1、Spark介绍
1.1 链接
1.2 介绍
Spark是个通用的集群计算框架,通过将大量数据集计算任务分配到多台计算机上,提供高效内存计算。如果你熟悉Hadoop,那么你知道分布式计算框架要解决两个问题:如何分发数据和如何分发计算。Hadoop使用HDFS来解决分布式数据问题,MapReduce计算范式提供有效的分布式计算。类似的,Spark拥有多种语言的函数式编程API,提供了除map和reduce之外更多的运算符,这些操作是通过一个称作弹性分布式数据集(resilient distributed datasets, RDDs)的分布式数据框架进行的。
核心组建
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。对熟悉Hive和HiveQL的人,Spark可以拿来就用。
- Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark,并在未来实现。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
2、Spark使用
2.1 基础
2.1.1 基础操作
-
运行例子
./bin/run-example SparkPi 10 -
启动shell
./bin/spark-shell -
为文件系统中的md文件创建一个新的RDD
scala> val textFile = sc.textFile("README.md") -
操作actions,从RDD返回值
scala> textFile.count() # RDD 的数据条数 res0: Long = 126 scala> textFile.first() # RDD 的第一行数据 res1: String = # Apache Spark -
转换transformations,变成一个新的RDD并返回它的引用
使用filter来查找包含Spark文本的新的RDD,返回引用
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) # 返回一个新的RDD保存了所有含有Spark文本 linesWithSpark: spark.RDD[String] = spark.FilteredRDD@7dd4af09 scala> linesWithSpark.count() # 计算个数 res2: Long = 20 -
映射map,将得到的结果映射到一个新的RDD
scala> var wordNum = textFile.map(line => line.split(" ").size) # 计算每一行的单词数目,用空格隔开 wordNum: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:25 -
reduce,找到单词数目最多的
scala> wordNum.reduce((a,b) => if (a > b) a else b) res3: Int = 22map和reduce的参数是 Scala 的函数串(闭包),并且可以使用任何语言特性或者 Scala/Java 类库。 -
scala调用Java函数库
scala> import java.lang.Math import java.lang.Math scala> wordNum.reduce((a,b) => Math.max(a,b)) res4: Int = 22 -
统计每个单词数量
# 每个单词都是以看看k-v格式:(word, 1) # 统计每个word的数目 scala> val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) # reduceByKey表示对同一种Key进行该操作 wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[5] at reduceByKey at <console>:26 # 显示收集单词的数量 wordCounts.collect() res7: Array[(String, Int)] = Array((package,1), (this,1), (integration,1), (Python,2), (page](http://spark.apache.org/documentation.html).,1), (cluster.,1), (its,1), ([run,1), (There,1), (general,3), (have,1), (pre-built,1), (Because,1), (YARN,,1), (locally,2), (changed,1), (locally.,1), (sc.parallelize(1,1), (only,1), (several,1), (This,2), (basic,1), (Configuration,1), (learning,,1), (documentation,3), (first,1), (graph,1), (Hive,2), (info,1), (["Specifying,1), ("yarn",1), ([params]`.,1), ([project,1), (prefer,1), (SparkPi,2), (<http://spark.apache.org/>,1), (engine,1), (version,1), (file,1), (documentation,,1), (MASTER,1), (example,3), (["Parallel,1), (are,1), (params,1), (scala>,1), (DataFrames,,1), (provides,1), (refer,2), (configure,1), (Interactive,2), (R,,1), (can,7), (build,4),... -
将数据集拉到集群内的内存缓存,重复访问时,提高访问速率
scala> linesWithSpark.cache() res8: linesWithSpark.type = MapPartitionsRDD[6] at filter at <console>:26 scala> linesWithSpark.count() res9: Long = 20
2.1.2 初始化Spark
// 设置Spark Context的信息
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
初始化Spark
- 创建一个SparkConf对象,作为下面的配置信息
- 创建一个SparkContext对象
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
appName 参数是你程序的名字,它会显示在 cluster UI 上。master 是 Spark, Mesos 或 YARN 集群的 URL,或运行在本地模式时,使用专用字符串 “local”。在实践中,当应用程序运行在一个集群上时,你并不想要把 master 硬编码到你的程序中,你可以用 spark-submit 启动你的应用程序的时候传递它。然而,你可以在本地测试和单元测试中使用 “local” 运行 Spark 进程。
使用shell
在 Spark shell 中,有一个专有的 SparkContext 已经为你创建好。在变量中叫做 sc。可以用 --master 参数来设置 SparkContext 要连接的集群,用 --jars 来设置需要添加到 classpath 中的 JAR 包,如果有多个 JAR 包使用逗号分割符连接它们。
# 在一个拥有4核的环境运行spark-shell
$ ./bin/spark-shell --master local[4]
# 将jar加入到classpath
$ ./bin/spark-shell --master local[4] --jars code.jar
2.1.3 弹性分布式数据集RDD
-
并行集合
var data = Array(1,2,3,4,5) var distData = sc.parallelize(data) // 并行集合并行集合一个很重要的参数是切片数(slices),表示一个数据集切分的份数。Spark 会在集群上为每一个切片运行一个任务。你可以在集群上为每个 CPU 设置 2-4 个切片(slices)。正常情况下,Spark 会试着基于你的集群状况自动地设置切片的数目。然而,你也可以通过
parallelize的第二个参数手动地设置(例如:sc.parallelize(data, 10))。 -
外部数据集
-
读取文件
所有spark基于文件的方式,包括textFile,能很好支持文件目录,压缩过的文件和通配符。
textFile("/my/文件目录"),textFile("/my/文件目录/*.txt")和textFile("/my/文件目录/*.gz")textFile第二个可选参数来控制切片(slices)的数目。默认情况下,Spark 为每一个文件块(HDFS 默认文件块大小是 64M)创建一个切片(slice)。但是你也可以通过一个更大的值来设置一个更高的切片数目。注意,你不能设置一个小于文件块数目的切片值。 -
其他数据格式
SparkContext.wholeTextFiles让你读取一个包含多个小文本文件的文件目录并且返回每一个(filename, content)对。与textFile的差异是:它记录的是每个文件中的每一行。对于 SequenceFiles,可以使用 SparkContext 的
sequenceFile[K, V]方法创建,K 和 V 分别对应的是 key 和 values 的类型。像 IntWritable 与 Text 一样,它们必须是 Hadoop 的 Writable 接口的子类。另外,对于几种通用的 Writables,Spark 允许你指定原声类型来替代。例如:sequenceFile[Int, String]将会自动读取 IntWritables 和 Text。RDD.saveAsObjectFile和SparkContext.objectFile支持保存一个RDD,保存格式是一个简单的 Java 对象序列化格式。这是一种效率不高的专有格式,如 Avro,它提供了简单的方法来保存任何一个 RDD。
-
-
RDD操作
-
基本
RDD支持2中类型操作:transformations和actions,transformation表示从一个数据源创建一个新的RDD,actions表示计算操作,并返回数值。map就是一个transformation,reduce是一个action。transformation是惰性的,只有action运行的时候才会进行计算。也就是说每次对一个RDD计算,都是需要先transformation,再进行action。如果为了提高action效率,可以将transformation后的RDD持久化到内存中。
// 创建一个RDD,因为惰性模式,没有立即计算,lines只是一个指向文件的指针 val lines = sc.textFile("data.txt") // map是一个transformation,因为惰性模式,没有立即计算 val lineLengths = lines.map(s => s.length) // reduce是一个action,spark将计算分成多个任务,并让他们运行在多个机器上 // 每台机器都运行自己的 map 部分和本地 reduce 部分。然后仅仅将结果返回给驱动程序。 val totalLength = lineLengths.reduce((a, b) => a + b)如果想要再次使用lineLengths,可以将其持久化到内存中,
val lines = sc.textFile("data.txt") val lineLengths = lines.map(s => s.length) lineLengths.persist()// 后面action时,会持久化到内存中 val totalLength = lineLengths.reduce((a, b) => a + b) -
传递函数到spark
object MyFunctions { def func1(s: String): String = { ... } } myRdd.map(MyFunctions.func1)如果要传递某一个对象中的方法,需要传递整个对象到集群。比如,
class MyClass { val field = "Hello" // 调用MyClass对象的doStuff方法时,需要将外部对象"Hello"引入 def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) } }为了避免这个问题,
class MyClass { val field = "Hello" // 调用MyClass对象的doStuff方法时,需要将外部对象"Hello"引入 def doStuff(rdd: RDD[String]): RDD[String] = { var field_ = this.field;//复制 field 到一个本地变量而不是从外部访问它 rdd.map(x => field + x) } } -
使用键值对
有一些操作(称为shuffle)只针对键值对
reduceByKey操作对每一种Key单独进行操作,最典型的是统计文本的个数。sortByKey操作将键值对按照字母排序。 -
一些transformation
-
一些Action
-
-
RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中。当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些 数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互使用来说,缓存是一个关键的工具。
你能通过
persist()或者cache()方法持久化一个rdd。首先,在action中计算得到rdd;然后,将其保存在每个节点的内存中。Spark的缓存是一个容错的技术-如果RDD的任何一个分区丢失,它 可以通过原有的转换(transformations)操作自动的重复计算并且创建出这个分区。此外,我们可以利用不同的存储级别存储每一个被持久化的RDD。例如,它允许我们持久化集合到磁盘上、将集合作为序列化的Java对象持久化到内存中、在节点间复制集合或者存储集合到 Tachyon中。我们可以通过传递一个
StorageLevel对象给persist()方法设置这些存储级别。cache()方法使用了默认的存储级别—StorageLevel.MEMORY_ONLY。可以利用不同的存储级别存储每一个被持久化的RDD。使用方法是通过给
persist()设置存储级别。Storage Level Meaning MEMORY_ONLY将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。 MEMORY_AND_DISK将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 MEMORY_ONLY_SER将RDD作为序列化的Java对象存储(每个分区一个byte数组)。这种方式比非序列化方式更节省空间,特别是用到快速的序列化工具时,但是会更耗费cpu资源—密集的读操作。 MEMORY_AND_DISK_SER和MEMORY_ONLY_SER类似,但不是在每次需要时重复计算这些不适合存储到内存中的分区,而是将这些分区存储到磁盘中。 DISK_ONLY仅仅将RDD分区存储到磁盘中 MEMORY_ONLY_2,MEMORY_AND_DISK_2, etc.和上面的存储级别类似,但是复制每个分区到集群的两个节点上面 OFF_HEAP(experimental)以序列化的格式存储RDD到Tachyon中。相对 于MEMORY_ONLY_SER,OFF_HEAP减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中具有更强的吸引力。删除内存中的数据
RDD.unpersist()方法如何选择存储级别?
- 如果你的RDD适合默认的存储级别(
MEMORY_ONLY),就选择默认的存储级别。因为这是cpu利用率最高的选项,会使RDD上的操作尽可能的快。 - 如果不适合用默认的级别,选择
MEMORY_ONLY_SER。选择一个更快的序列化库提高对象的空间使用率,但是仍能够相当快的访问。 - 除非函数计算RDD的花费较大或者它们需要过滤大量的数据,不要将RDD存储到磁盘上,否则,重复计算一个分区就会和重磁盘上读取数据一样慢。
- 如果你希望更快的错误恢复,可以利用重复(replicated)存储级别。所有的存储级别都可以通过重复计算丢失的数据来支持完整的容错,但是重复的数据能够使你在RDD上继续运行任务,而不需要重复计算丢失的数据。
- 在拥有大量内存的环境中或者多应用程序的环境中,
OFF_HEAP具有如下优势:- 它运行多个执行者共享Tachyon中相同的内存池
- 它显著地减少垃圾回收的花费
- 如果单个的执行者崩溃,缓存的数据不会丢失
- 如果你的RDD适合默认的存储级别(
2.1.4 共享变量
一般情况下,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量被复制到每台机器上,并且这些变量在远程机器上 的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
2.1.4.1 广播变量
广播变量允许程序员缓存一个只读的变量在每台机器上面,而不是每个任务保存一份拷贝。利用广播变量,我们能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。
// SparkContext.broadcast(v)方法从一个初始变量v中创建
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: spark.Broadcast[Array[Int]] = spark.Broadcast(b5c40191-a864-4c7d-b9bf-d87e1a4e787c)
// 广播变量是v的一个包装变量,它的值可以通过value方法访问
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
广播变量创建以后,我们就能够在集群的任何函数中使用它来代替变量v,这样我们就不需要再次传递变量v到每个节点上。另外,为了保证所有的节点得到广播变量具有相同的值,对象v不能在广播之后被修改。
2.1.4.2 累加器
累加器是一种只能通过关联操作进行“加”操作的变量,因此它能够高效的应用于并行操作中。
// 通过accumulator创建一个累加器
scala> val accum = sc.accumulator(0, "My Accumulator")
accum: spark.Accumulator[Int] = 0
// 并行计算
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Int = 10
开发者可以利用子类AccumulatorParam创建自己的 累加器类型。
2.1.5 RDD操作
RDDs支持2中类型的操作:转换(transformations)从已经存在的数据集中创建一个新的数据集;动作(actions) 在数据集上进行计算之后返回一个值到驱动程序。例如,map 是一个转换操作,它将每一个数据集元素传递给一个函数并且返回一个新的 RDD。另一方面,reduce 是一个动作,它使用相同的函数来聚合 RDD 的所有元素,并且将最终的结果返回到驱动程序(不过也有一个并行 reduceByKey 能返回一个分布式数据集)。
在 Spark 中,所有的转换(transformations)都是惰性(lazy)的,它们不会马上计算它们的结果。相反的,它们仅仅记录转换操作是应用到哪些基础数据集(例如一个文件)上的。转换仅仅在这个时候计算:当动作(action) 需要一个结果返回给驱动程序的时候。这个设计能够让 Spark 运行得更加高效。例如,我们可以实现:通过 map 创建一个新数据集在 reduce 中使用,并且仅仅返回 reduce 的结果给 driver,而不是整个大的映射过的数据集。
默认情况下,每一个转换过的 RDD 会在每次执行动作(action)的时候重新计算一次。然而,你也可以使用 persist (或 cache)方法持久化(persist)一个 RDD 到内存中。在这个情况下,Spark 会在集群上保存相关的元素,在你下次查询的时候会变得更快。在这里也同样支持持久化 RDD 到磁盘,或在多个节点间复制。
2.1.5.1 传递函数到Spark
-
使用匿名函数
-
全局单例对象的静态方法
举例如下,
object MyFunctions { def func1(s: String): String = { ... } } myRdd.map(MyFunctions.func1)在引用某个对象的值/方法时,需要同时引用整个对象,比如,
/***方法举例**/ // 如果map需要使用MyClass类的对象的方法doStuff,则会将整个对象都需要送到集群上 class MyClass { def func1(s: String): String = { ... } // 相当于def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(this.func1) } def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) } } /**数值举例**/ // map使用doStuff时,需要将整个对象送到集群 class MyClass { val field = "Hello" def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) } } // 将数值拷贝到局部变量可以实现只将函数送到集群比如 class MyClass { val field = "Hello" def doStuff(rdd: RDD[String]): RDD[String] = { val field_ = this.field rdd.map(x => field_ + x) } }
2.1.5.2 使用键值对
虽然很多 Spark 操作工作在包含任意类型对象的 RDDs 上的,但是少数几个特殊操作仅仅在键值(key-value)对 RDDs 上可用。最常见的是分布式 “shuffle” 操作,例如根据一个 key 对一组数据进行分组和聚合。
在 Scala 中,这些操作在包含二元组(Tuple2)(在语言的内建元组中,通过简单的写 (a, b) 创建) 的 RDD 上自动地变成可用的,只要在你的程序中导入 org.apache.spark.SparkContext._ 来启用 Spark 的隐式转换。在 PairRDDFunctions 的类里键值对操作是可以使用的,如果你导入隐式转换它会自动地包装成元组 RDD。
例如,下面的代码在键值对上使用 reduceByKey 操作来统计在一个文件里每一行文本内容出现的次数:
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
我们也可以使用 counts.sortByKey(),例如,将键值对按照字母进行排序,最后 counts.collect() 把它们作为一个对象数组带回到驱动程序。
注意:当使用一个自定义对象作为 key 在使用键值对操作的时候,你需要确保自定义 equals() 方法和 hashCode() 方法是匹配的。更加详细的内容,查看 Object.hashCode() 文档中的契约概述。
2.1.5.3 Transformations
常用的Transformations in gitbook。具体见RDD API 文档(Scala, Java, Python)和 PairRDDFunctions 文档(Scala, Java)
2.1.5.3 Actions
常用的Actions in gitbook。详细内容请参阅 RDD API 文档(Scala, Java, Python) 和 PairRDDFunctions 文档(Scala, Java)。
2.2 SQL
2.3 Spark Stream
具体见pdf
Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。
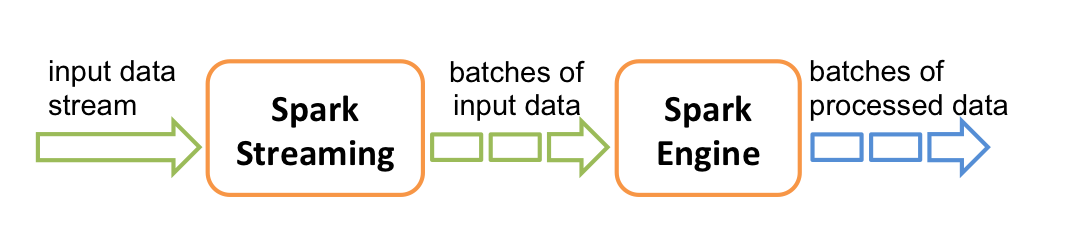
Spark Streaming支持一个高层的抽象,叫做离散流(discretized stream)或者DStream,它代表连续的数据流。DStream既可以利用从Kafka, Flume和Kinesis等源获取的输入数据流创建,也可以 在其他DStream的基础上通过高阶函数获得。在内部,DStream是由一系列RDDs组成。
Spark Stream可以输出到机器学习算法
2.3.1 快速例子
程序从监听TCP套接字的数据服务器获取文本数据,然后计算文本中包含的单词数。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working thread and batch interval of 1 second
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1)) // 每1秒钟处理一次
// 创建一个DStream
// 可以通过KafkaUtils.createDirectStream创建来自kafka的数据流
val lines = ssc.socketTextStream("localhost", 9999)
// 将单词分割出来
val words = lines.flatMap(_.split(" "))
import org.apache.spark.streaming.StreamingContext._
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
// 开始DStream
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
2.4 MLib
2.5 GraphX
3、Spark技术
3.1 Checkpoint机制
Checkpoint 是用来容错的,当错误发生的时候,可以迅速恢复的一种机制。
在SparkContext中需要调用setCheckpointDir方法,设置一个容错的文件系统的目录,比如HDFS。然后对RDD调用checkpoint方法,之后在RDD所处的job运行结束之后,会启动一个单独的job来将checkpoint过的RDD的数据写入之前设置的文件系统中。进行持久化操作。那么此时,即使在后面使用RDD的时候,他的持久化数据不小心丢失了,但是还是可以从它的checkpoint文件中读取出该数据,而无需重新计算。
3.2 弹性分布式数据集
RDD 是指能横跨集群所有节点进行并行计算的分区元素集合(Resilient Distributed Dataset,弹性分布式集合)。RDDs 从 Hadoop 的文件系统中的一个文件中创建而来(或其他 Hadoop 支持的文件系统),或者从一个已有的 Scala 集合转换得到。用户可以要求 Spark 将 RDD 持久化(persist)到内存中,来让它在并行计算中高效地重用。最后,RDDs 能在节点失败中自动地恢复过来。
RDD和持久化RDD的区别?
在 Spark 中,所有的转换(transformations)都是惰性(lazy)的,它们不会马上计算它们的结果。相反的,它们仅仅记录转换操作是应用到哪些基础数据集(例如一个文件)上的。转换仅仅在这个时候计算:当动作(action) 需要一个结果返回给驱动程序的时候。这个设计能够让 Spark 运行得更加高效。例如,我们可以实现:通过 map 创建一个新数据集在 reduce 中使用,并且仅仅返回 reduce 的结果给 driver,而不是整个大的映射过的数据集。默认情况下,每一个转换过的 RDD 会在每次执行动作(action)的时候重新计算一次。然而,你也可以使用 persist (或 cache)方法持久化(persist)一个 RDD 到内存中。在这个情况下,Spark 会在集群上保存相关的元素,在你下次查询的时候会变得更快。
3.3 共享变量
共享变量能被运行在并行计算中。默认情况下,当 Spark 运行一个并行函数时,这个并行函数会作为一个任务集在不同的节点上运行,它会把函数里使用的每个变量都复制搬运到每个任务中。有时,一个变量需要被共享到交叉任务中或驱动程序和任务之间。Spark支持两种共享变量:1.广播变量,用来所有节点的内存中缓存一个值;2.累加器(accumulators),仅仅只能执行“添加(added)”操作,例如:记数器(counters)和求和(sums)。
欢迎关注我的微信公众号
互联网矿工
