1、数值计算
d1.count() #非空元素计算
d1.min() #最小值
d1.max() #最大值
d1.idxmin() #最小值的位置,类似于R中的which.min函数
d1.idxmax() #最大值的位置,类似于R中的which.max函数
d1.quantile(0.1) #10%分位数
d1.sum() #求和
d1.mean() #均值
d1.median() #中位数
d1.mode() #众数
d1.var() #方差
d1.std() #标准差
d1.mad() #平均绝对偏差
d1.skew() #偏度
d1.kurt() #峰度
d1.describe() #一次性输出多个描述性统计指标
2、函数
len(df):输出一共几行
df.fillna(0):用0填充NaN
3、索引
df[[‘user’,’merchant’]]:索引里面是一个列表,所以是两个[]
4、SQL
Orient2User = pd.merge(temp, Orient2User, on=’User_id’, how=’outer’):两个df合起来
Orient2User = off_train.groupby([‘User_id’], as_index = False)[‘sum’].agg({‘count’:np.sum}):根据User_id计算一共多少人,每个人的频率。需要在原df上加df[‘sum’]=1
5、缺失值处理
5.1 data.isnull().any()
isnull:返回data中数据是否缺失,以矩阵的形式
any:只要矩阵中有一个true,就返回true
5.2 清理无效数据
df.dropna() # 删除所有含nan项的row
d.dropna(axis=1,thred=3) # 将在列的方向上三个为NaN的项删除
df.dropna(how='ALL') # 将所有项都是nan的row删除
df.drop(['a']) # 删除行,其中'a'是删除的行的index
df.drop(['Ohio'],axis=1) # 删除列,'Ohio'是删除的列的名称
df.drop(['a'],inplace=True) # 就地修改原来的数据df,inplace = True
X、注意点
X.1 copy问题
有的时候直接复制
df1 = df2
df1['id'] = ...
会出现
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
需要改成
df1 = df2.copy()
df1['id'] = ...
说明:在python里,直接赋值,表示两个变量是相同的引用,只是别名
a=b.copy(),拷贝父对象,不会拷贝对象的内部的子对象。
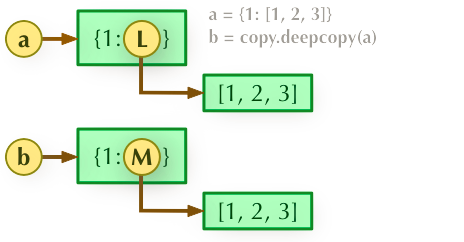
a=copy.deepcopy(b), copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。也就是说,两者独立。(需要import copy)
1、直接赋值a=b
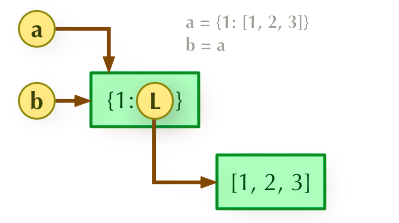
2、a = b.copy()浅拷贝
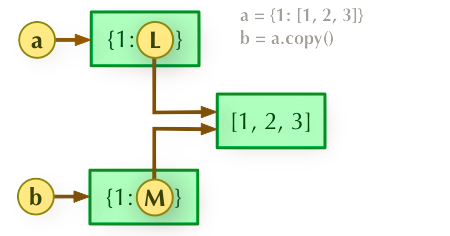
3、a = copy.deepcopy(b)深度拷贝
欢迎关注我的微信公众号
互联网矿工
