1.计算机系统
1.1 计算机系统漫游
1.1.1 编译系统
hello.c hello.i hello.s hello.o
-------->预处理器-------->编译器--------->汇编器------ .---------. hello
cpp ccl as '---> | 链接器 |--------->
.---> | ld |
| '---------'
printf.o
1.2 信息的表示和处理
1.3 程序的机器级表示
1.5 优化程序性能
-
GCC的优化等级?
-O0:关闭所有优化;
-O1:最基本的优化等级。
-O2:比
-O1更高等级的优化,也是推荐的优化等级,试图提高代码性能而不会增大体积和大量占用的编译时间。-O3:最高最危险的优化等级,会延长编译代码的时间,并且在使用
gcc4.x的系统里不应全局启用。-Os:用于优化代码尺寸,启用了-O2中不会增加磁盘空间占用的代码生成选项。
-
*xp=*yp *xp=yp能否优化为*xp=*yp能否优化为2* *yp?不能,因为
*xp和*yp可能指向同一个地址空间。
1.10 虚拟内存
-
虚拟内存的作用?
为了缓解内存空间不足的问题,拿出一部分硬盘空间来充当内存使用。
2. 计算机操作系统
2.1 知识点
-
操作系统演变过程中的批处理、多道程序、分时是如何提高效率的?
批处理:一次执行多个代码,这些代码的打印操作一块进行,减小打印时间,即提高CPU利用率。
多道程序:利用一段程序等待IO操作完成的时间,进行另外一段程序的执行,实现了CPU复用。
分时:通过定时中断,实现CPU分时复用。分时没有提升CPU利用率,甚至降低了CPU利用率,但是减小了小段(执行时间短)程序的执行等待时间,让用户体验到并行执行的感觉,而不是要等待前面的任务执行完毕。
-
物理地址、线性地址和逻辑地址的区别?
段机制启动、页机制未启动:逻辑地址 -> 段机制处理 -> 线性地址 = 物理地址 段机制和页机制都启动 :逻辑地址 -> 段机制处理 -> 线性地址 -> 页机制处理 -> 物理地址 -
计算机上电后具体的加载过程?
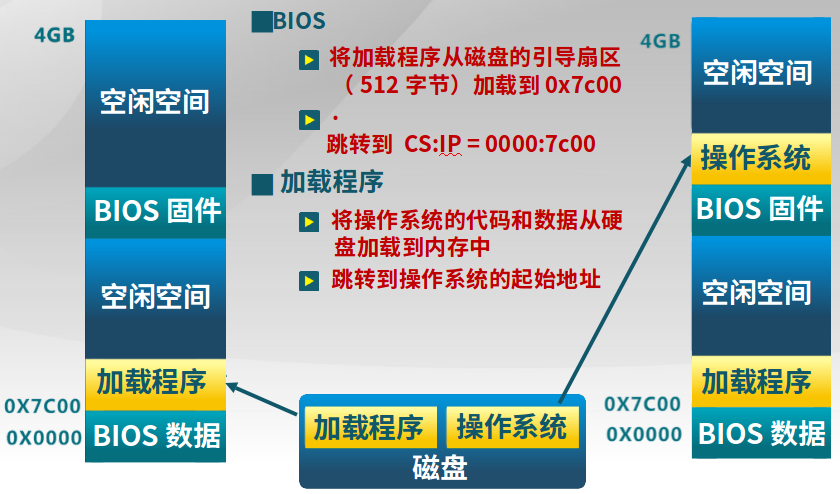
-
BIOS固件
1.将磁盘中的引导扇区(引导扇区的文件系统格式固定,使得BIOS认识)的加载程序加载到0x7c00
2.跳转到CS:IP = 0000:7c00
-
加载程序
3.将操作系统的代码和数据从硬盘(文件系统为加载程序认识)加载到内存
4.跳转到内存中的操作系统起始地址开始执行
-
-
为什么不是直接从文件系统中加载代码,还要一个加载程序?
磁盘文件系统多种多样,机器出厂时不可能在BIOS中加入认识所有文件系统的代码。加载程序存储在一个约定格式的文件系统中,BIOS可以没有障碍地读取加载程序。然后再通过加载程序从一定的文件系统中加载操作系统。
-
系统调用和函数调用的区别?
-
系统调用
INT和IRET(Int RETurn)指令用于系统调用。函数调用时,堆栈切换(内核态和用户态使用不同的堆栈)和特权级的转换。
-
函数调用
CALL和RET用于常规调用,没有堆栈切换。
-
-
段机制是什么?
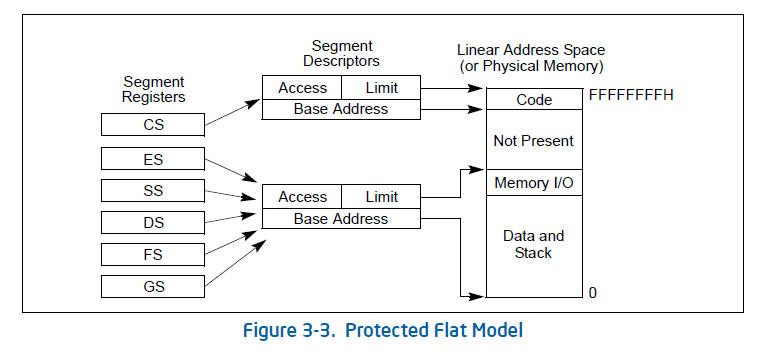
段寄存器(如CS)指向段描述符,段描述符中包含了起始地址和大小。
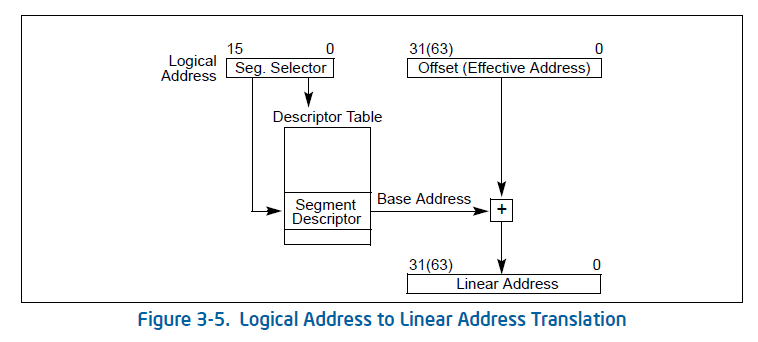
Offset(偏移量)是EIP,而段描述符中存放了起始地址Base Addr。Base Addr是由CS或者是其他段寄存器所指出来的基址。
Base Addr + Offset得到线性地址,如果没有启动页机制,则线性地址就是物理地址。 -
为什么要段机制?
以32位硬件为例,虽然任何一个寄存器都可以达到32位,但是但是为了安全起见,需要引入分段机制,通过段描述符(64位)的段物理首地址、段界限、段属性等描述来限制段的空间大小。
-
段式存储、页式存储和段页式的区别?
(1)段的大小可以不一样,用于存储属性、访问方式相同的数据;每个页的大小固定且一样,逻辑页可以放在任何一个物理块(逻辑页和物理块大小相同)中。
(2)段内存保护方面有优势,因为通过特段级来决定是否可以访问数据;页在内存利用和优化转移后备存储方面有优势。
(3)段空间更加大,而页很小,比如1K、nK等。
段页式结合了段式和页式,即段表指向一个页表,由页表来再次分割一个段。
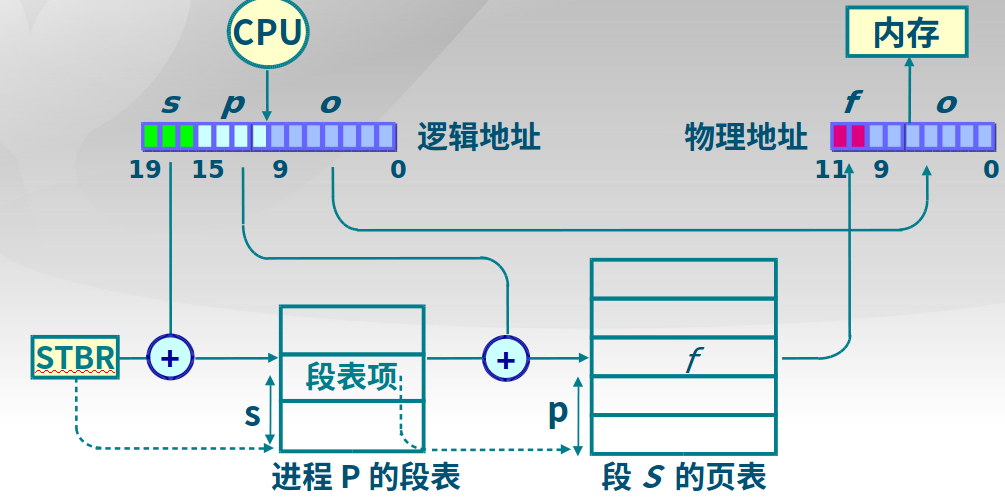
-
段机制如何实现内存访问安全?
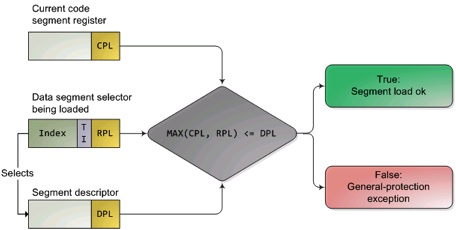
特权级数值越大,级别越低,图中MAX找出了CPL(当前活动代码段特权级,Current Privilege Level)和RPL(请求特权级,RPL保存在选择子的最低两位,Request Privilege Level)特权最低的一个,并与描述符特权级(描述符特权,描述对应段所属的特权等级,段本身能被访问的真正特权级,Descriptor Privilege Level)比较,优先级高于描述符特权级,则可以实现访问。
-
用户态如何访问内核态?
操作系统设置了访问门的时候,需要满足
CPL<=DPL[门] && CPL >= DPL[段]。也就是说当前运行的程序优先级CPL要高于访问的(陷阱、中断)门DPL[门],而要低于要访问的(数据)段的优先级DPL[段],因为内核态的数据段优先级确实要高。那么在运行时,CPL就可以通过陷阱门、中断门来访问优先级更高的内核态数据。 -
用户态和内核态切换的方式?
-
系统调用
用户态进程主动要求切换到内核态的一种方式,操作系统专门为用户开放了一个中断来实现
-
异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
-
外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
-
-
访问门和访问段时候的区别?
访问门:满足
CPL<=DPL[门] && CPL >= DPL[段],CPL >= DPL[段]使得低优先级程序可以访问高优先级段(比如内核态的数据)。访问段:
MAX(CPL, RPL) <= DPL -
C函数调用的实现过程(压栈和出栈)
以此函数为例:
... pushal ;保存当前函数的寄存器到堆栈 pushl %eax ;加法乘法指令的缺省寄存器 push1 %ebx ;在内存寻址时存放基地址 push1 %ecx ;是重复(REP)前缀指令和LOOP指令的内定计数器 call foo ;call的时候,会把要返回的执行(下一条指令:popl %ecx)的地址也压栈,在下面图中的Return Address popl %ecx popl %ebx pop1 %eax popal ;弹出寄存器 foo: pushl %ebp ;将上一个函数的EBP保存 mov %esp,%ebp ;将ESP保存到EBP,即本函数的EBP指向栈区域 ... popl %ebp ret ;将Return Address出栈,从Return Address继续执行
说明
-
X86的A20 Gate是什么?有什么作用?
寻址寄存器
segent:offset<(0xffff左移4位+0xffff)=1088KB,最多可访问1088KB空间,比1MB大了一些。为了保持向下兼容,需要设置第20位(A20)地址一直为0,这样才能实现不超过1MB。在进入保护模式后,需要使用这一位(A20),又要打开使能这一位。参考:http://hengch.blog.163.com/blog/static/107800672009013104623747/
-
.S(大写)和.s/asm文件的区别?.S(大写)文件还需要进行预处理、汇编操作形成.o文件,.asm/s文件只需要汇编形成.o文件。比如在ucore编译中,bootblock.S会生成bootblock.asm,再形成bootblock.o文件。
-
ebp = 10000,(uint32_t *) ebp + 1等于?(uint32_t *) ebp + 1 = 10004,(uint8_t *) ebp + 1 = 10001,(uint16_t *) ebp + 1 = 10002 -
中断服务函数的调用实现过程?
-
1.配置
在内核初始化的时候(ucore中是
kern/kern_init函数)要初始化中断描述符表(IDT)。 -
2.起始
从CPU收到中断事件后,打断当前程序或任务的执行,根据某种机制跳转到中断服务例程去执行的过程。
(1)CPU每次执行完一条指令,都会检查有无中断,如果有则会读取总线上的中断向量
(2)CPU根据得到的中断向量,到IDT中找到该中断向量的段选择子
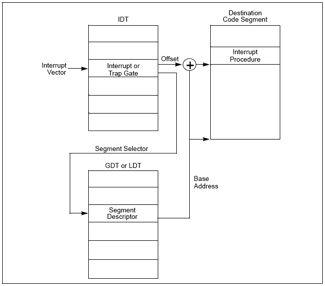
(3)根据段选择子和GDTR寄存器中保存的段描述符起始地址,找到了相应的段描述符中,保存了中断服务函数的段基址和属性信息,基地址加上IDT中的Offset就得到了中断服务函数的地址。以下是IDT找到相应中断服务程序的过程:
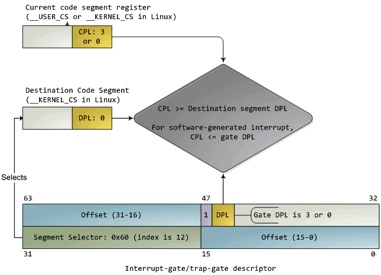
(4)CPU根据IDT的段选择子中的CPL和中断服务函数的GDT(段描述符)中的DPL确认是否发生了特权级的改变。比如当前程序处于用户态(ring3),而中断程序运行在内核态(ring0),意味着发生了特权级的转换。CPU会从当前的程序的TSS信息(该信息在内存中的起始地址存在TR寄存器中)里取得该程序的内核栈地址,即包括内核态的SS(堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值)和ESP寄存器(堆叠指标暂存器,存放栈的偏移地址,指向栈顶)。CPU切换到相应的内核栈。
(5)CPU保存被打断程序的现场(一些寄存器的值),比如用户态切换到了内核态,需要保存EFLAGS、CS、EIP、ERROR CODE(如果是有错误码的异常)信息
(6)CPU加载第一条指令
-
3.结束
每个中断服务例程在有中断处理工作完成后需要通过IRET(或IRETD)指令恢复被打断的程序的执行。
(1)IRET指令执行,从内核栈弹出先前保存的被打断的程序的现场信息,如EFLAGS、CS、EIP
(2)如果存在特权级转换(内核态到用户态),则还需要从内核栈弹出用户态栈的SS和ESP,回到用户态的栈
(3)如果此次处理的是带有错误码的异常,CPU恢复先前程序的现场时,不会弹出错误码。这一步需要软件完成,相应的中断服务函数在掉用IRET返回之前,添加出栈代码主动弹出错误码。
-
为什么栈的地址是从高到低的?

heap从低地址向高地址扩展,做内存管理相对要简单些。 stack从高地址向低地址扩展,这样栈空间的起始位置就能确定下来,动态的调整栈空间大小也不需要移动栈内的数据。
-
线程和进程的比较
- 进程是资源分配的单位,线程是CPU调度的单位,
线程 = 进程 - 共享资源 - 进程拥有一个完整的资源平台,而线程只独享指令流执行的必要资源,如寄存器和栈
- 线程具有就绪、等待和运行三种基本状态和状态间的转换关系
- 线程能减少并发执行的时间和空间开销
- 线程的创建时间比进程短
- 线程的终止时间比进程短
- 同一进程内的线程切换时间比进程切换时间短
- 由于同一进程的各线程间共享内存和文件资源,可不通过内核进行直接通信
- 进程是资源分配的单位,线程是CPU调度的单位,
-
-
进程控制块的组成和作用?
-
代码段、数据段、堆、堆栈、BSS段的区别?
代码段:存放代码的执行代码的一块内存区域
数据段:存放已经初始化的全局变量的一块内存区域
BSS段:存放程序未初始化的全局变量的一块内存区域
上述三个在加载ELF文件后,根据ELF文件就可以分配,下列堆、堆栈需要再次分配。
堆:存放动态分配的内存段,用malloc等函数分配,free等函数释放
堆栈:存放程序局部变量
2.2 Linux
-
nohup和&的区别?
nohup对SIGHUP(如关闭shell窗口)免疫,&对SIGINT(CTRL+c)免疫
3.计算机网络
3.1 概念
-
什么是CGI?
CGI脚本的工作:1.读取用户提交表单的信息;2.处理这些信息(也就是实现业务);3.输出,返回html响应(返回处理完的数据)
-
什么是RESTful?
REST = Representational State Transfer(表现层状态转化),资源(可以是网上的信息实体) 表现层(不同的信息可以通过不同形式表现,比如txt、json、xml) 状态转化(代表了客户端和服务器的一个互动过程,客户端通过HTTP实现获取GET、创建POST、修改PUT和删除DELETE资源)。HTTP是REST规则的一个实现实例。
-
什么是SOA?
SOA = Service-Oriented Architecture(面向服务的架构)即把系统按照实际业务,拆分成刚刚好大小的、合适的、独立部署的模块,每个模块之间相互独立。实际上SOA只是一种架构设计模式,而SOAP、REST、RPC就是根据这种设计模式构建出来的规范,其中SOAP通俗理解就是http+xml的形式,REST就是http+json的形式,RPC是基于socket的形式。
-
什么是RPC?
RPC = Remote Procedure Call Protocol(远程调用协议)通过网络从远程计算机程序上请求服务的协议,基于socket。相比较于REST(基于http,需要满足较多形式)速度更快。
-
什么是JMS?
JMS = Java Message Service(Java消息服务),应用程序接口是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。JMS它制定了在整个消息服务提供过程中的所有数据结构和交互流程。而MQ则是消息队列服务,是面向消息中间件(MOM)的最终实现,是真正的消息服务提供者。MQ的实现可以基于JMS,也可以基于其他规范或标准,其中ActiveMQ就是基于JMS规范实现的消息队列。
-
什么是IPC?
IPC = InterProcess Communication(进程间通信),不同进程之间传播或交换信息,通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等方式。
-
HTTP中GET和POST的区别?
- GET产生一个TCP数据包(http header和data一并发送出去,接受200 OK);POST产生两个TCP数据包(先发送header,接收100 continue,再发送data,接收200 OK)。
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
4.数据库
4.1 概念
- 什么是ORM?
ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术。
-
事务如何实现?

4.2 技术
-
典型时间序列数据库特点?
-
介绍几种时间序列数据库?
5.计算机应用
5.1 后端技术
5.1.1 大数据
-
大数据索引方式
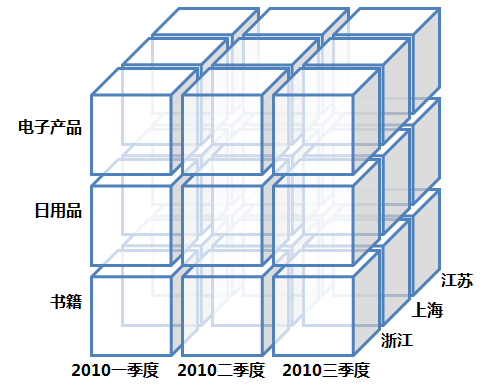
(1)数据立方体(Data Cube)
数据立方体只是多维模型的一个形象的说法,多维模型不仅限于三维模型。真正体现其在分析上的优势还需要基于模型的有效的操作和处理,也就是OLAP(On-line Analytical Processing,联机分析处理),包括钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)。
被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,是文档检索系统中最常用的数据结构。如
"a": {(2, 2), (3,5)}表示单词a在第2个文档的第2个单词和第3个文档的第5个单词出现,可以据诸多单词索引的集合,可以得到一句话的所在位置。 -
Spark如何选择存储级别?
- 如果你的RDD适合默认的存储级别(
MEMORY_ONLY),就选择默认的存储级别。因为这是cpu利用率最高的选项,会使RDD上的操作尽可能的快。 - 如果不适合用默认的级别,选择
MEMORY_ONLY_SER。选择一个更快的序列化库提高对象的空间使用率,但是仍能够相当快的访问。 - 除非函数计算RDD的花费较大或者它们需要过滤大量的数据,不要将RDD存储到磁盘上,否则,重复计算一个分区就会和重磁盘上读取数据一样慢。
- 如果你希望更快的错误恢复,可以利用重复(replicated)存储级别。所有的存储级别都可以通过重复计算丢失的数据来支持完整的容错,但是重复的数据能够使你在RDD上继续运行任务,而不需要重复计算丢失的数据。
- 在拥有大量内存的环境中或者多应用程序的环境中,
OFF_HEAP具有如下优势:- 它运行多个执行者共享Tachyon中相同的内存池
- 它显著地减少垃圾回收的花费
- 如果单个的执行者崩溃,缓存的数据不会丢失
Storage Level Meaning MEMORY_ONLY将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。 MEMORY_AND_DISK将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 MEMORY_ONLY_SER将RDD作为序列化的Java对象存储(每个分区一个byte数组)。这种方式比非序列化方式更节省空间,特别是用到快速的序列化工具时,但是会更耗费cpu资源—密集的读操作。 MEMORY_AND_DISK_SER和MEMORY_ONLY_SER类似,但不是在每次需要时重复计算这些不适合存储到内存中的分区,而是将这些分区存储到磁盘中。 DISK_ONLY仅仅将RDD分区存储到磁盘中 MEMORY_ONLY_2,MEMORY_AND_DISK_2, etc.和上面的存储级别类似,但是复制每个分区到集群的两个节点上面 OFF_HEAP(experimental)以序列化的格式存储RDD到Tachyon中。相对于MEMORY_ONLY_SER,OFF_HEAP减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中具有更强的吸引力。 - 如果你的RDD适合默认的存储级别(
5.1.2 中间件
5.1.2.1 Kafka
-
Kafka相比于传统MQ的优势?
可以扩展处理(一次处理分发给多个进程)并且允许多订阅者模式,不需要只选择其中一个,需要注意的是传统的MQ的队列方式只能被消费一次,故不能分发给多个订阅者;而发布订阅方式只能分发给多个订阅者,无法提前一步进行拓展处理。具体的实现方式是,通过类似出队列发送到消息组,而消息组进行拓展处理,再给组内的成员(进程)。
-
Kafka如何提高效率?
(1)解决大量的小型 I/O 操作问题(发生在客户端和服务端之间以及服务端自身的持久化操作中)
合理将消息分组,使得网络请求将多个消息打包成一组,而不是每次发送一条消息,从而使整组消息分担网络中往返的开销。
(2)字节拷贝性能限制
使用 producer ,broker 和 consumer 都共享的标准化的二进制消息格式,这样数据块不用修改就能在他们之间传递,sendfile允许操作系统将数据从pagecache直接发送到网络(零拷贝)。
(3)网络带宽限制
Kafka 以高效的批处理格式支持一批消息可以压缩在一起发送到服务器。这批消息将以压缩格式写入,并且在日志中保持压缩,只会在 consumer 消费时解压缩。
-
kafka的topic为何要进行分区(partition)?
为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。所以把topic内的数据分布到整个集群(topic内的多个partition分布在多个broker中)就是一个自然而然的设计方式。Partition的引入就是解决水平扩展问题的一个方案。
-
Kafka为何使用持久化?
(1)合理的设计方案可以大大提高持久化速度;
(2)Kafka建立在JVM之上,对象内存开销大,而且随着堆中数据的增加,Java垃圾回收变得越来越复杂和缓慢
(3)相比于维护尽可能多的 in-memory cache,并且在空间不足的时候匆忙将数据 flush 到文件系统,所有数据一开始就被写入到文件系统的持久化日志中,而不用在 cache 空间不足的时候 flush 到磁盘这一方案速度会更快,而且可以在下次启动时重新获取数据
-
Kafka的负载均衡措施?
Topic中的patition会将一个broker(一个服务器对应一个broker)作为leader,直接处理外部请求,而设置多个follwer备份此patition,实现容错。多个partition选择不同的broker作为leader,可以实现不同broker处理不同的请求。
补充:一个topic可以包括多个partition,而不同的partition存在于不同broker中,以实现并行,提高带宽。
-
Kafka的pull-based优势和劣势?
consumer获取数据的方式:consumer从broker处pull数据(pull-based,典型的案例包括Kafka);由broker将数据push到consumer(push-based,典型案例包括Scribe和Apache Flume)。
pull-based的优势包括(1)消费者消费速度低于producer的生产速度时,push-based系统的consumer会超载;而pull-based系统的consumer自行pull数据,在生产高峰期也可以保证不会超载,在生产低谷,可以将生产的数据慢慢pull和处理;(2)push-based必须立即发送数据,不知道下游consumer是否能够处理;pull-based可以大批量生产和发送给consumer。
pull-based的劣势包括(1)如果 broker 中没有数据,consumer 可能会在一个紧密的循环中结束轮询,实际上 busy-waiting 直到数据到来。
-
Kafka如何实现broker和consumer的数据一致性?
Kafka的 topic 被分割成了一组完全有序的 partition,其中每一个 partition 在任意给定的时间内只能被每个订阅了这个 topic 的 consumer 组中的一个 consumer 消费。这意味着 partition 中 每一个 consumer 的位置仅仅是一个数字,即下一条要消费的消息的offset。这使得被消费的消息的状态信息相当少,每个 partition 只需要一个数字。这个状态信息还可以作为周期性的 checkpoint。这以非常低的代价实现了和消息确认机制等同的效果。好处是,consumer 可以回退到之前的 offset 来再次消费之前的数据。
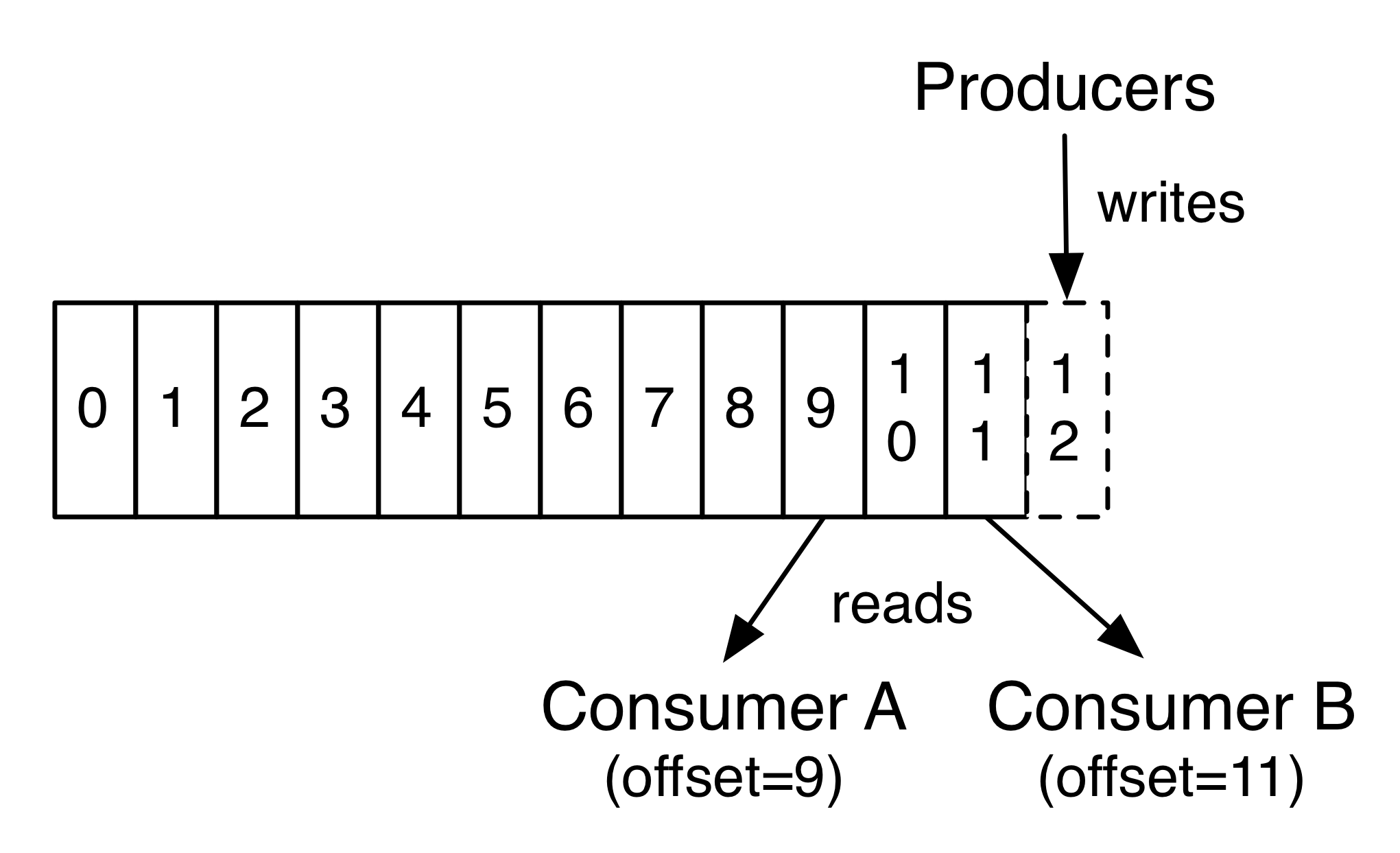
补充:确认机制——当消息被发送出去的时候,消息仅被标记为sent 而不是 consumed;然后 broker 会等待一个来自 consumer 的特定确认,再将消息标记为consumed。该方案的问题是,(1)如果 consumer 处理了消息但在发送确认之前出错了,那么该消息就会被消费两次;(2)关于性能,现在 broker 必须为每条消息保存多个状态(首先对其加锁,确保该消息只被发送一次,然后将其永久的标记为 consumed,以便将其移除)(3)如何处理已经发送但一直得不到确认的消息。
-
Kafka的producer、broker和consumer如何实现信息流流动?
producer通过主动push到broker中,而consumer通过主动pull从broker拉取数据。为什么采用push-based和pull-based见上方Kafka的pull-based优势和劣势?。
-
Kafka的producer的语义保证?
如果一个 producer 在试图发送消息的时候发生了网络故障, 则不确定网络错误发生在消息提交之前还是之后。 以下是处理方法:
0.11.0.0版本之前(at-least-once):如果 producer 没有收到表明消息已经被提交的响应,producer只能将消息重传。即提供了at-least-once的消息交付语义,因为如果最初的请求事实上执行成功了,那么重传过程中该消息就会被再次写入到 log 当中(导致了该消息的log可能会被写入多次)。
0.11.0.0版本及之后(at-least-once、at-most-once或者exactly-once):(1)Kafka producer新增幂等性,该选项保证重传不会在 log 中产生重复条目。为实现这个目的, broker 给每个 producer 都分配了一个 ID ,并且 producer 给每条被发送的消息分配了一个序列号来避免产生重复的消息。(2)producer新增了类似事务的语义将消息发送到多个topic partition,即要么所有的消息都被成功的写入到了 log,要么一个都没写进去,保证多个partition的消息相同。
-
Kafka如何保证producer将消息发送到多个partition中的语义保证?
producer新增了类似事务的语义将消息发送到多个topic partition,即要么所有的消息都被成功的写入到了 log,要么一个都没写进去,保证多个partition的消息相同。
-
交付语义包括哪些?
- At most once——消息可能会丢失但绝不重传。
- At least once——消息可以重传但绝不丢失。
- Exactly once——这正是人们想要的, 每一条消息只被传递一次.
-
Kafka的consumer如何实现以上三种交付语义?
-
at-most-once Consumer 可以先读取消息,然后将它的位置保存到 log 中,最后再对消息进行处理。在这种情况下,消费者进程可能会在保存其位置之后,带还没有保存消息处理的输出之前发生崩溃。而在这种情况下,即使在此位置之前的一些消息没有被处理,接管处理的进程将从保存的位置开始。在 consumer 发生故障的情况下,这对应于“at-most-once”(消息有可能丢失但绝不重传)的语义,可能会有消息得不到处理。
-
at-least-once Consumer 可以先读取消息,然后处理消息,最后再保存它的位置。在这种情况下,消费者进程可能会在处理了消息之后,但还没有保存位置之前发生崩溃。而在这种情况下,当新的进程接管后,它最初收到的一部分消息都已经被处理过了。在 consumer 发生故障的情况下,这对应于“at-least-once”(消息可以重传但绝不丢失。)的语义。 在许多应用场景中,消息都设有一个主键,所以更新操作是幂等的(相同的消息接收两次时,第二次写入会覆盖掉第一次写入的记录)。
-
exactly-once 从一个 kafka topic 中消费并输出到另一个 topic 时 (正如在一个Kafka Streams 应用中所做的那样),我们可以使用我们上文提到的0.11.0.0 及以后版本中的新事务型 producer,并将 consumer 的位置存储为一个 topic 中的消息,所以我们可以在输出 topic 接收已经被处理的数据的时候,在同一个事务中向 Kafka 写入 offset。此事务保证consumer接收消息、处理消息和offset写入均成功进行或者同时不成功。
因此,事实上 Kafka 在Kafka Streams中支持了exactly-once 的消息交付功能,并且在 topic 之间进行数据传递和处理时,通常使用事务型 producer/consumer 提供 exactly-once 的消息交付功能。 到其它目标系统的 exactly-once 的消息交付通常需要与该类系统协作,但 Kafka 提供了 offset,使得这种应用场景的实现变得可行。(详见 Kafka Connect)。否则,Kafka 默认保证 at-least-once 的消息交付, 并且 Kafka 允许用户通过禁用 producer 的重传功能和让 consumer 在处理一批消息之前提交 offset,来实现 at-most-once 的消息交付。
-
-
Kafka的容错性?
Kafka 允许 topic 的 partition 拥有若干副本,可以在server端配置partition 的副本数量。当集群中的节点出现故障时,能自动进行故障转移,保证数据的可用性。
-
Kafka如何判断节点是否存货alive?
1.节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接。 2.如果节点是个 follower ,它必须能及时的同步 leader 的写操作,并且延时不能太久。
满足这两个条件的节点处于 “in sync” 状态,区别于 “alive” 和 “failed” 。 Leader会追踪所有 “in sync” 的节点。如果有节点挂掉了, 或是写超时, 或是心跳超时, leader 就会把它从同步副本列表中移除。 同步超时和写超时的时间由 replica.lag.time.max.ms 配置确定。
-
Quorums(Kafka未使用)读写机制?
Quorums读写机制:如果选择写入时候需要保证一定数量的副本写入成功,读取时需要保证读取一定数量的副本,读取和写入之间有重叠。
实现Quorums的常见方法:对提交决策和 leader 选举使用多数投票机制。Kafka 没有采取这种方式。假设我们有2f + 1个副本,如果在 leader 宣布消息提交之前必须有f+1个副本收到 该消息,并且如果我们从这至少f+1个副本之中,有着最完整的日志记录的 follower 里来选择一个新的 leader,那么在故障次数少于f的情况下,选举出的 leader 保证具有所有提交的消息。这是因为在任意f+1个副本中,至少有一个副本一定包含 了所有提交的消息。该副本的日志将是最完整的,因此将被选为新的 leader。
多数投票的优点是,延迟是取决于最快的(f个,我的理解)服务器。也就是说,如果副本数是3,则备份完成的等待时间取决于最快的 Follwer 。除了Leader,还需要1个备份,最快的服务器响应后,即可满足f+1个副本有着完整的日志记录
多数投票缺点是,故障数f,则需要2f+1份数据(副本),对于处理海量数据问题不切实际。故常用于共享集群配置(如ZooKeeper),而不适用于原始数据存储
-
ISR模型和f+1个副本(Kafka使用)的机制?
Kafka 动态维护了一个同步状态的备份的集合 (a set of in-sync replicas), 简称 ISR ,在这个集合中的节点都是和 leader 保持高度一致的,只有这个集合的成员才 有资格被选举为 leader,一条消息必须被这个集合 所有 节点读取并追加到日志中了,这条消息才能视为提交。这个 ISR 集合发生变化会在 ZooKeeper 持久化,正因为如此,这个集合中的任何一个节点都有资格被选为 leader 。这对于 Kafka 使用模型中, 有很多分区和并确保主从关系是很重要的。因为 ISR 模型和 f+1 副本,一个 Kafka topic 冗余 f 个节点故障而不会丢失任何已经提交的消息。
-
如果 Kafka的备份都挂了怎么办?
两种实现方法:
- 等待一个 ISR 的副本重新恢复正常服务,并选择这个副本作为领 leader (它有极大可能拥有全部数据)。
- 选择第一个重新恢复正常服务的副本(不一定是 ISR 中的)作为leader。
如果我只等待 ISR 的备份节点,那么只要 ISR 备份节点都挂了,我们的服务将一直会不可用,如果它们的数据损坏了或者丢失了,那就会是长久的宕机。另一方面,如果不是 ISR 中的节点恢复服务并且我们允许它成为 leader , 那么它的数据就是可信的来源,即使它不能保证记录了每一个已经提交的消息。 kafka 默认选择第二种策略,当所有的 ISR 副本都挂掉时,会选择一个可能不同步的备份作为 leader ,可以配置属性 unclean.leader.election.enable 禁用此策略,那么就会使用第 一种策略即停机时间优于不同步。
-
Kafka在备份的可用性、持久性的权衡?
- 持久性优先 等待一个 ISR 的副本重新恢复正常服务,并选择这个副本作为领 leader (它有极大可能拥有全部数据)。
- 可用性优先 选择第一个重新恢复正常服务的副本(不一定是 ISR 中的)作为leader。
-
Kafka在备份的可用性、一致性的权衡?
指定最小的 ISR 集合大小,只有当 ISR 的大小大于最小值,分区才能接受写入操作,以防止仅写入单个(非常少的)备份的消息丢失造成消息不可用的情况。
- 可用性优先 减小最小的 ISR 集合大小,降低写入出错的可能,提高可用性
- 一致性优先 提高最小的 ISR 集合大小,保证将消息被写入了更多的备份,减少了消息丢失的可能性,提高一致性
-
Kafka应对broker级别故障?
选择一个 broker 作为 “controller”节点。controller 节点负责 检测 brokers 级别故障,并负责在 broker 故障的情况下更改这个故障 Broker 中的 partition 的 leadership 。这种方式可以批量的通知主从关系的变化,使得对于拥有大量partition 的broker ,选举过程的代价更低并且速度更快。如果 controller 节点挂了,其他 存活的 broker 都可能成为新的 controller 节点。
-
Kafka的资源限制?
Kafka broker可以对客户端做两种类型的资源配额限制:
- 定义字节率的阈值来限定网络带宽的配额。 (从 0.9 版本开始)
- request 请求率的配额,网络和 I/O线程 cpu利用率的百分比。 (从 0.11 版本开始)
且对于broker限制,而不是对客户端限制会更好,因为为每个客户端配置一个固定的集群带宽资源需要一个机制来共享client 在brokers上的配额使用情况。
-
Kafka的日志压缩及其优点?
Kafka的日志压缩是什么? 日志压缩可确保 Kafka 始终至少为单个 topic partition 的数据日志中的每个 message key 保留最新的已知值。
简单日志压缩和Kafka基于key日志压缩的优点:(1)基于时间的简单日志压缩——当旧的数据保留时间超过指定时间、日志大达到规定大小后就丢弃。这样的策略非常适用于处理那些暂存的数据,例如记录每条消息之间相互独立的日志。(2)Kafka基于key的日志压缩——日志压缩为我提供了更精细的保留机制,所以我们至少保留每个key的最后一次更新,而不会因为某一个key-value数据因为时间过长而删除。
-
Kafka如何实现日志压缩?
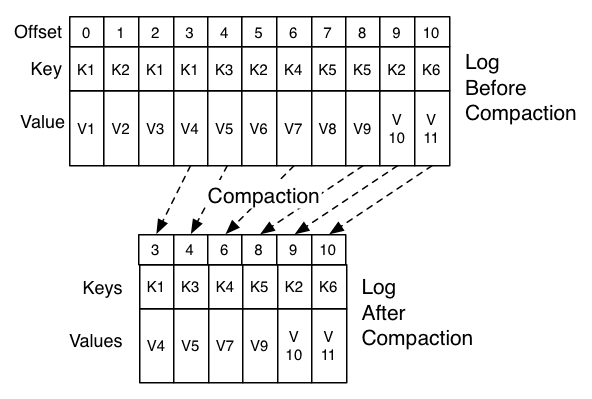
Log head中包含传统的Kafka日志,它包含了连续的offset和所有的消息。 日志压缩增加了处理tail Log的选项。 上图展示了日志压缩的的Log tail的情况。tail中的消息保存了初次写入时的offset。 即使该offset的消息被压缩,所有offset仍然在日志中是有效的。在这个场景中,无法区分和下一个出现的更高offset的位置。 如上面的例子中,36、37、38是属于相同位置的,从他们开始读取日志都将从38开始。
压缩也允许删除。通过消息的key和空负载(null payload)来标识该消息可从日志中删除。 这个删除标记将会引起所有之前拥有相同key的消息被移除(包括拥有key相同的新消息)。 但是删除标记比较特殊,它将在一定周期后被从日志中删除来释放空间。这个时间点被称为“delete retention point”。
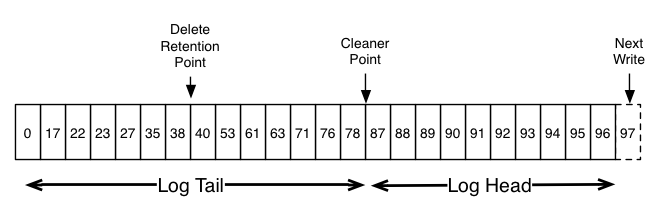
压缩操作通过在后台周期性的拷贝日志段来完成。 清除操作不会阻塞读取,并且可以被配置不超过一定IO吞吐来避免影响Producer和Consumer。实际的日志段压缩过程有点像这样:
-
Kafka实现数据中心备份?
Kafka附带了一个在Kafka集群之间镜像数据的工具 mirror-maker。该工具从源集群中消费数据并产生数据到目标集群。
-
Kafka安装bin目录下文件作用?
-
zookeeper-server-start.sh启动ZooKeeper服务器 -
kafka-server-start.sh启动Kafka服务器 -
kafka-topics.shtopic相关的命令:创建、查看等 -
bin/kafka-console-producer.shproducer相关命令 -
bin/kafka-console-consumer.shconsumer相关命令 -
kafka-reassign-partitions.sh分区(partition)重分配工具
-
-
Kafka如何管理offset?
Kafka提供了一个选项在指定的broker中来存储所有给定的consumer组的offset,称为
offset manager。可以通过手动实现管理offset,见OffsetCommitRequest 和 OffsetFetchRequest的源码
-
什么是Kafka的重平衡?
当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。重平衡是Kafka一个很重要的性质,这个性质保证了高可用和水平扩展。
-
Kafka中的broker、topic、partition的关系?
broker是一个节点,topic是一个定义主题,partition是一个topic可以分为多个partition(在不同的broker中),不同producer可以给一个topic的不同partition(也就是不同broker)生产消息。
-
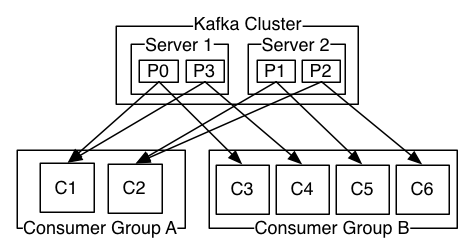
消费组的作用?
一个消费组内包含多个消费者,而订阅了一个topic后,topic内每个partition都会下发给订阅的消费组,组内只有一个消费者消费。一个消费者的多个消费者同时消费topic(的多个partition),提高带宽和处理能力。如下图为一个topic的P0-3,分别给不同的消费组发布消息,
-
Kafka vs Redis?
(1)redis是内存数据库,只是它的list数据类型刚好可以用作消息队列而已;
kafka是消息队列,消息的存储模型只是其中的一个环节,还提供了消息ACK和队列容量、消费速率等消息相关的功能,更加完善
(2)redis 发布订阅除了表示不同的 topic 外,并不支持分组;
kafka每个consumer属于一个特定的consumer group(default group), 同一topic的一条消息只能被同一个
consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
(3) 处理数据大小的级别不同,Redis更快,但是不如Kafka稳定。
-
发布订阅和生产消费的区别?
生产消费者模式,指的是由生产者将数据源源不断推送到消息中心,由不同的消费者从消息中心取出数据做自己的处理,在同一类别下,所有消费者拿到的都是同样的数据;订阅发布模式,本质上也是一种生产消费者模式。不同的是,由订阅者首先向消息中心指定自己对哪些数据感兴趣,发布者推送的数据经过消息中心后,每个订阅者拿到的仅仅是自己感兴趣的一组数据。这两种模式是使用消息中间件时最常用的,用于功能解耦和分布式系统间的消息通信。
5.1.2.2 MQ
-
为何使用MQ?
(1)实现异步处理提高系统性能(削峰、减少响应所需时间)
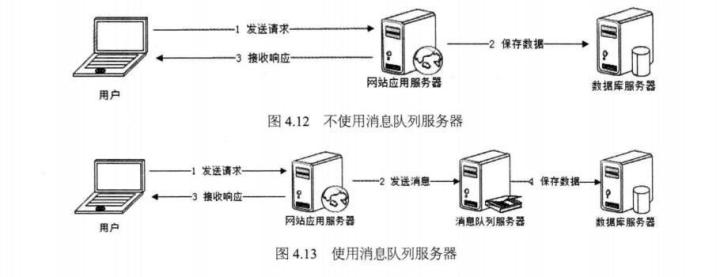
消息队列具有很好的削峰作用的功能——即通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。
(2)降低系统耦合性
事件驱动架构类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。
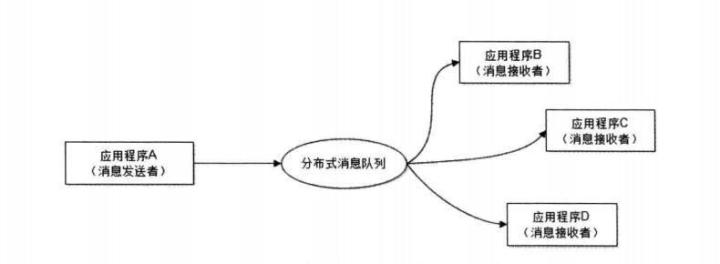
消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。
5.1.3 分布式
5.1.3.1 概念
-
对分布式算法的理解?
- ZooKeeper 的 Zab, Raft, 和 Viewstamped Replication
-
Kafka 的ISR模型(来自微软的PacificA)
-
Quorums
-
EJB是什么?
白话功能:编写的软件中那些需要执行制定的任务的类,不放到客户端软件上了,而是给他打成包放到一个服务器上,用C/S 形式的软件客户端对服务器上的”类”进行调用。
解释:EJB(Enterprise Java Beans) 是运行在独立服务器上的组件,客户端是通过网络对EJB 对象进行调用的。EJB以RMI技术(Remote Method Invocation,实现远程对象调用的技术)为基础。通过RMI 技术,J2EE将EJB 组件创建为远程对象,客户端就可以通过网络调用EJB 对象了。
补充1. 什么是RMI? RMI利用Java对象序列化的机制实现分布式计算,实现远程类对象的实例化和调用,即结合了对象序列化和分布式计算与RPC的概念。
补充2. 什么是对象序列化? 对象的序列化过程就是将对象状态转换成字节流和从字节流恢复对象。
补充3. 什么是分布式计算与PRC? RPC是”Remote Procedure Call”的缩写,即本地计算机调用远程计算机上的一个函数。
-
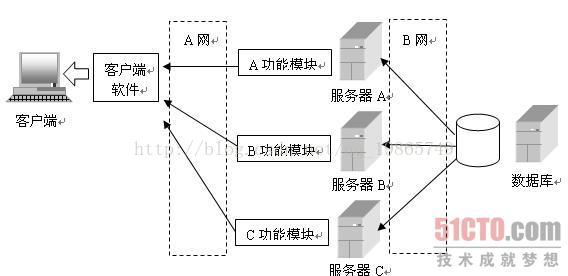
EJB中的“服务群集”是什么?
将原来在一个计算机上运算的几个类,分别放到其他计算机上去运行,以便分担运行这几个类所需要占用的CPU 和内存资源。同时,也可以将不同的软件功能模块放到不同的服务器上,当需要修改某些功能的时候直接修改这些服务器上的类就行了,修改以后所有客户端的软件都被修改了。
5.1.4 安全
5.1.4.1 概念
-
什么是token?
Token是访问资源的凭证,例如当调用Google API时,需要带上有效token(Google提供,第一次获取时需要登录)来表明请求的合法性。
补充:google token第一次获取过程
1.向Google API注册一个应用,注册完毕后会拿到认证信息(credentials)包括ID和secret,不是所有的程序类型都有secret。
2.向Google请求
access token,需要请求参数(上面申请到的secret)3.如果用户授权完毕,Google返回
access token和refresh token。一旦
access token过期,可以通过refresh token再次请求access token。 -
什么是OAuth?
-
什么是SSO?
单点登录(SSO, Single sign-on)即公司内部的公用的用户体系,用户只要登陆之后,就能够 访问所有的系统,如人力资源、代码管理、日志监控、预算申请。
5.1.4.2 技术
-
数字证书的实现原理?
-
MD5的实现原理?
-
client和password认证的区别?
- client模式,没有用户的概念,直接与认证服务器交互,用配置中的客户端信息去申请accessToken,客户端有自己的client_id,client_secret对应于用户的username,password,而客户端也拥有自己的authorities,当采取client模式认证时,对应的权限也就是客户端自己的authorities。
- password模式,自己本身有一套用户体系,在认证时需要带上自己的用户名和密码,以及客户端的client_id,client_secret。此时,accessToken所包含的权限是用户本身的权限,而不是客户端的权限。
5.1.5 Spring
5.1.5.2 概念
-
什么是IOC、DI
IOC是Inversion of Control,控制反转,是一种设计思想——IOC容器控制设计好的对象(控制),来为其他对象创建及注入依赖设计好的对象(反转)。为什么称为反转?因为其他对象只能被动接受设计好的对象。
DI是Dependency Injection,依赖注入——由容器动态的将某个依赖关系注入到组件之中。
-
IOC和DI的区别?
其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
5.1.5.2 注解
-
@Component、@Repository、@Service和@Controller的区别?
@Repository、@Service和@Controller是@Component(通用注解)的拓展,具有特定的功能。
注解 含义 @Component 最普通的组件,可以被注入到spring容器进行管理 @Repository 作用于持久层(DAL),具有将数据库操作抛出的异常翻译转化为spring的持久层异常的功能 @Service 作用于逻辑层,标注该类处于业务逻辑层 @Controller 作用于表现层,具有将请求进行转发,重定向的功能
5.1.5 其他后台技术
-
高并发保护系统的方式哪些?
- 缓存
- 降级
- 限流
-
限流算法?
-
计数器法
计数器实现每秒钟计数数据个数,如果超过最大处理能力,则限流
-
漏桶算法
一个固定容量的漏桶,按照常量固定速率流出水滴;如果桶是空的,则不需流出水滴;可以以任意速率流入水滴到漏桶;如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
-
令牌桶算法
令牌将按照固定的速率被放入令牌桶中。比如每秒放10个。 桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝。 当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上。 如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
Ngnix限制连接数和请求数。
-
5.2 前端技术
-
什么是V8引擎?
V8引擎是JS解析器之一,实现随用随解析。V8引擎为了提高解析性能,对热点代码做编译,非热点代码直接解析。先将JavaScript源代码转成抽象语法树,然后再将抽象语法树生成字节码。如果发现某个函数被多次调用或者是多次调用的循环体(热点代码),那就会将这部分的代码编译优化。
-
Node.js的来源?
V8引擎引入到了服务器端,在V8基础上加入了网络通信、IO、HTTP等服务器函数,形成了Node.js。Node.js是运行在服务器端的JS解析器。
5.3 代码规范
5.3.1 JUnit代码测试
-
JUnit如何运行一个测试类?
- 方法1,构建一个测试运行器,通过
JUnitCore.runClasses来运行测试类。
public class TestRunner { public static void main(String[] args) { Result result = JUnitCore.runClasses(TestEmployeeDetails.class); // do something }- 方法2,通过注解
- 方法1,构建一个测试运行器,通过
5.3.2 设计模式
-
如何实现观察者设计模式?
1.创建观察列表
2.主题的
notifyAllObserver()实现为列表中每个观察者发送改变后的状态信息3.主题的set方法(即改变某一个状态)中包括
notifyAllObserver()函数 -
你所使用过的设计模式?
http://neyzoter.cn/wiki/DesignPattern/
-
适配器、配置器和构造器的区别?
适配器(Adapter)模式也叫包装(Warpper)模式,将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
6.数据结构
6.1 树
-
红黑树是什么?
二叉查找树差多很多新节点,可能会造成不平衡, 进而会变成线性查找。红黑树可以解决该问题,其规则包括:
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。

如果不满足以上规则,则通过旋转和变色来调整。
-
红黑树调整的方法?
旋转和变色。
-
红黑树的应用?
1.Java8里头的HashMap在元素增长到一定程度时会从链表转成一颗红黑树,来减缓查找性能的下降。
2.TreeMap和TreeSet底层
-
B(B-)树?
- 根节点的关键字数量范围:
1 <= k <= m-1(m为B-树的阶数) - 非根节点的关键字数量范围:
m/2 <= k <= m-1 - 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
- 每个节点都存有索引和数据,也就是对应的key和value。
- 根节点的关键字数量范围:
-
B树和平衡二叉树的区别?
1.平衡二叉树节点最多有两个子树,而 B 树每个节点可以有多个子树,M 阶 B 树表示该树每个节点最多有 M 个子树 2.平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B 树每个中间节点有 k-1 个关键字(可以理解为数据)和 k 个子树( k 介于阶数 M 和 M/2 之间,M/2 向上取整) 3.B 树的所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
6.2 算法
-
分治法、动态规划法?
分治法是指将问题拆解为多个子问题,直到每个子问题都可以较为简单地解决。
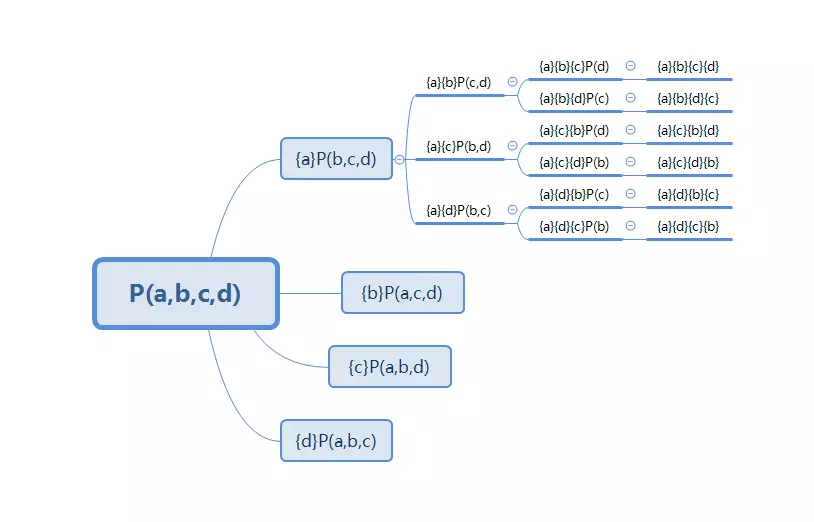
动态规划法实质是分治法以及解决冗余,将各个子问题的解保存下来。
7.JVM
7.1 概念
7.2 技术
-
单例模式中在类内定义自己的对象为什么不会循环?
final变量、static变量等线程共用的东西存放在JVM方法区,只加载一次,不会出现循环的问题。
8.计算机语言
8.1 Java
8.1.1 Java基础语法
-
Abstract的作用?
1.抽象方法具体实现在子类中。在父类中,抽象方法只包含一个方法名,没有方法体。子类必须重写父类的抽象方法,或者声明自身为抽象类。
2.抽象类,不能用来实例化对象, 声明抽象类的唯一目的时为了将来对该类进行扩充,具体实现由子类提供。任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。
-
Runnable和Thread的区别?
1.Thread类是专门负责描述线程本身的,Thread类可以对线程进行各种各样的操作。
2.自定义一个类来实现Runnable接口,这样就把任务抽取到Runnable接口中,在这个接口中定义线程 需要执行的任务的规则。
8.1.2 Java技术
-
Java父类和子类的转化原则
1.子类可以转化为父类,如Oringe(子类)可以转化为Fruit(父类);
2.父类转化为子类时,父类必须是某个子类的引用,如Frui引用Oringe,可以转化为Oringe,但不能转化为Apple。
-
Java是否可以在List中放同一父类的不同子类?
可以。实现方式为:
List<父类> list = .... list.add(子类)具体应用见观察者设计模式
-
both methods has the same erasure问题解释和解决?
public class FruitKata { class Fruit {} class Apple extends generic.Fruit {} public void eat(List fruitList) {} public void eat(List<Fruit> fruitList) { } // error, both methods has the same erasure }问题:由于Java的泛型擦除,在运行时,只有一个List类。
补充:Java的泛型是在Jdk 1.5 引入的,在此之前Jdk中的容器类等都是用Object来保证框架的灵活性,然后在读取时强转。但是这样做有个很大的问题,那就是类型不安全,编译器不能帮我们提前发现类型转换错误,会将这个风险带到运行时。引入泛型,也就是为解决类型不安全的问题(在创建对象时,确定范型的类型,进而保证类型安全),但是由于当时java已经被广泛使用,保证版本的向前兼容是必须的,所以为了兼容老版本jdk,泛型的设计者选择了基于擦除的实现。
解决:取不同名
-
范型的extends和super的区别

-
<? extends T>:是指 “上界通配符(Upper Bounds Wildcards)”(设置T为具体什么类型的时候)可以存放T类和T派生类(子类),但是(确定了T是具体什么类型后)存放的函数set()会失效,因为具体不知道T是什么类型。
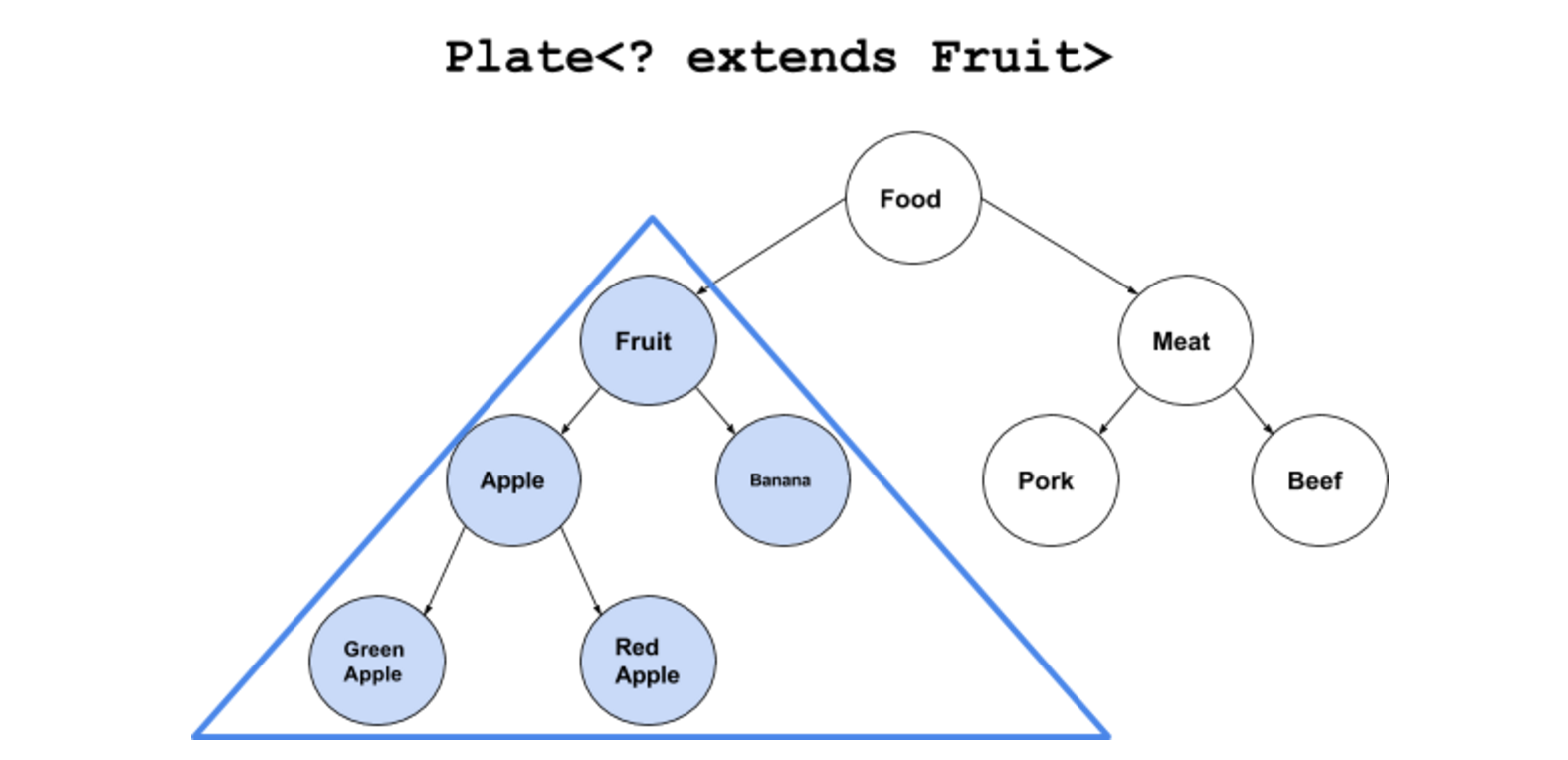
-
<? super T>:是指 “下界通配符(Lower Bounds Wildcards)”(设置T为具体什么类型的时候)可以存放T和T基类(父类),获取的函数get()失效,因为(确定了T是具体什么类型后)不知道T是什么类型,只有Object才能装下,会丢失信息。
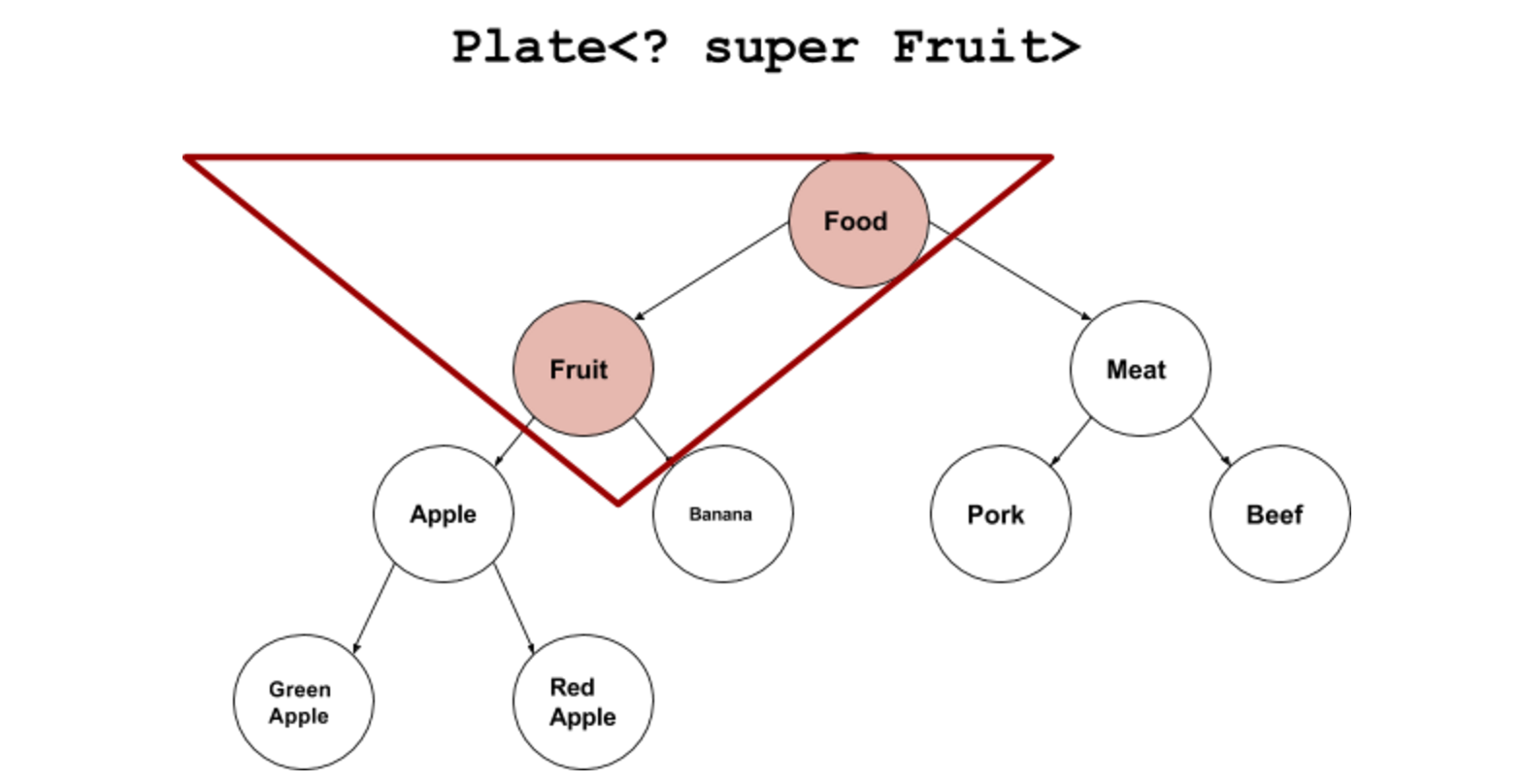
-
-
synchronized的几种用法?
注意:所有的非静态同步方法用的都是同一把锁——实例对象本身;所有的静态同步方法用的也是同一把锁——类对象本身
-
同步普通方法
/** * 用在普通方法,只针对单例(一个实例)有效,如果不是单例,锁会失效 */ private synchronized void synchronizedMethod() { System.out.println("synchronizedMethod"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } -
同步this实例(功能和同步普通方法一致)
/** * 用在this,锁住当前实例 */ private void synchronizedThis() { synchronized (this) { System.out.println("synchronizedThis"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } } -
同步静态方法
/** * 用在静态方法,对于所有的实例,只有一个线程能获取锁进入这个方法(锁住了类) */ private synchronized static void synchronizedStaticMethod() { System.out.println("synchronizedStaticMethod"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } -
同步类
/** * 用在类,其他类 */ private void synchronizedClass() { synchronized (TestSynchronized.class) { System.out.println("synchronizedClass"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } } /** * 用在类,自己这个类 */ private void synchronizedGetClass() { synchronized (this.getClass()) { System.out.println("synchronizedGetClass"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }
-
-
Java范型如何实现数据类型安全检查?
如何没有范型,则需要通过Object类来实现。如果传入了两个不同的对象,比如比较方法输入Integer对象和String对象,就无法比较,但是在编译的过程中是无法发现错误的。比如
-
Object实现范型
public class NoGeneric { private Object ob; public NoGeneric(Object ob) { this.ob = ob; } public Object getOb() { return this.ob; } public void setOb(Object ob) { this.ob = ob; } }NoGeneric intOb = new NoGeneric(new Integer(88)); NoGeneric strOb = new NoGeneric("123"); // 不会报错 if (intOb == strOb) { ... } -
Java范型
public class Generic<T> { private T ob; public Generic(T ob) { this.ob = ob; } public T getOb() { return this.ob; } public void setOb(T ob) { this.ob = ob; } }Generic<Integer> intOb = new Generic<>(new Integer(88)); Generic<String> strOb = new Generic<>("123"); // 报错,类型不同 if (intOb == strOb) { ... }
-
-
Java范型中的
?和T的区别(待补充)-
T可以确保多个参数类型的一致性,两个
?却不能// 参数中的两个T指向同一种数据类型 public <T extends Number> void test(List<T> dest, List<T> src) { } // 两个?所指数据类型可以不同 public void test(List<? extends Number> dest, List<? extends Number> src) { } -
T可以多重限定,也就是可以是多个类型的共同子类,
?不可以// T需要是Number和String的共同子类 public <T extends Number & String> void test(List<T> dest, List<T> src) { }
-
8.2 Python
8.3 Shell
欢迎关注我的微信公众号
互联网矿工
