TDengine的架构、数据模型、存储引擎。
0.名词解释
-
超级表
表的模板。
1.架构
对云原生的支持是现有数据库的方向。在支持云原生的过程中,会将数据库的组建进行合理拆分,比如存算分离。TDengine引入了pnode、dnode、vnode、mnode等概念,将功能层层分离。
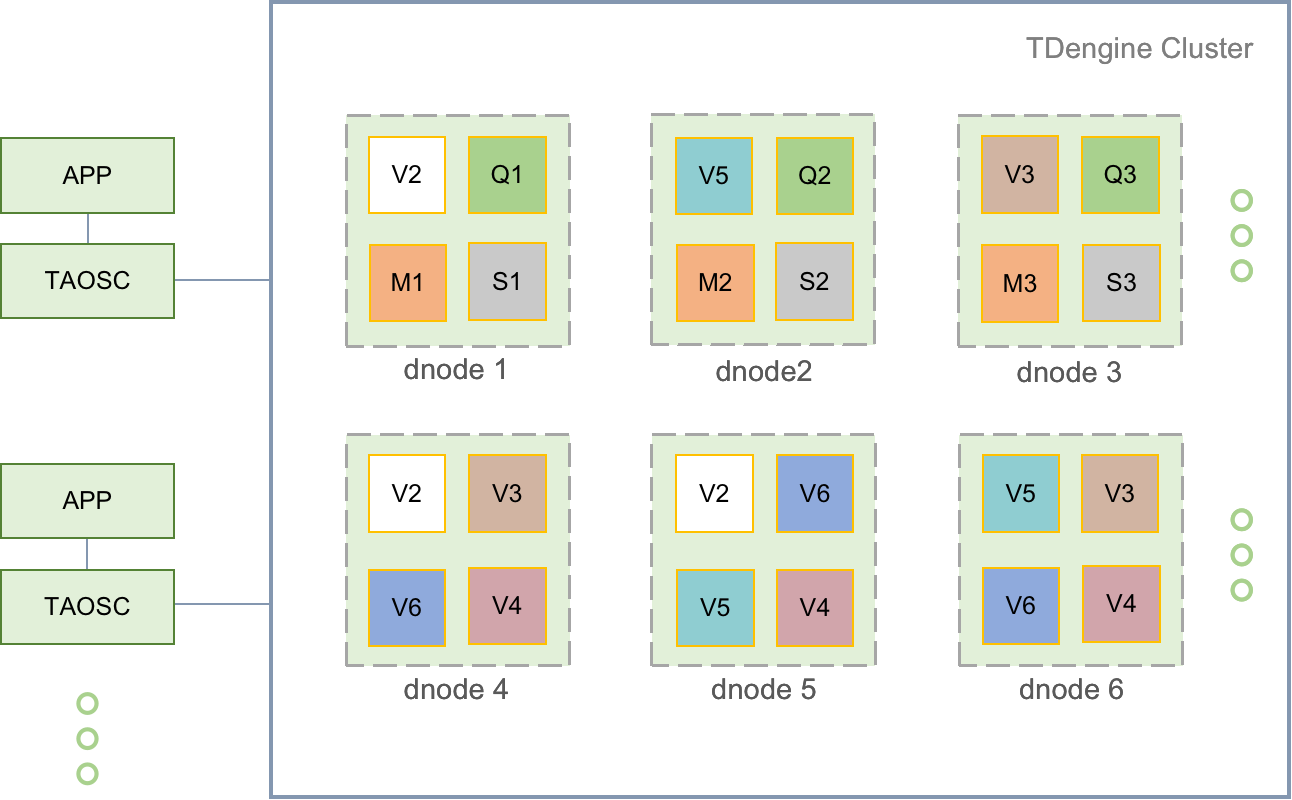
-
pnode
物理节点:物理机、虚拟机、容器等。
-
dnode
数据节点,包括>=0个vnode,0-1个mnode,0-1个qnode,0-1个snode。
标识=Endpoint(FDQN+PORT)。
-
vnode
虚拟节点,只属于一个DB,一个DB可以有多个vnode;用于支持数据分片、负载均衡,防止数据过热或倾斜。
图中dnode1、dnode4和dnode5中的3个V2(vnode)为一个VGroup,其中有1个Leader Vnode,2个Follower Vnode;VGroup会尽可能均衡分散在多个dnode上,比如V2在dnode1、dnode4和dnode5上,V6在dnode4、dnode5和dnode6上,V4在dnode4、dnode5和dnode6上….最终保持dnode1-dnode6的资源是平衡(多个数据库之间表的数量、写入频率、数据量等多个因素)的。
存储时序数据,表的schema、标签值等。
标识=Endpoint+VGroupID。
创建数据库的时候指定VGROUPS(VGroup个数),就会自动创建VGROUPS个vnode(后期通过hash一致性算法来分配数据)。vnode表现在文件系统中的一个个目录。
如果一个数据库有 N 个副本,那一个虚拟节点组就有 N 个虚拟节点,但是只有一个是 leader,其他都是 follower。当应用将新的记录写入系统时,只有 leader vnode 能接受写的请求。如果 follower vnode 收到写的请求,系统将通知 taosc 需要重新定向。
-
mnode
管理节点,负责所有数据节点运行状态的监控和维护,节点之间的负载均衡,元数据(包括用户、数据库、超级表等)的存储和管理;集群内mnode个数1-3个,包括一个leader node,数据更新操作只能在leader node上进行。
标识=Endpoint。
-
qnode
计算节点,虚拟的逻辑单元,运行查询计算任务,也包括基于系统表实现的show命令。在整个集群中共享使用,不和特定的db绑定,可以执行多个不同db的查询计算任务。每个dnode上最多一个qnode。
查询过程:客户端通过与 mnode 交互,获取可用的 qnode 列表,当没有可用的 qnode 时,计算任务在 vnode 中执行。当一个查询执行时,依赖执行计划,调度器会安排一个或多个 qnode 来一起执行。qnode 能从 vnode 获取数据,也可以将自己的计算结果发给其他 qnode 做进一步的处理。
通过引入独立的计算节点,TDengine 实现了存储和计算分离。
标识=Endpoint。
-
snode
流计算节点,只运行流计算任务,在整个集群内部共享使用;没有可用snode时,流计算任务在vnode中执行。
-
VGroup
虚拟节点组,如果两个vnode的VGroupID相同,则数据互为备份。
TDengine的架构后期还需要好好研究,先有个大致的了解。
2.数据模型
TDengine可以通过定义表来创建一些数据的集合,类似于IoTDB的实体。不同的是,TDengine没有定义实体的路径,而是一个TABLE。
TDengine支持通过定义超级表来实现快速创建表。用户可以在超级表定义列、标签名等信息。
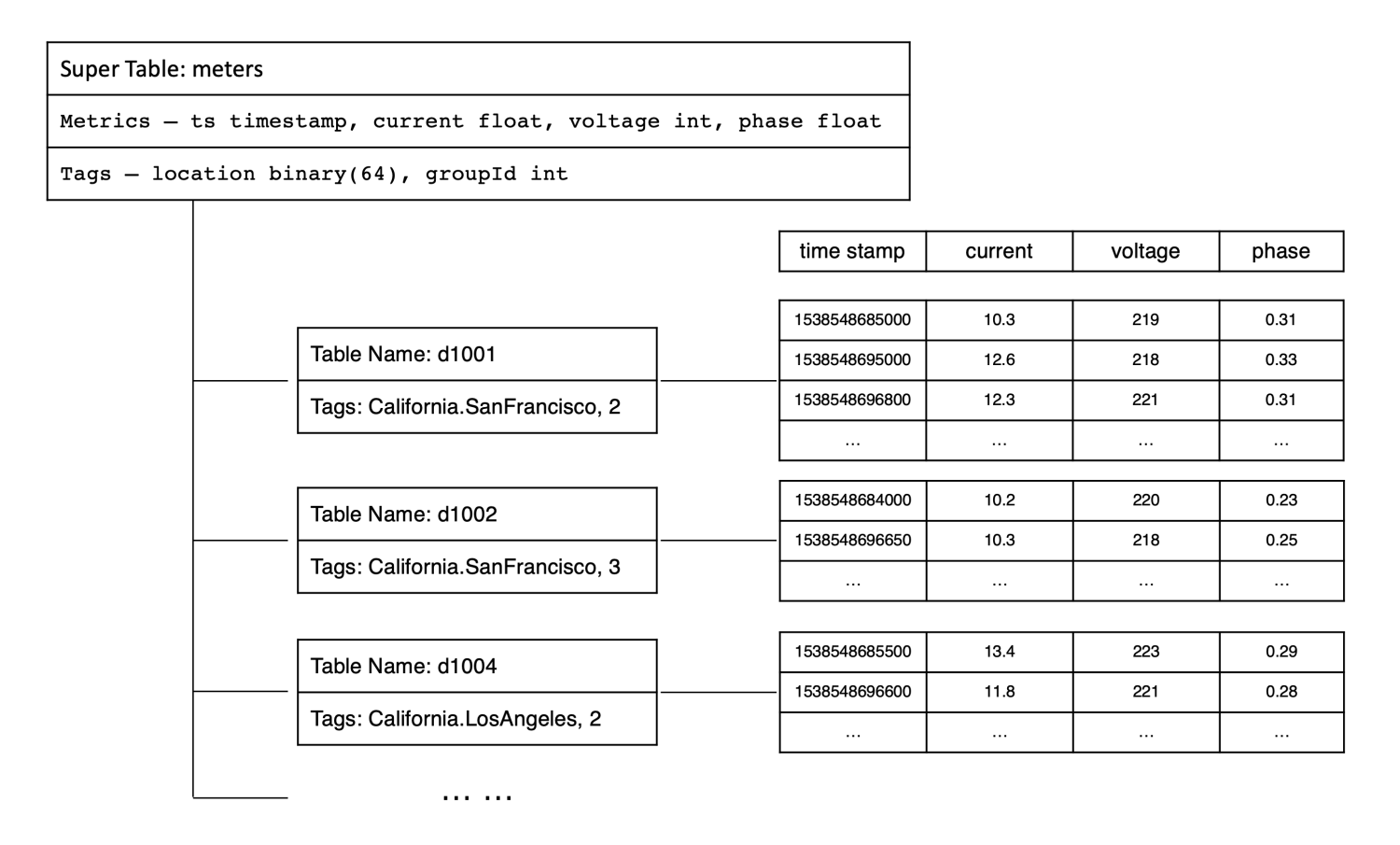
TDengine的标签不同于InfluxDB,不是时间线的标记,而是落在表上。在创建表的时候设定标签。这一点类似于IoTDB。在某种程度上阻止用户为标签设定变化的值,造成大量的时间线创建(InfluxDB)。
3.存储
下方是一个典型的数据文件存储结构。
.
├── dnode
│ └── dnode.json
├── mnode
│ ├── data
│ │ └── sdb.data // meta数据,见 dsbFile.C
│ ├── mnode.json
│ ├── sync
│ │ ├── raft_config.json
│ │ └── raft_store.json
│ ├── tmp
│ └── wal
│ ├── 00000000000000000000.idx
│ ├── 00000000000000000000.log
│ └── meta-ver0
└── vnode
├── vnode2
│ ├── meta
│ │ ├── invert
│ │ ├── main.tdb // tag索引;表名索引
│ │ └── main.tdb-journal // journal log,主要用于在修改main.tdb前备份,防止出现写入失败无法恢复的问题
│ ├── sync
│ │ ├── raft_config.json
│ │ └── raft_store.json
│ ├── tq
│ │ ├── main.tdb
│ │ └── stream
│ │ ├── checkpoints
│ │ ├── main.tdb
│ │ └── main.tdb-journal
│ ├── tsdb
│ │ ├── CURRENT
│ │ ├── v2f1736ver1.data // 时序数据,v{vnode_id}f{fid}ver{commitID}
│ │ ├── v2f1736ver1.sma // 聚合缓存数据
│ │ ├── v2f1736ver41.head // 时间主键索引,找表->找时间范围的数据块及位置
│ │ └── v2f1736ver41.stt // last文件,防止数据碎片化
│ ├── vnode.json
│ └── wal
│ ├── 00000000000000009845.idx
│ ├── 00000000000000009845.log
│ ├── 00000000000000009966.idx
│ ├── 00000000000000009966.log
│ └── meta-ver123
├── vnode3
│ ├── meta
│ │ ├── invert
│ │ ├── main.tdb
│ │ └── main.tdb-journal
│ ├── sync
│ │ ├── raft_config.json
│ │ └── raft_store.json
│ ├── tq
│ │ ├── main.tdb
│ │ └── stream
│ │ ├── checkpoints
│ │ ├── main.tdb
│ │ └── main.tdb-journal
│ ├── tsdb
│ │ ├── CURRENT
│ │ ├── v3f1736ver1.data // v{vgroup_id}f{fid}ver{commitID}
│ │ ├── v3f1736ver1.sma
│ │ ├── v3f1736ver41.head
│ │ └── v3f1736ver41.stt
│ ├── vnode.json
│ └── wal
│ ├── 00000000000000009837.idx
│ ├── 00000000000000009837.log
│ ├── 00000000000000009958.idx
│ ├── 00000000000000009958.log
│ └── meta-ver123
└── vnodes.json
mnode目录是mnode的相关信息,涉及到用户、数据库、超级表等。mnode在TDengine的早期还会有表的元数据。由于mnode的性能问题,已经被逐步剥离到vnode中。从文件名中也能看到TDengine通过RAFT协议来保证元信息在不同节点间的一致性。
vnode目录用于存储时序数据以及相关的元数据。下图是数据的存储层级:
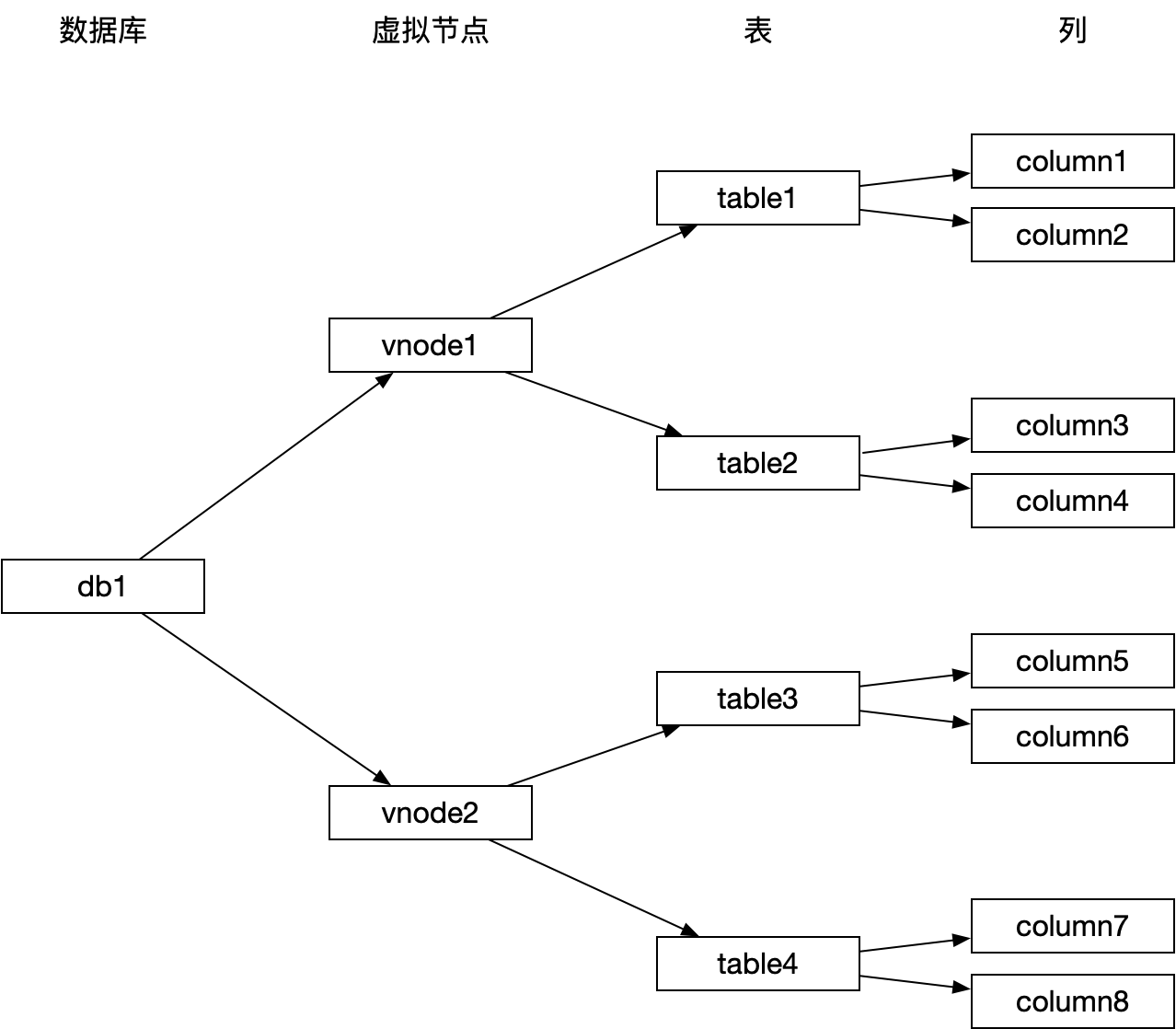
我们可以看到目录下有node{数字}这类目录名。在创建数据库的时候即可设定VGROUPS,也就是vnode组的个数。TDengine通过数字编号来区分不同的vnode。TDengine基于一致性Hash算法去分配数据。一致性Hash算法在集群增加节点时,能够使得数据尽可能少地搬迁。需要说明的是,目前没有看到TDengine创建数据库后更改VGROUPS的能力,也就是说一致性Hash“使得数据尽可能少地搬迁”的能力没有用到。一致性Hash在TDengine中只起到了Hash来对数据进行负载均衡的作用。
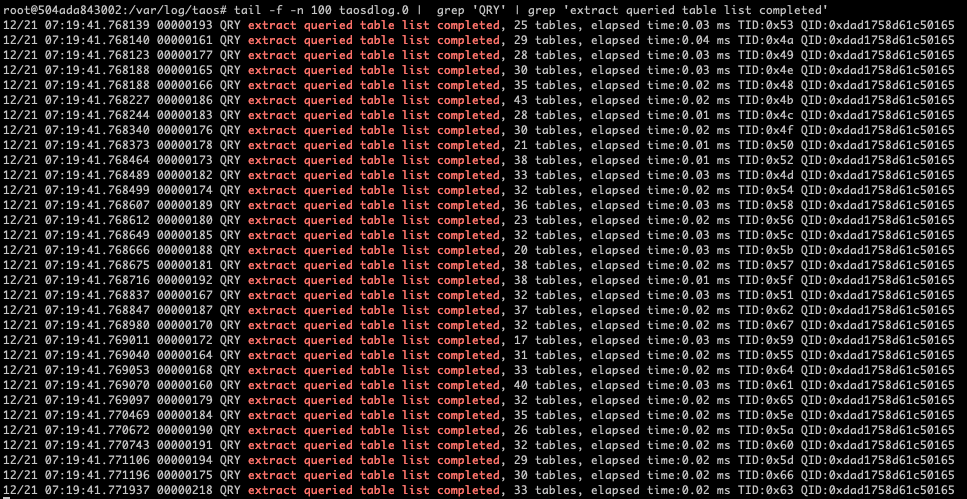
每个vnode下还有元数据meta、流式计算tq、时序数据tsdb、WAL 等信息。meta目录中有标签的索引。用户根据标签查询数据时,TDengine会先从每个vnode中搜索标签对应的表信息,再根据这些表信息来进行数据查询。下图是TDengine根据TAG查询表的日志,可以看到在每个vnode中都进行了查询:
select *,groupid,location from meters where groupid=9 order by ts desc limit 10;
tsdb目录是重头戏,包括.head、.data、.stt、.sma。.head文件是主索引文件。TDengine根据表名、时间等信息可以快速索引到.data文件的数据块。数据块索引中记录了数据块存放的文件、偏移、数据时间的范围,TDengine可以通过BRIN索引方式来查询数据。
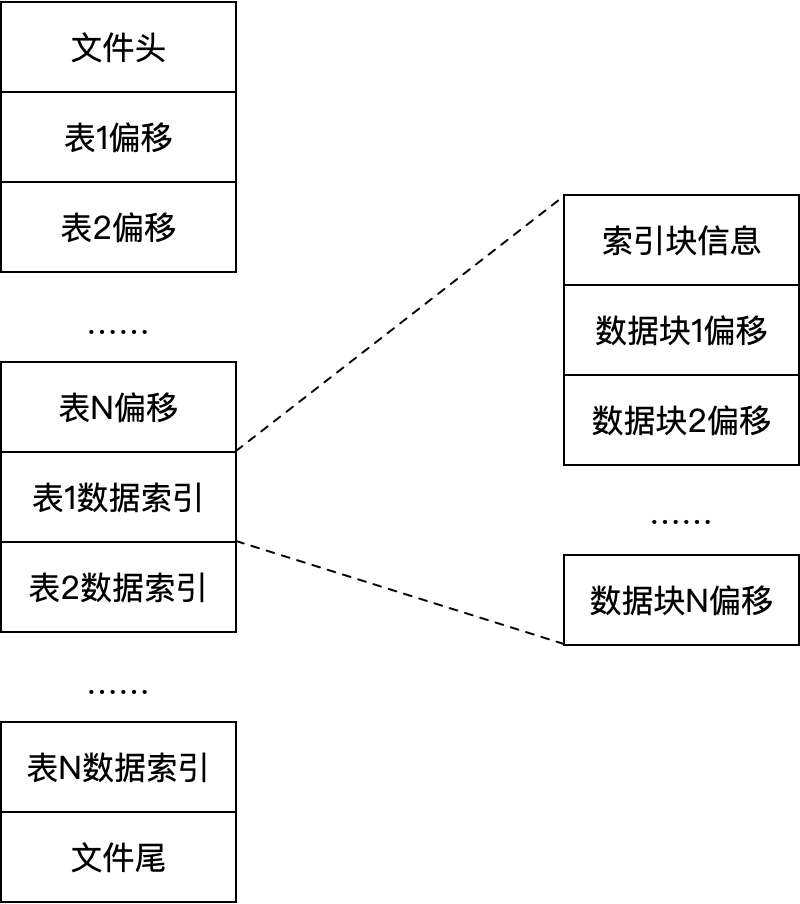
.data文件数据追加式写入(LSM树的理念)数据块。每个数据块只属于vnode的一张表。数据块的数据按照时间排列,同一列的数据存放在一起。数据块某一列信息中包括类型、压缩算法、列数据偏移、列数据长度。
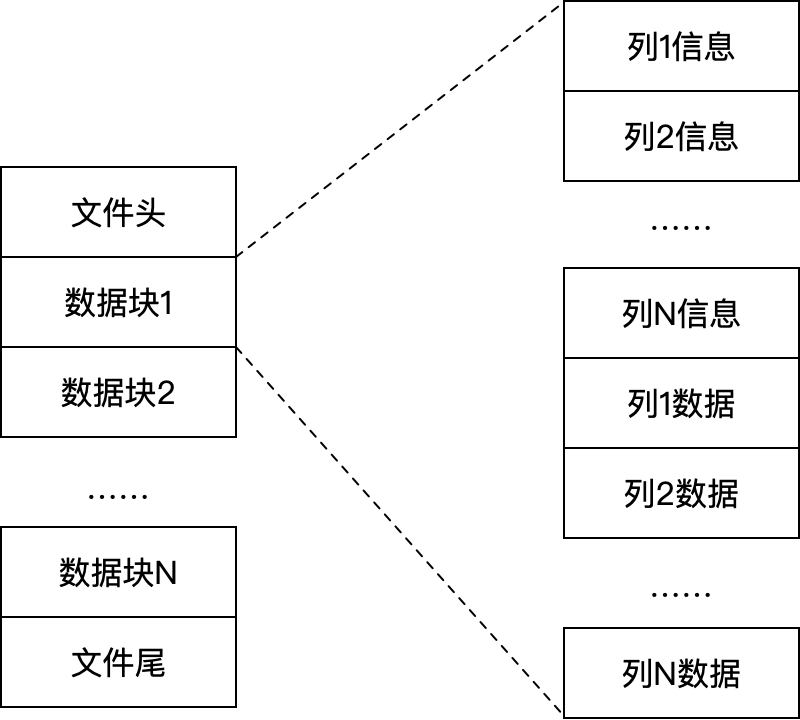
.stt文件也就是last文件,主要用于解决数据碎片化的问题。在多表低频场景下,产生数据落盘后,数据块内的列信息的数据少,压缩效果不好。为了解决这个问题,TDengine将同一个超级表下的列信息存放在一起,提高压缩率。在先前的文章“IoTDB技术内幕初探”中提到过这个问题。IoTDB没有last文件的概念,而是将数据一股脑追加进文件。IoTDB会通过不断合并文件来提高Page中数据的个数。
我认为在初期也会出现的,只是随着合并的不断发生,会大大减轻这种情况。如果时间分区的时间窗口越小,越可能出现这种问题。
为什么TDengine会出现这种问题呢?因为TDengine的存储层级是表(数据块)-列,索引单位是数据块;而IoTDB是实体(ChunkGroup,类似于表)-大时间线(Chunk)-小时间线(Page),索引单位是Chunk。从上边的结构来看,IoTDB更容易将时间相近的数据(其实是一条时间线)合并。而TDengine考虑到不同列(时间线)合并在一个数据块,所以就会造成不同时间线耦合在一起。有问题的话,请大家指正。
sma全称Small Materialized Aggregates。.sma文件保存了每个数据块的聚合结果(max/min/sum/count),方便快速查询。
4.演进与展望
TDengine有较多值得我们学习的地方,也有一些问题,值得我们去展望和改进。
值得我们学习的是:
-
对云原生的支持
提出了mnode、vnode、snode等组件模型。我现在不知道这块是否设计足够合理。后期也是我要进一步学习和深挖的地方。
-
表信息跟随vnode,而不是mnode
将压力分散到多个vnode中。
-
最新值缓存
-
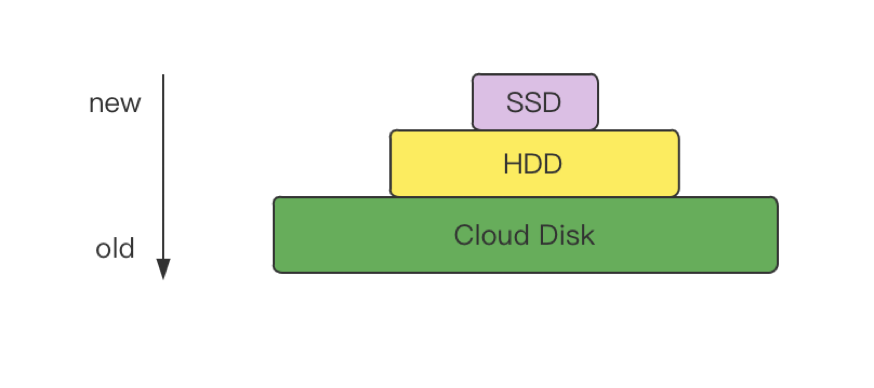
数据分级存储
将不同时间段的数据存储在挂载的不同介质的目录里,从而实现不同“热度”的数据存储在不同的存储介质上,充分利用存储。
-
基于WAL的订阅服务
利用WAL的时间有序特性,又提供了数据订阅这一刚需
-
高基数问题(时间线膨胀)的解决方法
- 将表分布到vnode中,实现负载均衡
- 元数据和时序数据分离,减少重复存储
- 在vnode中存储表的元数据
-
代码
-
对信号的处理
忽略SIGPIPE,防止进程被结束
其他的信号处理,可以看dmSetSignalHandler(v3版本)函数
-
有意义的参数不要占用默认值
比如字符串的空、整数类型的0都不要作为枚举类型的有意义的值,否则可能造成无法区分未配置和有意义的设置
-
通过commitID(Version)来区分同一个数据点的先后顺序
可用于处理数据的删除、更新等操作
-
展望和改进:
- 同一个表的不同列存放在一个数据块,不灵活
- 模板不支持绑定、解绑,不灵活
- 数据存储时间为数据库级别
5.参考
欢迎关注我的微信公众号
互联网矿工
