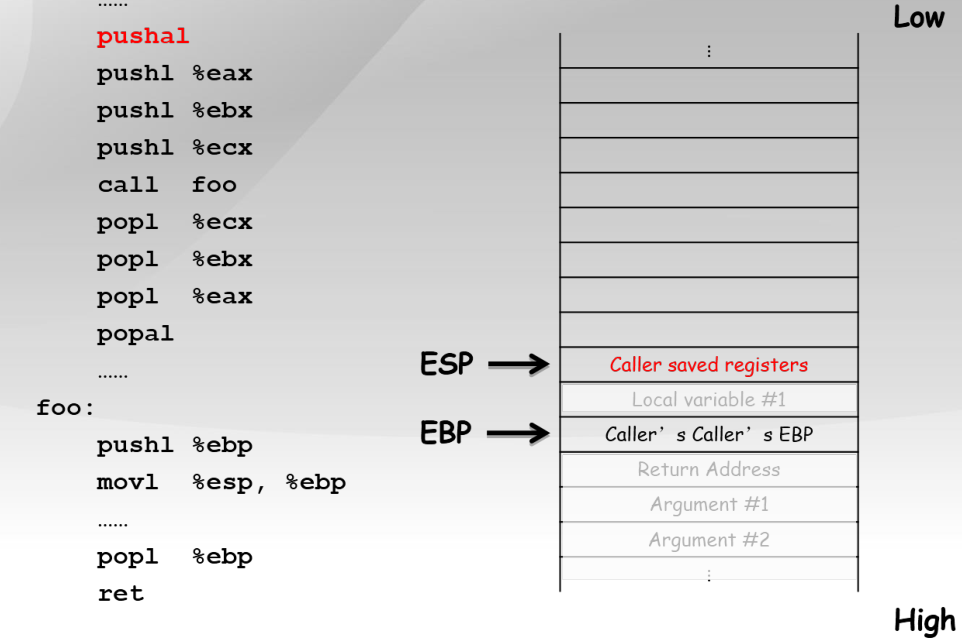
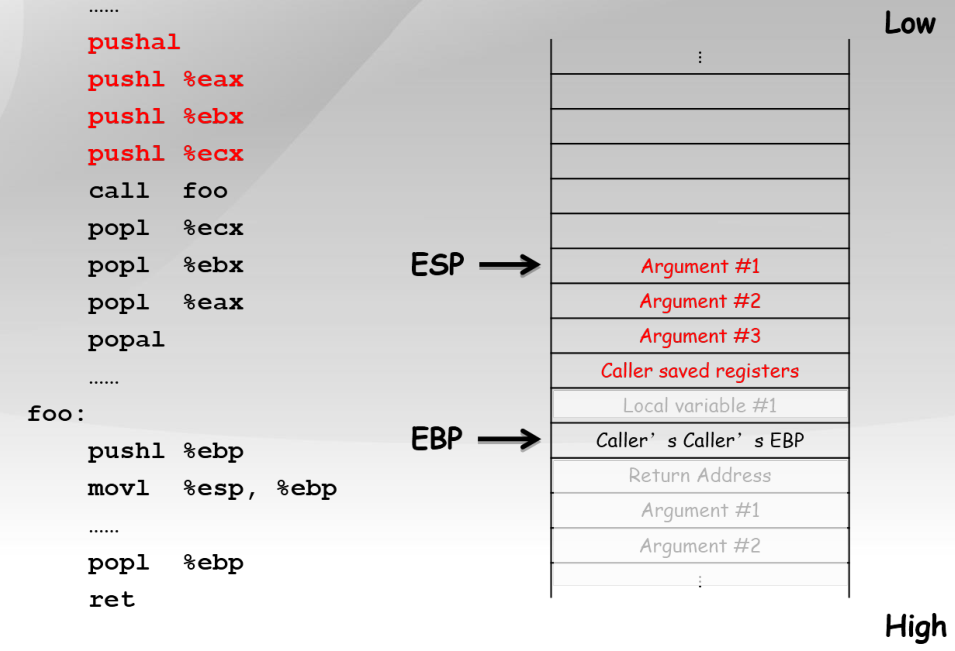
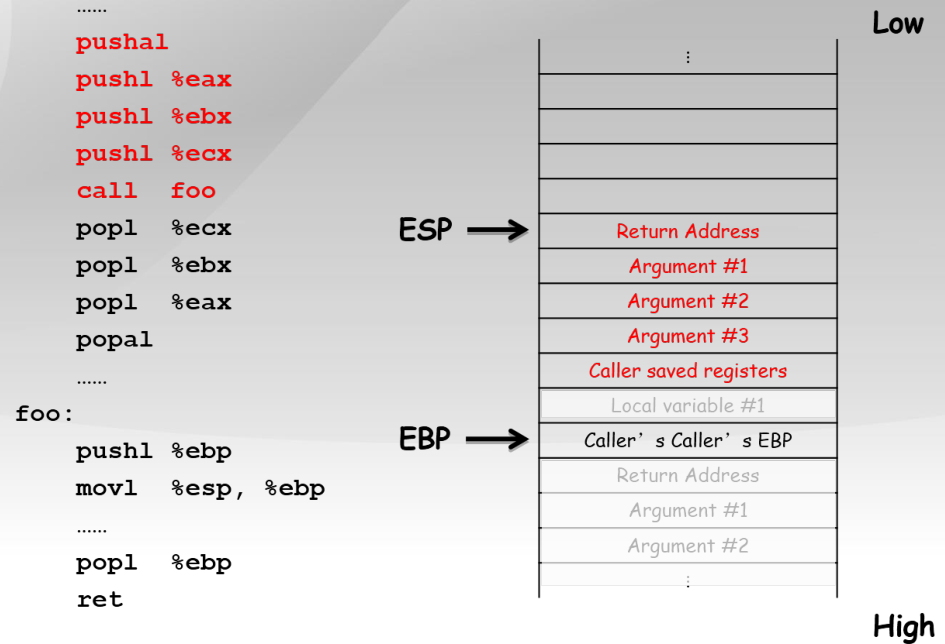
...
pushal ;保存当前函数的寄存器到堆栈
pushl %eax ;加法乘法指令的缺省寄存器
push1 %ebx ;在内存寻址时存放基地址
push1 %ecx ;是重复(REP)前缀指令和LOOP指令的内定计数器
call foo ;CALL指令内部其实还暗含了一个将返回地址(即CALL指令下一条指令的地址)压栈的动作(由硬件完成)
popl %ecx
popl %ebx
pop1 %eax
popal ;弹出寄存器
foo:
;几乎所有本地编译器都会在每个函数体之前插入类似如下的2条汇编指令
pushl %ebp ;将上一个函数的EBP保存
mov %esp,%ebp ;将ESP保存到EBP,即本函数的EBP指向栈区域
...
popl %ebp
ret
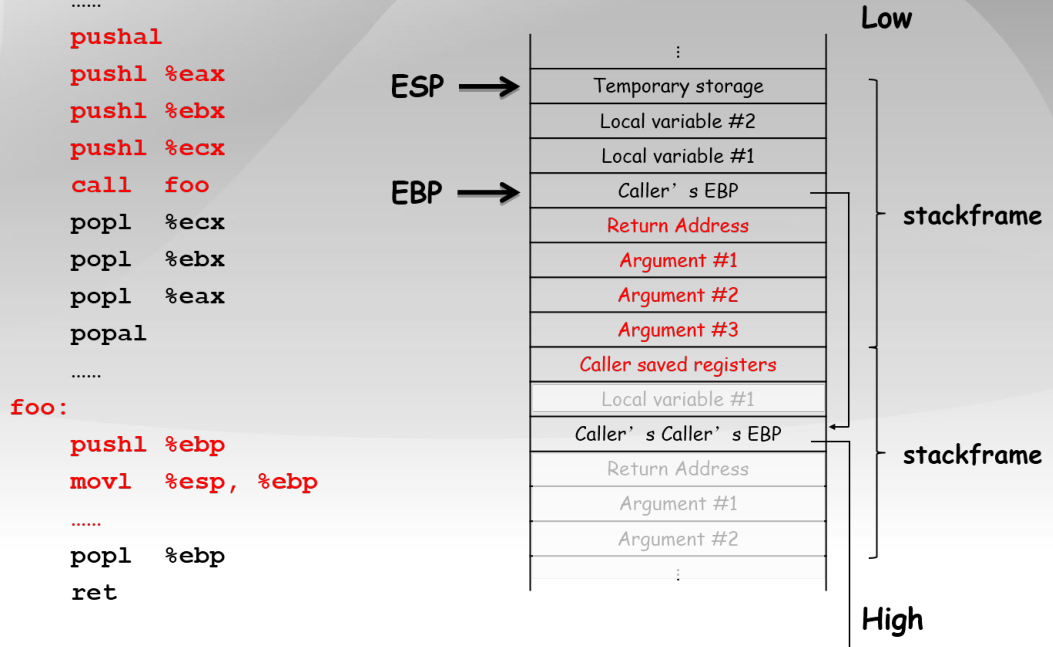
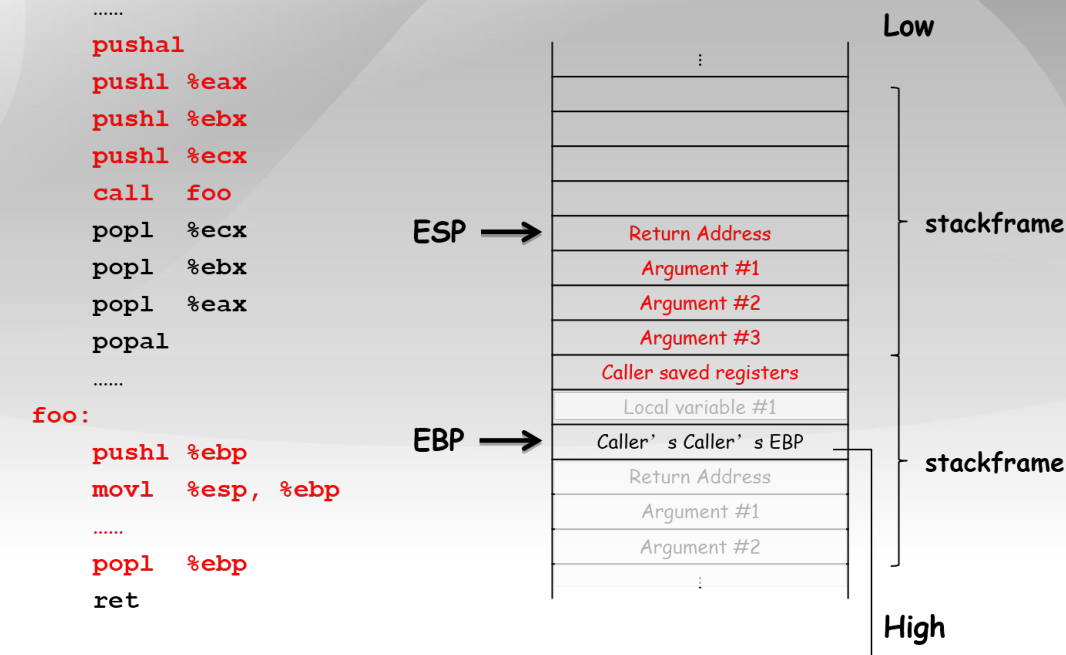
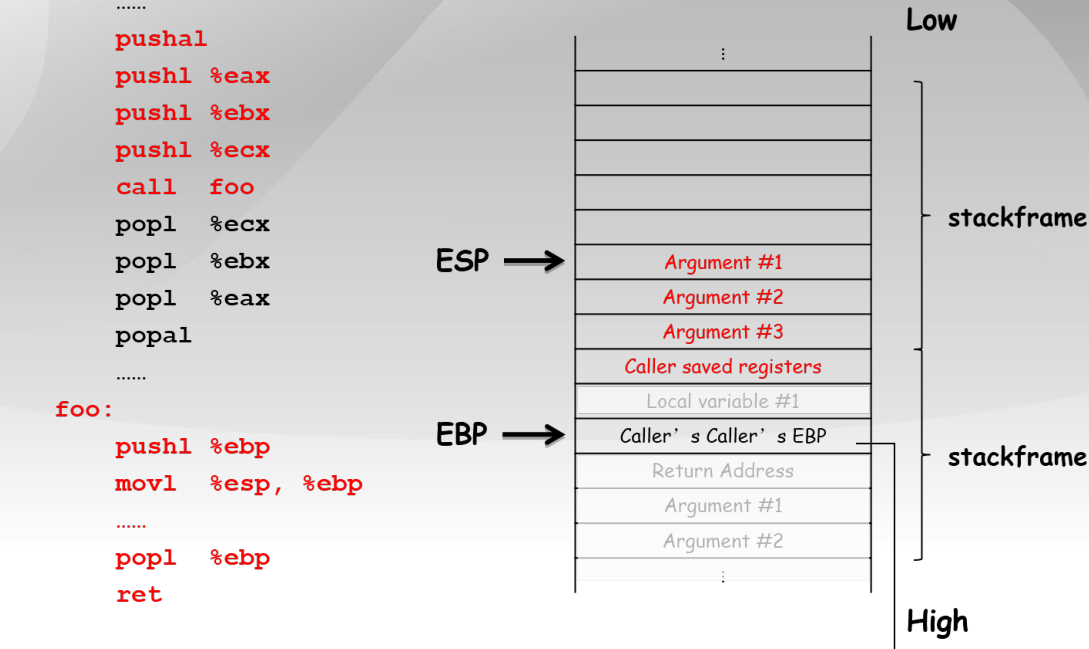
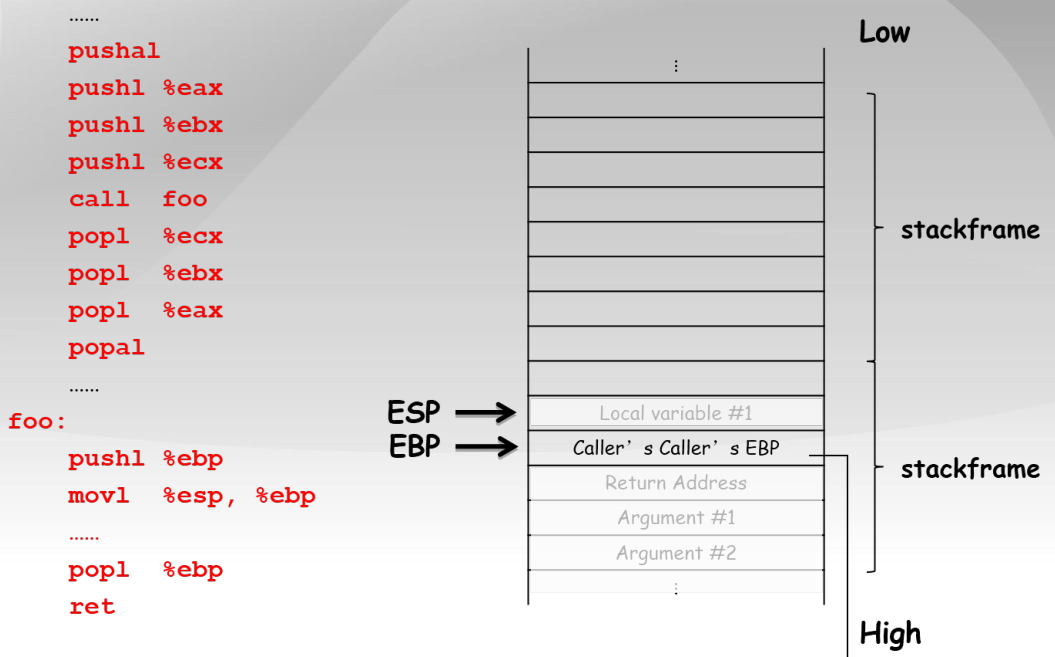
9.2.3 GCC内联汇编
在C语言中使用汇编。比如加载全局描述符表LGDT,必须使用汇编。
;asm
movl $0xffff,%eax
//c
asm("movl $0xffff,%%eax");
CC汇编语法
asm(assembler template
:output operands (optional)
:input operands (optional)
:clobbers (optional)
)
clobbers:该字段为可选项,用于列出指令中涉及到的且没出现在output operands字段及input operands字段的那些寄存器。若寄存器被列入clobber-list,则等于是告诉gcc,这些寄存器可能会被内联汇编命令改写。因此,执行内联汇编的过程中,这些寄存器就不会被gcc分配给其它进程或命令使用。
实例1
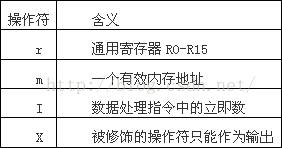
uint32_t cr0;
// volatile:不优化
// cr0-4:控制寄存器
// %0:第一个用到的寄存器
// r:任意寄存器,r0-r15
// = :被修饰的操作只写
asm volatile ("movl %%cr0, %0\n" :"=r"(cr0)); // 输出到cr0
cr0 |= 0x80000000;
asm volatile ("movl %0, %%cr0\n" ::"r"(cr0)); //cr0变量复制给寄存器cr0
对应的汇编:
movl %cr0, %ebx
movl %ebx, 12(%esp) ;12(%esp)表示局部变量
orl $-2147483648, 12(%esp)
movl 12(%esp), %eax
movl %eax, %cr0
补充

实例2
long __res, arg1 = 2, arg2 = 22, arg3 = 222, arg4 = 233;
__asm__ volatile ("int $0x80" //软中断
: "=a" (__res) // 将eax内容赋值给__res
: "0" (11),"b" (arg1),"c" (arg2),"d" (arg3),"S" (arg4)); // "b" (arg1):ar1数值赋值给寄存器ebx
等同于以下汇编:
movl $11, %eax
movl -28(%ebp), %ebx
movl -24(%ebp), %ecx
movl -20(%ebp), %edx
movl -16(%ebp), %esi
int $0x80 ;软中断
movl %eax, -12(%ebp)
内联汇编中的一些简写补充
a = %eax
b = %ebx
c = %ecx
d = %edx
S = %esi
D = %edi
0 = same as the first
9.2.4 文件说明
编译后在bin文件夹下会生成文件,包括:
-
ucore.img
被qemu访问的虚拟硬盘文件
-
kernel
ELF格式的toy ucore kernel执行文件,被嵌入到了ucore.img中
-
bootblock
虚拟的硬盘主引导扇区(512字节,可以看到bootblock文件大小为0x200字节,即500字节),包含了bootloader执行代码,被嵌入到了ucore.img中。由bootasm.S(经过sign外部执行程序)生成,会指定启示地址为0x7c00。
-
sign
外部执行程序,用来生成虚拟的硬盘主引导扇区
-
.S和.asm/s的区别.S(大写)文件还需要进行预处理、汇编等操作,.asm/s文件只需要汇编形成.o文件。
9.3 实验二 物理内存管理
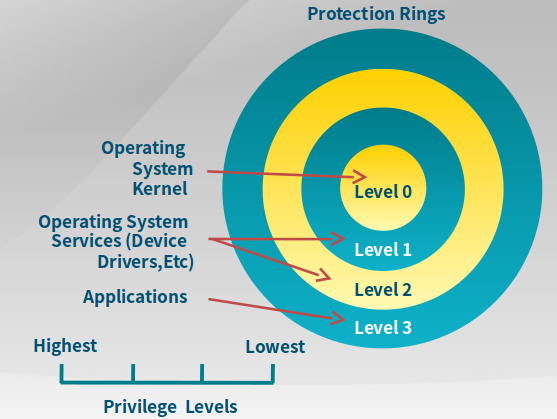
9.2.1 X86保护模式中的特权级
利用X86硬件实现内存保护,下面是Intel支持的特权级共4个,一般只需要用到内核态的Level0和用户态的Level3即可。
特权级区别?
一些指令(如修改页表、响应中断、访问内核数据)只能在ring0
访问数据段、访问页、进入中断服务例程(ISRs)会检查特权级。
特权级表示
-
段选择子
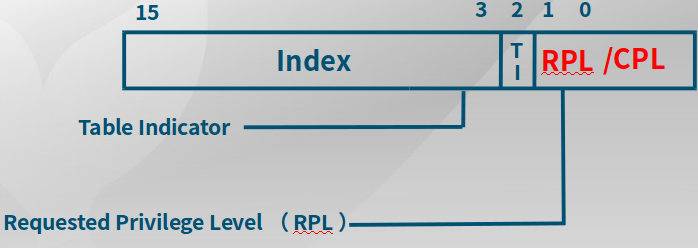
RPL:段寄存器 DS、ES、FS、GS的低两位,指向数据段
CPL:段寄存器 CS,指向程序段(注:SS指向堆栈段,CS指向程序段,两者特权级是一样的,比如内核态SS CPL是0,SS需要指向特权级为ring0的堆栈)
-
段描述符
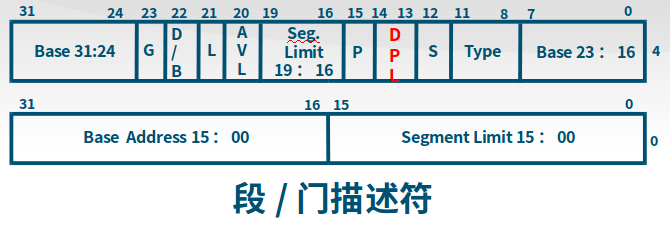
DPL:段描述符,门描述符(当中断发生时必须先访问这些“门”,进而进入相应的程序)
访问门和访问段时候的区别
访问门:满足CPL<=DPL[门] && CPL >= DPL[段],CPL >= DPL[段]使得低优先级程序可以访问高优先级段(比如内核态的数据)。
访问段:MAX(CPL, RPL) <= DPL
实现特权级跳转
-
ring0到ring3
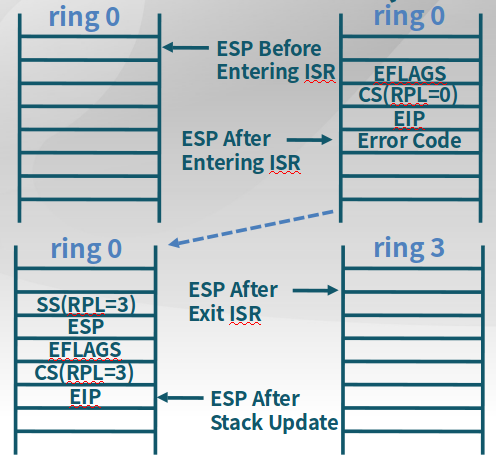
ring0内核态进入中断后,将ring3用户态的信息更新到栈中,调用IRET将信息弹出栈,进而能进入用户态。如下图所示:
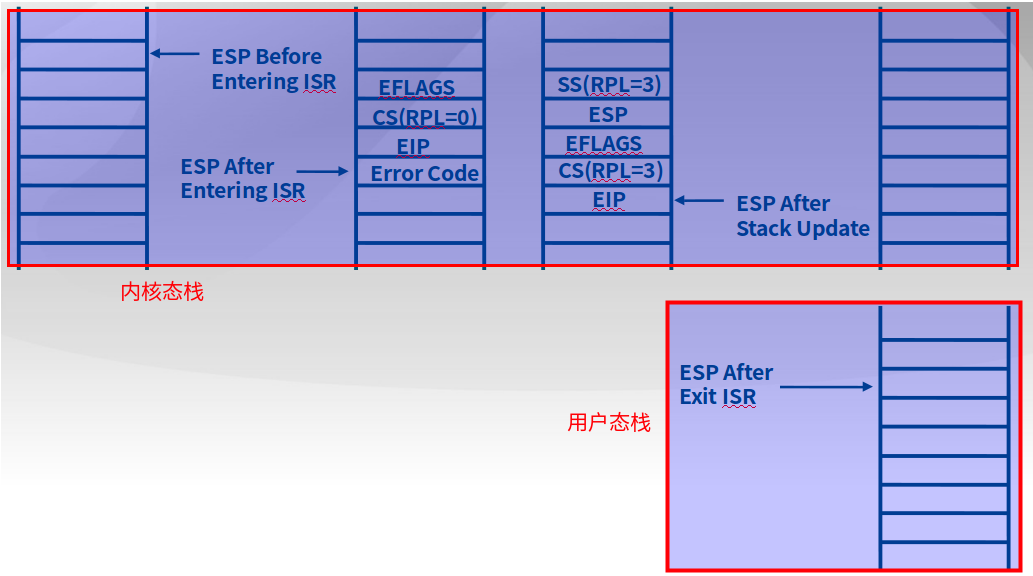
-
ring3到ring0
使用软中断/trap来从ring3到ring0,ring3进入中断后,将内核态信息更新到栈中,调用IRET将信息出栈,进而能进入内核态。
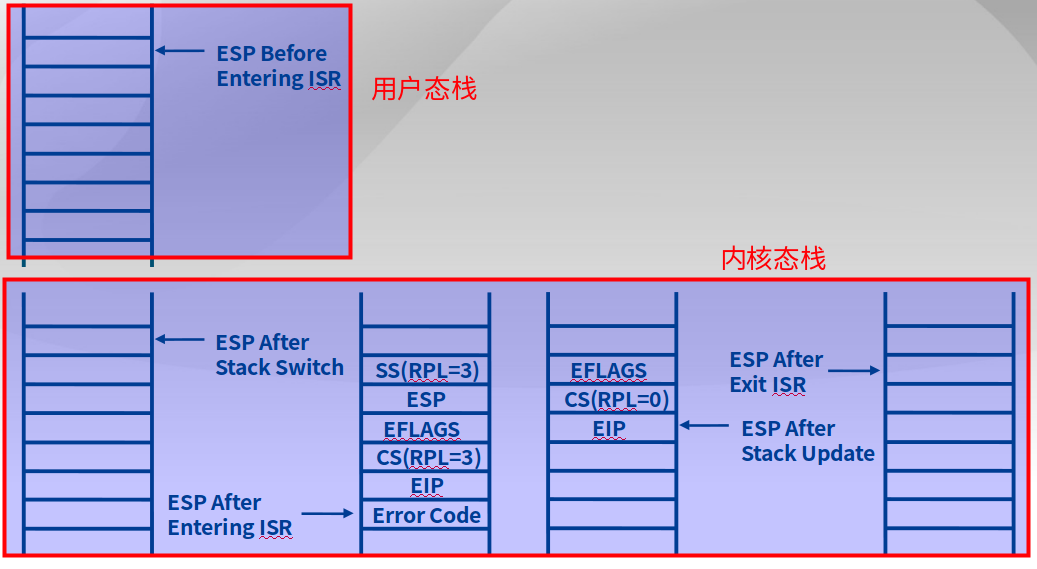
实现特权级转换的时候,如何知道堆栈地址在哪里
一块内存地址空间中有一块区域保存任务状态段Task State Segment,其中保存了不同特权级的栈地址,可以通过TSS描述符来找到这块TSS,从而知道EIP(SS:ESP)地址。

下面是如何通过一个任务寄存器找到TSS的描述符,进而找到TSS。
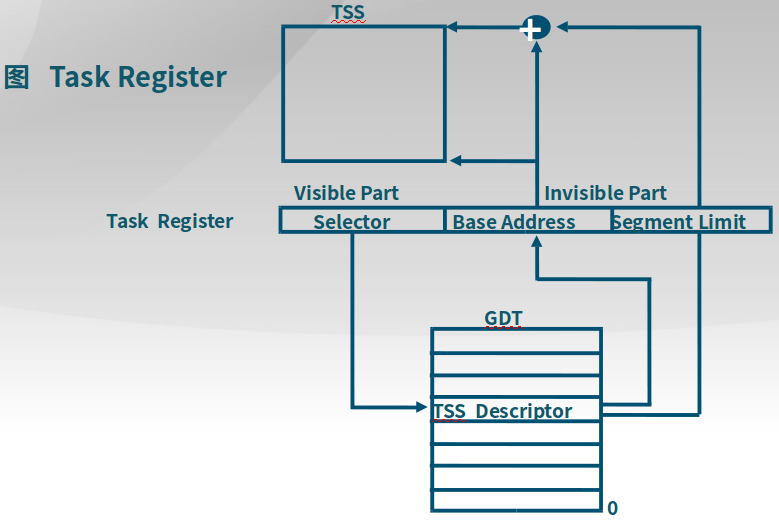
具体的设置方式是:
分配TSS空间 -> 初始化TSS -> 段描述符表中添加TSS描述符 -> 设置TSS的选择子(也就是上述任务寄存器)
9.2.2 内存管理单元MMU
将虚拟地址空间映射到分散的物理地址空间
页机制过程
页机制通过CR0的第31位(PG)来启动。
下图中,线性地址Linear Address是段机制产生的地址。线性地址高10位用来索引页目录中的页目录(CR3寄存器保存页目录基址)入口PDE,也就是页表的基址,再通过线性地址中间10位索引页表,得到页的基址,最后12位(4K空间)是在页中找到对应的物理地址空间。注意:页表项保存的是线性地址。
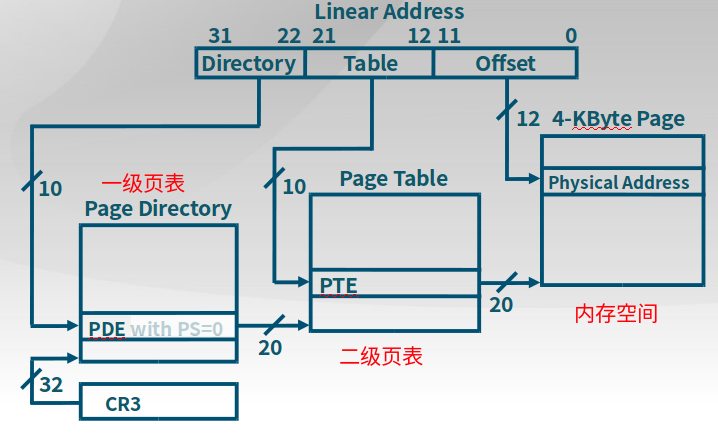
建立页表
创建一个目录页 -> 初始化/清除分配好的页 -> 将0xC0000000-OxF8000000(虚拟地址)映射到0x00000000-0x38000000(物理地址) -> 将0x00000000-Ox00100000(虚拟地址)映射到0x00000000-0x00100000(物理地址) -> 设置CR3寄存器(目录页基址)和CR0的PG(启动页机制) -> 更新GDT -> 取消将0x00000000-Ox00100000(虚拟地址)映射到0x00000000-0x00100000(物理地址)
段页式机制
1.逻辑地址通过段选择子选择全局描述符表中的段描述符得到某一个段的基址,并加上Offset来得到对应的线性地址。注意:线性地址其实也是虚的,只是一个数字,而不对应物理空间。
2.线性地址会被拆分Dir、Table和Offset三部分,经过页机制找到对应的物理地址空间。
页数据结构创建
可参考清华ucore_os_docs.pdfP149 以页为单位管理物理内存
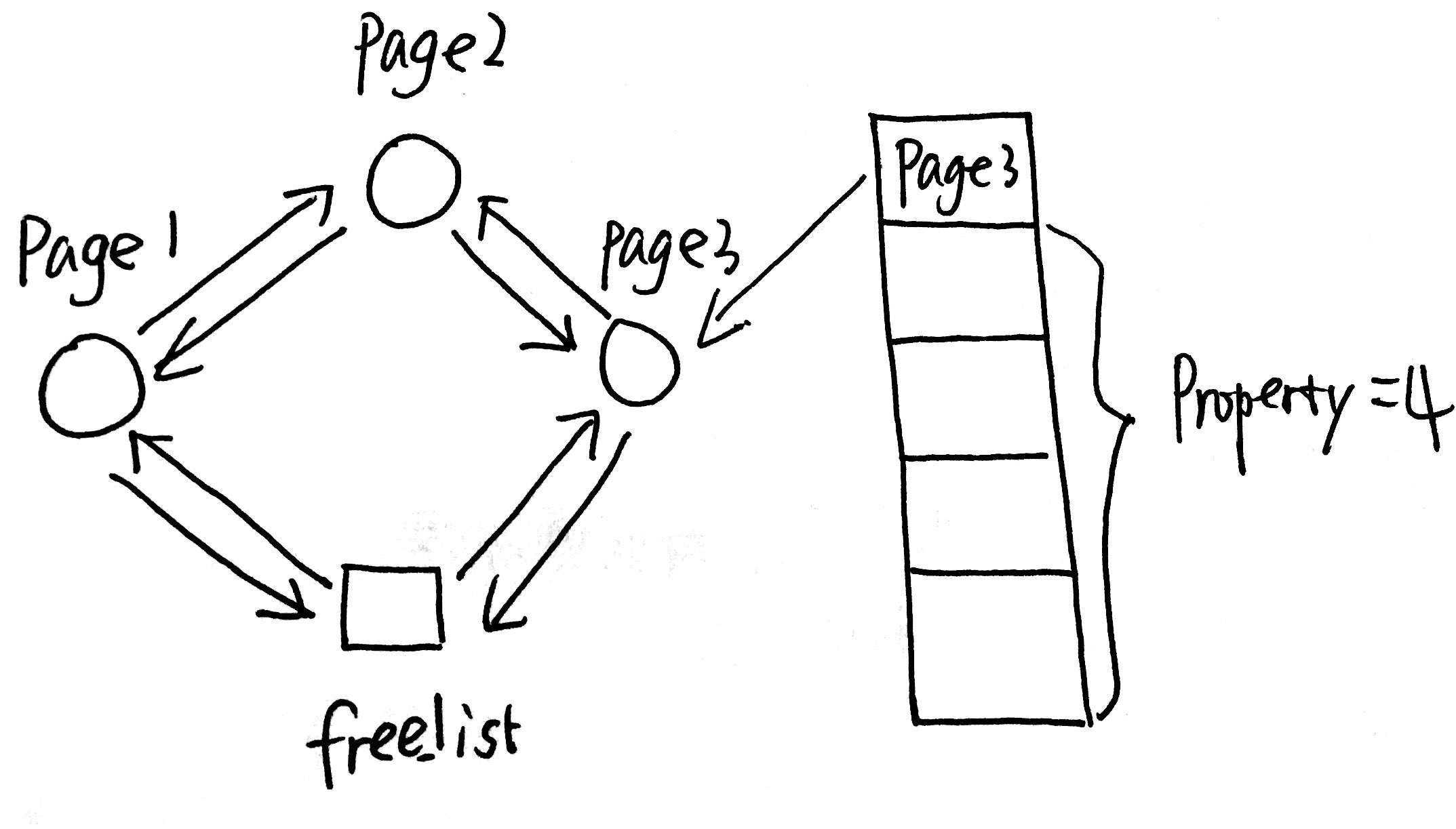
1.创建一块free页管理列表(以free_area_t类型数据开头),列表中包含多个可以使用的连续内存空间块的信息(page来描述),这个page占用了连续内存空间的第一页
struct Page {
int ref; // 页被页表引用的次数
uint32_t flags;// 物理页的状态标记:被保留(已经被使用,不会存在于free页管理列表中)、可被使用
unsigned int property;// 连续内存空间块的大小
list_entry_t page_link;// 连接其他的page和free_list
};
typedef struct {
list_entry_t free_list; // 列表头
unsigned int nr_free; // 共有多少个列表
} free_area_t;
下图是free_list链接多个page的视图(free_list和page_link双向链接):
2.分配一块n个页的区域给一个页表引用
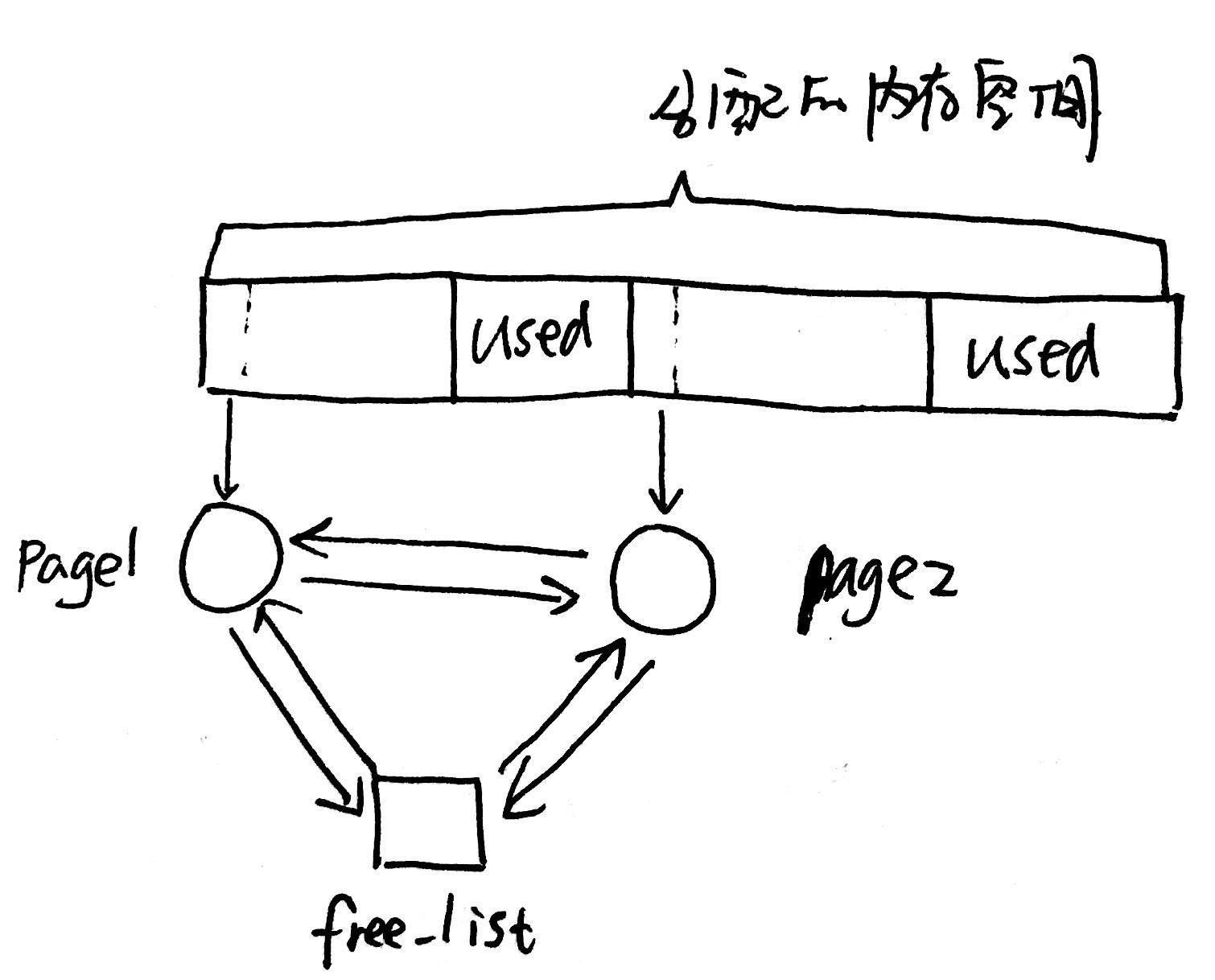
查找方法较多,以搜索到的首个page为例。搜索page1,发现page1后面跟着多于n个的页,那么就可以将前面n个页分配给页表引用(连续的线性地址)。剩下的一些页,重新创建一个以page4开头的连续内存空间。page4加入到free页管理列表,并将page1从列表中删除(因为已经被使用了)。
操作系统如何给进程分配段表和页表?
-
分页机制
操作系统会为每个进程或任务建立一个页表(这个页表可能是一级的也可能是多级的)。整个操作系统中有多个进程在运行,那么系统就会有多个页表。页表在内存中的存储位置由寄存器CR3给出。
-
分段机制
操作系统会为每个进程或任务建立一个段表(段描述符,一般不用多级),用于记录数据段、代码段等各类段在内存中的具体位置。
-
段页式机制
一般一个进程或任务,操作系统会给其建立一个段表,而段表中的每个段又会对应一个页表(由段描述符得到的线性地址分割为页目录、页表索引和Offset,页目录每一项加上页表索引就是页表中的某一个页基址),也就是说,段页式机制的每个进程有一个段表,有多个页表。
9.4 实验三 虚存管理
9.4.1 虚存管理总体框架
-
完成初始化虚拟内存管理机制:IDE 硬盘读写,缺页异常处理
@ kern_init函数。 -
设置虚拟页空间和物理页帧空间,表述不在物理内存中的“合法”虚拟页
mm_struct @ vmm.h和vma_struct @ vmm.h两个结构体。 -
完善建立页表映射、页访问异常处理操作等函数实现
do_pgfault @ vmm.c -
执行访存测试,查看建立的页表项是否能够正确完成虚实地址映射
-
执行访存测试,查看是否正确描述了虚拟内存页在物理内存中还是在硬盘上
-
执行访存测试,查看是否能够正确把虚拟内存页在物理内存和硬盘之间进行传递
-
执行访存测试,查看是否正确实现了页面替换算法等
check_vmm @ vmm.c测试vma的结构体、pgfault、页置换算法(swap.c/h)。
9.4.2 关键数据结构
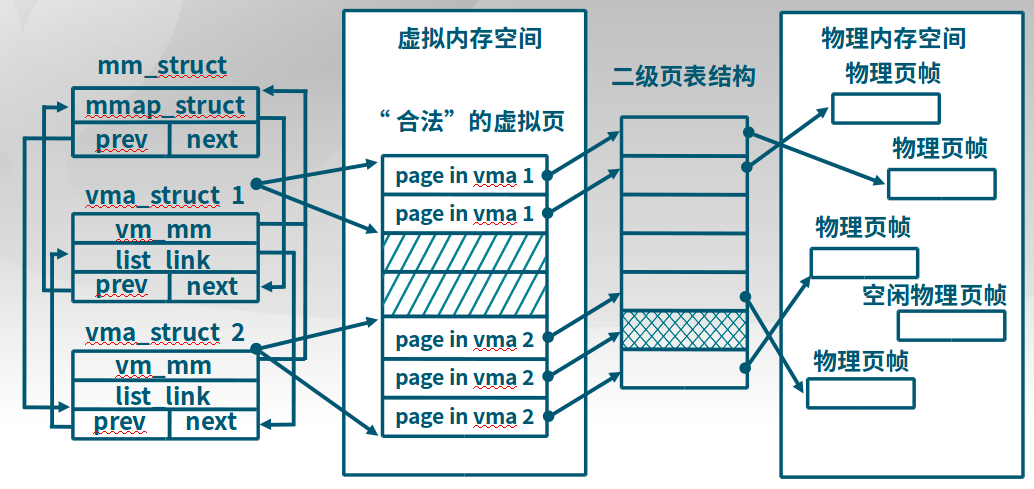
vma_struct @ \kern\mm\vmm.h和mm_struct @ \kern\mm\vmm.h,mm用于管理一系列vma(使用同一个页目录PDT,Page Directory Table),而vma全称是虚拟连续存储区域(Virtual continuous Memory Area)
具体代码如下:
// the virtual continuous memory area(vma), [vm_start, vm_end),
// addr belong to a vma means vma.vm_start<= addr <vma.vm_end
// [scc] 合法的用户使用空间
struct vma_struct {
struct mm_struct *vm_mm; // the set of vma using the same PDT
uintptr_t vm_start; // start addr of vma
uintptr_t vm_end; // end addr of vma, not include the vm_end itself
uint32_t vm_flags; // flags of vma
list_entry_t list_link; // linear list link which sorted by start addr of vma
};
// the control struct for a set of vma using the same PDT
struct mm_struct {
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
pde_t *pgdir; // the PDT of these vma
int map_count; // the count of these vma
void *sm_priv; // the private data for swap manager
};
9.4.3 缺页异常处理
-
vector14 @ vector.S中断向量表找到特定的入口,将中断号入栈,然后调用
__alltraps。 -
__alltraps @ trapentry.S将必要的寄存器入栈,然后调用
trap。 -
trap @ trap.c调用
trap_dispatch -
trap_dispatch @ trap.c根据
vector14 @ vector.S入栈的中断号来进行特定的处理,这里是缺页错误编号。 -
pgfault_handler @ trap.c调用
do_pgfault -
do_pgfault @ vmm.c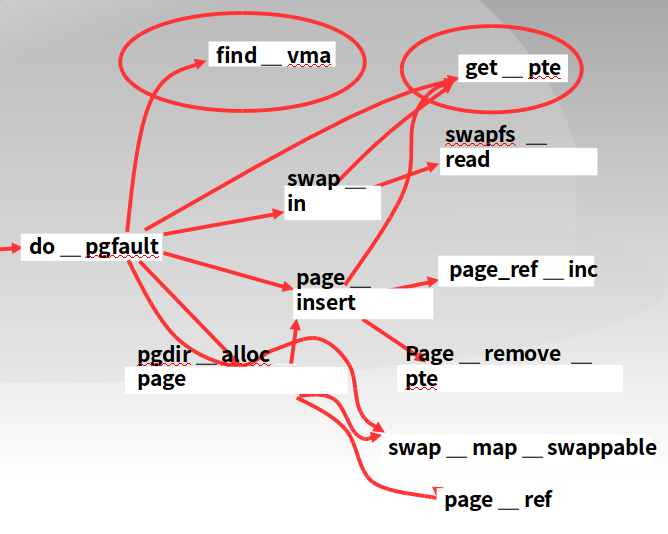
9.4.4 页置换机制
-
应该换出哪些页
-
check_swap @ swap.c -
如何建立虚拟页和磁盘扇区的对应关系
PTE(页表入口, Page Table Entry),如果页表的标志位为0,表示虚拟页和物理页没有对应关系,需要从磁盘扇区读取,而磁盘扇区的地址保存位置就是物理页保存的问题,实现复用。
swap_entry_t |----------------------|----------|--| offset reserved 0 24bits 7bits 1bit
-
-
何时进行页置换
-
换入
check_swap -> page fault -> do_pgfault -
换出
主动策略
被动策略(ucore)
在ucore通过Page结构体来实现空闲页的管理。
-
9.5 实验四 内核线程管理
9.5.1 总体流程
-
定义关键数据结构
-
线程控制块
-
线程控制快列表
-
-
环境初始化并执行内核线程
-
虚拟内存初始化
-
内核线程初始化
-
创建内核线程
-
切换内核线程
-
9.5.2 关键数据结构
struct proc_struct {
enum proc_state state; // 当前运行的状态,动态
int pid; // 进程ID
int runs; // the running times of Proces
uintptr_t kstack; // 内核堆栈
volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct mm_struct *mm; // mm,对于内核进程而言可以是NULL,因为常驻内存中
struct context context; // 上下文,即一堆寄存器EIP、ESP等
struct trapframe *tf; // Trap frame for current interrupt
uintptr_t cr3; // 指定页表,对于内核线程而言,和进程共享页表
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // 进程名称
list_entry_t list_link; // 进程链表
list_entry_t hash_link; // 进程hash表
int exit_code; // exit code (be sent to parent proc)
uint32_t wait_state; // waiting state
struct proc_struct *cptr, *yptr, *optr; // relations between processes
};
// 控制诸多VMA
struct mm_struct {
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
pde_t *pgdir; // the PDT of these vma
int map_count; // the count of these vma
void *sm_priv; // the private data for swap manager
int mm_count; // the number ofprocess which shared the mm
lock_t mm_lock; // mutex for using dup_mmap fun to duplicat the mm
};
// virtual continuous memory area
// 虚拟连续内存空间
struct vma_struct {
struct mm_struct *vm_mm; // the set of vma using the same PDT
uintptr_t vm_start; // start addr of vma
uintptr_t vm_end; // end addr of vma
uint32_t vm_flags; // flags of vma
list_entry_t list_link; // linear list link which sorted by start addr of vma
};
-
mm
内存管理的信息,包括内存映射列表、页表指针等。mm成员变量在lab3中用于虚存管理。但在实际OS中,内核线程常驻内存,不需要考虑swap page问题,在lab5中涉及到了用户进程,才考虑进程用户内存空间的swap page问题,mm才会发挥作用。所以在lab4中mm对于内核线程就没有用了,这样内核线程的
proc_struct的成员变量mm=0是合理的。mm里有个很重要的项pgdir,记录的是该进程使用的一级页表的物理地址。由于mm=NULL,所以在proc_struct数据结构中需要有一个代替pgdir项来记录页表起始地址,这就是proc_struct数据结构中的cr3成员变量。 -
context
进程的上下文,用于进程切换(参见
switch.S,将本线程的上下文保存,将下一个线程的上下文加载)。在 uCore中,所有的进程在内核中也是相对独立的(例如独立的内核堆栈以及上下文等等)。使用context保存寄存器的目的就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是在kern/process/switch.S中定义switch_to。 -
tf
全称trap frame,中断帧
中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生时
tf总是能够指向当前的trapframe,uCore在内核栈上维护了tf的链,可以参考trap.c::trap函数做进一步的了解。 -
cr3
页表地址
-
kstack
每个线程都有一个内核栈,并且位于内核地址空间的不同位置。对于内核线程,该栈就是运行时的程序使用的栈;而对于用户进程,该栈是发生特权级改变的时候使保存被打断的硬件信息用的栈。
9.5.3 创建第0个内核线程
initproc proc_init()
|
初始化trapframe kernel thread() (tf设置 -> do_fork()见下方 )
|
初始化initproc alloc_proc()
|
初始化内核堆栈 setup_kstack()
|
内存拷贝 copy_stack()
|
把initproc放到就绪队列 加入到hash表、链表
|
唤醒initproc wakeup_proc()
9.6 实验五 用户进程管理
实验一到四都是在内核态中运行,而本次用户进程管理是需要在用户态中进行。
9.6.1 总体介绍
- 给应用程序需要一个用户运行环境
- 进程管理:加载、复制(fork)、生命周期、系统调用(得到操作系统服务)
- 内存管理:用户态虚拟内存
- 构造出第一个用户进程
- 建立用户代码/数据段(之前都是内核的)
- 创建内核线程
- 创建用户进程的进程控制块(壳)
- 填写用户进程的内容(肉)
- 执行用户进程(在用户态执行)
- 完成系统调用(调用操作系统服务)
- 结束用户进程,资源回收
9.6.2 进程的内存布局
在实验五中,还不能做到将文件系统中ELF加载来运行,而是和操作系统一块加载,然后创建进程,并在该进程中运行程序。下面图1是内核态虚拟内存空间,图2是用户态虚拟内存空间。

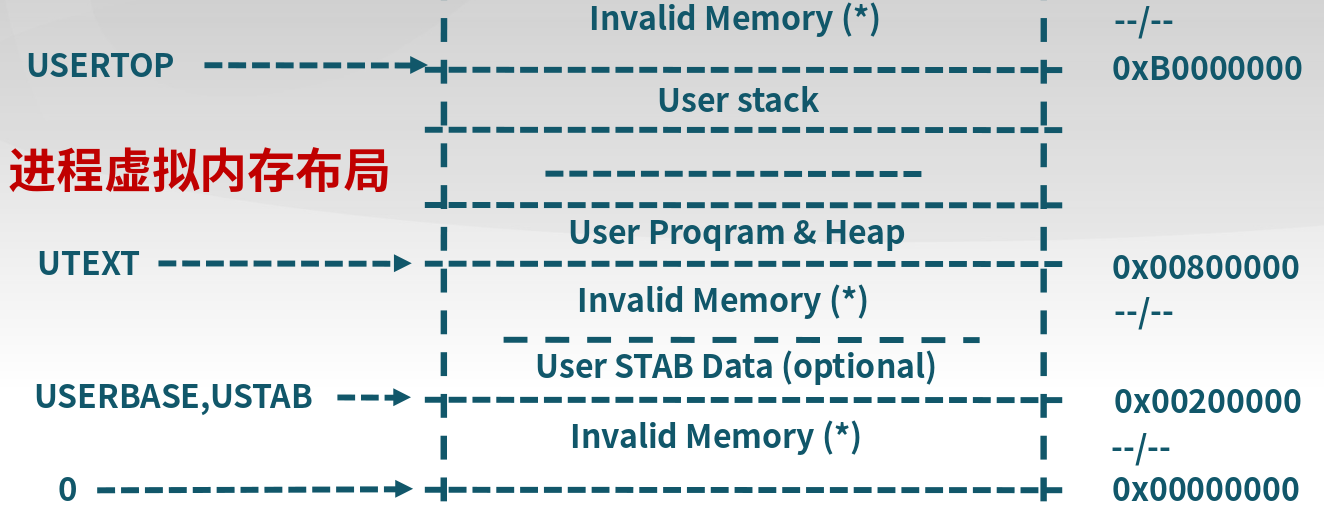
bootloader内存空间配置文件为tool/boot.ld,内核虚拟内存空间配置文件为tool/kernel.ld,用户态虚拟内存空间配置文件为tool/user.ld
虚拟空间映射的text版本,此处看到KERNBASE是0xC0000000但是我们看到kernel.ld文件设置的是. = 0xC0100000;。原因是在对应到物理地址空间,低地址还有Bootloader占用的1MB空间,恰好是0x100000。
/* *
* Virtual memory map: Permissions
* kernel/user
*
* 4G ------------------> +---------------------------------+
* | |
* | Empty Memory (*) |
* | |
* +---------------------------------+ 0xFB000000
* | Cur. Page Table (Kern, RW) | RW/-- PTSIZE
* VPT -----------------> +---------------------------------+ 0xFAC00000
* | Invalid Memory (*) | --/--
* KERNTOP -------------> +---------------------------------+ 0xF8000000
* | |
* | Remapped Physical Memory | RW/-- KMEMSIZE
* | |
* KERNBASE ------------> +---------------------------------+ 0xC0000000
* | Invalid Memory (*) | --/--
* USERTOP -------------> +---------------------------------+ 0xB0000000
* | User stack |
* +---------------------------------+
* | |
* : :
* | ~~~~~~~~~~~~~~~~ |
* : :
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* | User Program & Heap |
* UTEXT ---------------> +---------------------------------+ 0x00800000
* | Invalid Memory (*) | --/--
* | - - - - - - - - - - - - - - - |
* | User STAB Data (optional) |
* USERBASE, USTAB------> +---------------------------------+ 0x00200000
* | Invalid Memory (*) | --/--
* 0 -------------------> +---------------------------------+ 0x00000000
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired.
*
* */
9.6.3 执行ELF格式的二进制代码
-
删除原来的内存空间
do_execve @ proc.cif (mm != NULL) { lcr3(boot_cr3); if (mm_count_dec(mm) == 0) { exit_mmap(mm); put_pgdir(mm); mm_destroy(mm); } current->mm = NULL; } -
加载代码
load_icode() @ proc.cif ((ret = load_icode(binary, size)) != 0) { goto execve_exit; }-
创建新的内存空间
// [LAB5 SCC] 申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化 if ((mm = mm_create()) == NULL) { goto bad_mm; } // [LAB5 SCC] 申请一个页目录表所需的一个页大小的内存空间, // 并把描述ucore内核虚空间映射的内核页表(boot_pgdir所指)的内容拷贝到此新目录表中, // 最后让mm->pgdir指向此页目录表 if (setup_pgdir(mm) != 0) { goto bad_pgdir_cleanup_mm; } -
遍历ELF的各种段,并设置代码空间
具体见代码
- 设置各个虚存空间的可读可写情况
- 拷贝ELF的内容到上述空间
- BSS段清空
-
设置用户堆栈
上述代码空间中不包含用户堆栈,需要为该进程分配用户堆栈
-
加载新的页表
-
设置trapframe
可用于用户和内核空间之间的转换时,保存不同态的信息。下面是内核态到用户态的寄存器变化情况,此时需要将内核态信息保存下来。
-
9.6.4 进程复制
do_fork()的过程
分配新的proc alloc_proc()
|
分配kernel stack setup_kstack()
|
复制父进程内存 copy_mm() 、 copy_range()
|
设置trapfame & context copy_thread()
|
其他操作
|
返回PID(子进程是0)
9.6.5 Copy-on-write机制
在没有写的时候,子进程和父进程共用空间;如果有写操作,则将该部分独立开来。
9.6.6 用户态进程和内核态进程的对比
-
用户态进程和内核态进程的虚拟内存空间不共用
所以Lab5需要增加用户态虚拟内存的管理。为了管理用户态的虚拟内存,需要对页表的内容进行扩展,能够把部分物理内存映射为用户态虚拟内存。
-
用户态和内核态数据拷贝时,必须处于内核态
9.7 实验六 处理机调度
9.7.1 调度过程
-
触发
proc_tick函数,决定是否需要调度 -
入队
enqueue函数有一个叫作
run_queue的就绪队列将所有就绪进程链接起来当然还有一个等待队列用于链接所有等待进程
-
选取
proc_next函数 -
出队
dequeue函数 -
切换
switch_to函数
9.7.2 调度算法支撑框架
| 序号 | 位置 | 原因 |
|---|---|---|
| 1 | proc.c:do_exit |
用户线程执行结束,主动放弃CPU |
| 2 | proc.c:do_wait |
用户线程等待子进程结束,主动放弃CPU |
| 3 | proc.c:init_main |
1. Initproc内核线程等待所有用户进程结束;2. 所有用户进程结束后,回收系统资源 |
| 4 | proc.c::cpu_idle |
idleproc内核线程等待处于就绪态的进程或线程,如果有选取一个并切换进程 |
| 5 | sync.h::lock |
进程如果无法得到锁,则主动放弃CPU |
| 6 | trap.c::trap |
修改当前进程时间片,若时间片用完,则设置need_resched为1,让当前进程放弃CPU |
以下是一个调度总函数
void
cpu_idle(void) {
while (1) {
// [LAB6 SCC] 进程需要调度,该标志位周期性的设置为1
if (current->need_resched) {
schedule();
}
}
}
void
schedule(void) {
bool intr_flag;
struct proc_struct *next;
local_intr_save(intr_flag);
{
// [LAB6 SCC] 设置为不可调度,因为一般在调用schedule时,为调度的状态
current->need_resched = 0;
// [LAB6 SCC] 当前的进程入队
if (current->state == PROC_RUNNABLE) {
sched_class_enqueue(current);
}
// [LAB6 SCC] 选择一个进程,并从队列中取出
if ((next = sched_class_pick_next()) != NULL) {
sched_class_dequeue(next);
}
if (next == NULL) {
next = idleproc;
}
next->runs ++;
// [LAB6 SCC] 运行进程
if (next != current) {
proc_run(next);
}
}
local_intr_restore(intr_flag);
}
9.7.3 时间片轮转调度算法(Round Robin)
RR算法最主要的思想集中于触发函数proc_tick,周期性触发计数,使能调度标志位。然后调用调度函数schedule来实现保存当前进程、运行下一个进程等功能。
struct sched_class {
// the name of sched_class
const char *name;
// Init the run queue
void (*init)(struct run_queue *rq);
// put the proc into runqueue, and this function must be called with rq_lock
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);
// get the proc out runqueue, and this function must be called with rq_lock
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);
// choose the next runnable task
struct proc_struct *(*pick_next)(struct run_queue *rq);
// dealer of the time-tick
// [LAB6 SCC] 对于时间片轮转调度算法来说,在此函数中实现计数,如果到达时间窗结束,则使能调度标志位,开始下一个进程的调度
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);
};
9.7.4 Stride调度算法
9.8 实验七 同步互斥
10.拓展
10.1 ld链接文件解析
-
简单语法说明
SECTIONS { /*代码应当被载入到地址0x10000*/ . = 0x10000; .text : { *(.text) } /*数据从0x8000000*/ . = 0x8000000; .data : { *(.data) } .bss : { *(.bss) } } -
语法细节
SECTIONS { /* 给特殊符号.幅值,.是定位计数器*/ . = 0x10000; /*定义输出节.text*/ /*冒号、中括号是语法需要*/ /* *(.text) 表示匹配所有输入文件中的'.text'输入节*/ .text : { *(.text) } . = 0x8000000; .data : { *(.data) } .bss : { *(.bss) } }
欢迎关注我的微信公众号
互联网矿工
